Partitioning








24 Slides556.26 KB
Partitioning
Partitioning Leveraging Azure Cosmos DB to automatically scale your data across the globe This module will reference partitioning in the context of all Azure Cosmos DB modules and APIs.
Partitioning- Why Do We Do It In The First Place? As data size grows, instead of buying more machines (scaling up) we distribute our data across multiple machines Each machine is responsible for serving subset of the data. Analogy: Working in a team
Partitioning Logical partition: Stores all data associated with the same partition key value Physical partition: Fixed amount of reserved SSD-backed storage compute. Cosmos DB distributes logical partitions among a smaller number of physical partitions. From user’s perspective: define 1 partition key per container
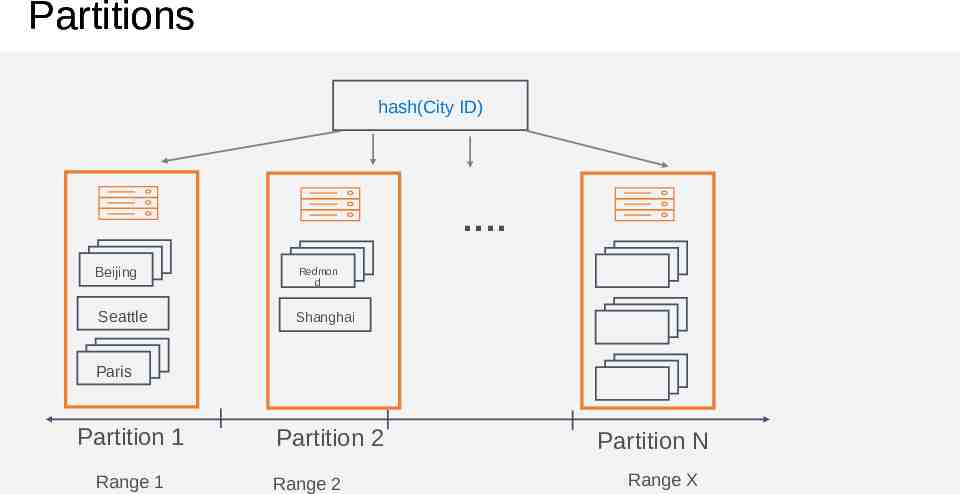
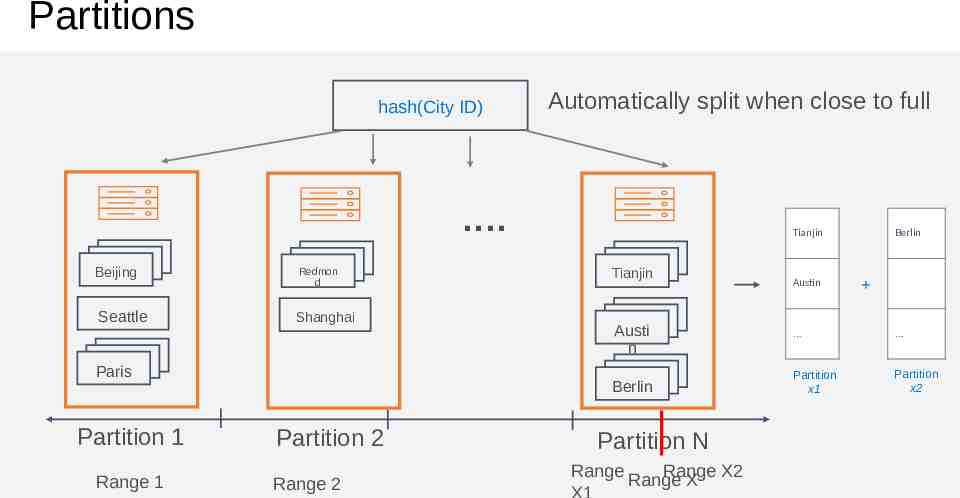
Partitions hash(City ID) . Beijing Redmon d Seattle Shanghai Paris Partition 1 Range 1 Partition 2 Range 2 Partition N Range X
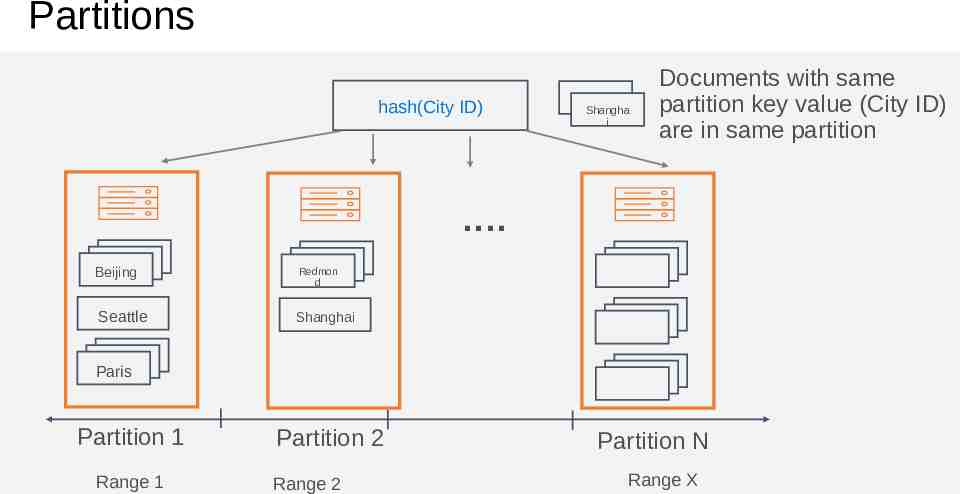
Partitions hash(City ID) Beijing Shangha i Documents with same partition key value (City ID) are in same partition . Beijing Redmon d Seattle Shanghai Paris Partition 1 Range 1 Partition 2 Range 2 Partition N Range X
Partitions hash(City ID) Automatically split when close to full . Beijing Redmon d Seattle Shanghai Paris Partition 1 Range 1 Partition 2 Range 2 Tianjin Tianjin Austin Berlin Austi n Berlin Partition x1 Partition x2 Partition N Range Range Range X X2
