Tango: distributed data structures over a shared log Mahesh









15 Slides629.92 KB
Tango: distributed data structures over a shared log Mahesh Balakrishnan, Dahlia Malkhi, Ted Wobber, Ming Wu, Vijayan Prabhakaran Michael Wei, John D. Davis, Sriram Rao, Tao Zou, Aviad Zuck Microsoft Research
big metadata design pattern: distribute data, centralize metadata schedulers, allocators, coordinators, namespaces, indices (e.g. HDFS namenode, SDN controller ) usual plan: harden centralized service later “Coordinator failures will be handled safely using the ZooKeeper service [14].” Fast Crash Recovery in RAMCloud, Ongaro et al., SOSP 2011. “Efforts are also underway to address high availability of a YARN cluster by having passive/active failover of RM to a standby node.” Apache Hadoop YARN: Yet Another Resource Negotiator, Vavilapalli et al., SOCC 2013. “However, adequate resilience can be achieved by applying standard replication techniques to the decision element.” NOX: Towards an Operating System for Networks, Gude et al., Sigcomm CCR 2008. but hardening is difficult!
the abstraction gap for metadata centralized metadata services are built using in-memory data structures (e.g. Java / C# Collections) - state resides in maps, trees, queues, counters, graphs - transactional access to data structures - example: a scheduler atomically moves a node from a free list to an allocation map adding high availability requires different abstractions - move state to external service like ZooKeeper - restructure code to use state machine replication - implement custom replication protocols
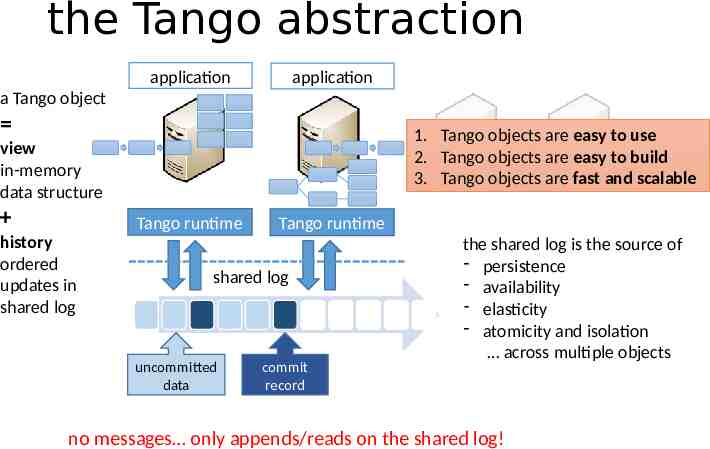
the Tango abstraction application application a Tango object 1. Tango objects are easy to use 2. Tango objects are easy to build 3. Tango objects are fast and scalable view in-memory data structure Tango runtime history ordered updates in shared log Tango runtime shared log uncommitted data commit record the shared log is the source of - persistence - availability - elasticity - atomicity and isolation across multiple objects no messages only appends/reads on the shared log!
Tango objects are easy to use implement standard interfaces (Java/C# Collections) linearizability for single operations under the hood: example: curowner ownermap.get(“ledger”); if(curowner.equals(myname)) ledger.add(item);
Tango objects are easy to use implement standard interfaces (Java/C# Collections) linearizability for single operations TX commits if readunder the hood: serializable transactions set (ownermap) has not changed in conflict window example: TR.BeginTX(); curowner ownermap.get(“ledger”); if(curowner.equals(myname)) ledger.add(item); status TR.EndTX(); speculative commit records: each client decides if the TX commits or aborts independently but deterministically [similar to Hyder (Bernstein et al., CIDR 2011)] TX commit record: read-set: (ownermap, ver:2) write-set: (ledger, ver:6)
Tango objects are easy to build 15 LOC persistent, highly available, transactional register class TangoRegister { int oid; object-specific state TangoRuntime T; int state; invoked by Tango runtime void apply(void X) { on EndTX to change state state (int )X; } mutator: updates TX void writeRegister (int newstate) { write-set, appends T update helper(&newstate , sizeof (int) , oid); to shared log } int readRegister () { T query helper(oid); accessor: updates return state; Other examples: TX read-set, } Java ConcurrentMap: 350 LOC returns local state } Apache ZooKeeper: 1000 LOC Apache BookKeeper: 300 LOC simple API exposed by runtime to object: 1 upcall two helper methods arbitrary API exposed by object to application: mutators and accessors
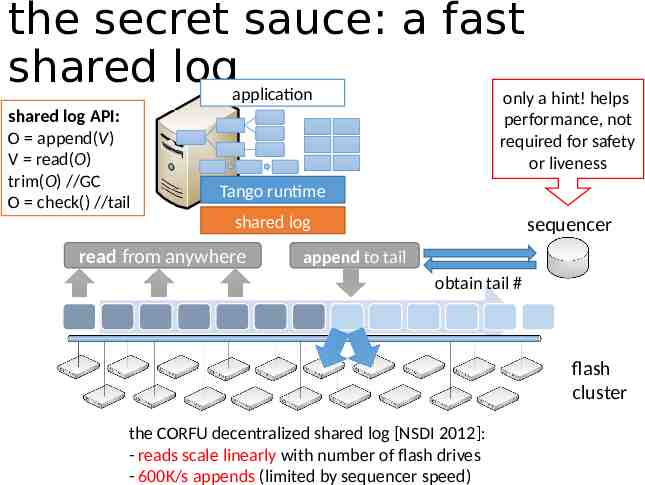
the secret sauce: a fast shared logapplication only a hint! helps shared log API: O append(V) V read(O) trim(O) //GC O check() //tail performance, not required for safety or liveness Tango runtime shared log read from anywhere sequencer append to tail obtain tail # flash cluster the CORFU decentralized shared log [NSDI 2012]: - reads scale linearly with number of flash drives - 600K/s appends (limited by sequencer speed)
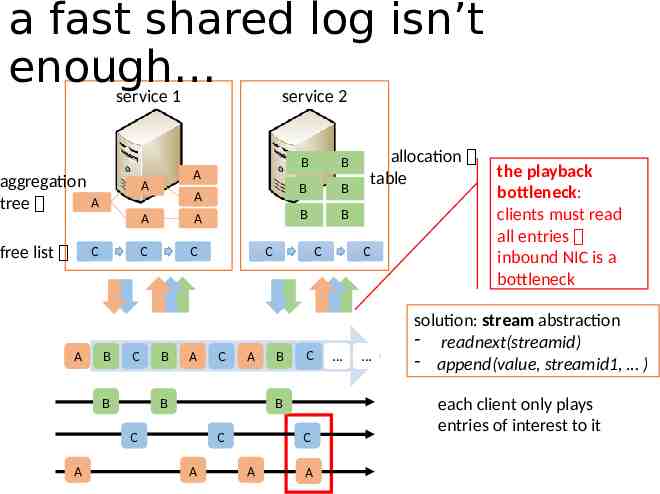
a fast shared log isn’t enough service 1 service 2 aggregation A tree A free list C A A C A A B C B A C B A B B B B B C C A B C B C CA B C A B C A C A A allocation table C the playback bottleneck: clients must read all entries inbound NIC is a bottleneck solution: stream abstraction - readnext(streamid) - append(value, streamid1, ) each client only plays entries of interest to it
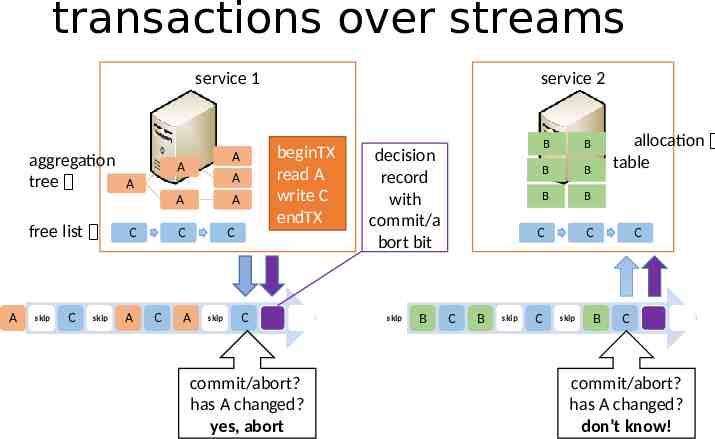
transactions over streams service 1 aggregation tree A A A free list A skip C skip C A A C C beginTX read A write C endTX A A C A skip service 2 C commit/abort? has A changed? yes, abort decision record with commit/a bort bit skip B B B B B B B C C B skip C allocation table C skip B C C commit/abort? has A changed? don’t know!
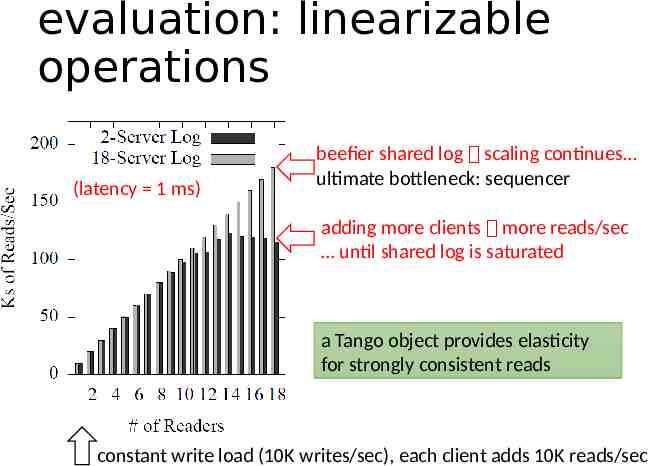
evaluation: linearizable operations (latency 1 ms) beefier shared log scaling continues ultimate bottleneck: sequencer adding more clients more reads/sec until shared log is saturated a Tango object provides elasticity for strongly consistent reads constant write load (10K writes/sec), each client adds 10K reads/sec
evaluation: single object txes beefier shared log scaling continues ultimate bottleneck: sequencer adding more clients more transactions until shared log is saturated scales like conventional partitioning but there’s a cap on aggregate throughput each client does transactions over its own TangoMap
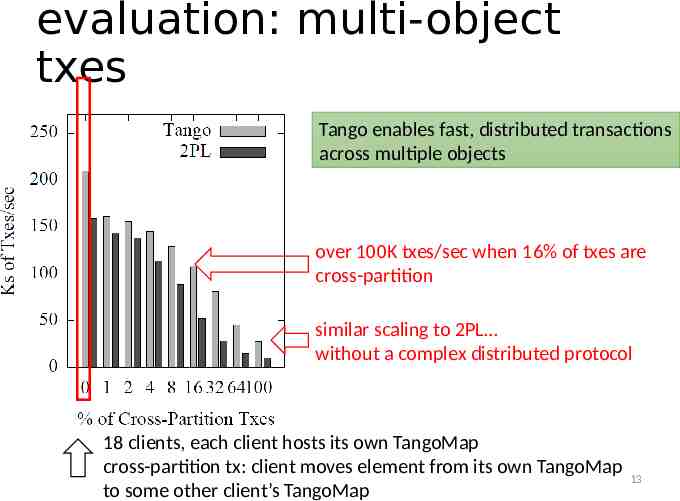
evaluation: multi-object txes Tango enables fast, distributed transactions across multiple objects over 100K txes/sec when 16% of txes are cross-partition similar scaling to 2PL without a complex distributed protocol 18 clients, each client hosts its own TangoMap cross-partition tx: client moves element from its own TangoMap to some other client’s TangoMap 13
conclusion Tango objects: data structures backed by a shared log key idea: the shared log does all the heavy lifting (persistence, consistency, atomicity, isolation, history, elasticity ) Tango objects are easy to use, easy to build, and fast! Tango democratizes the construction of highly available metadata services
thank you!






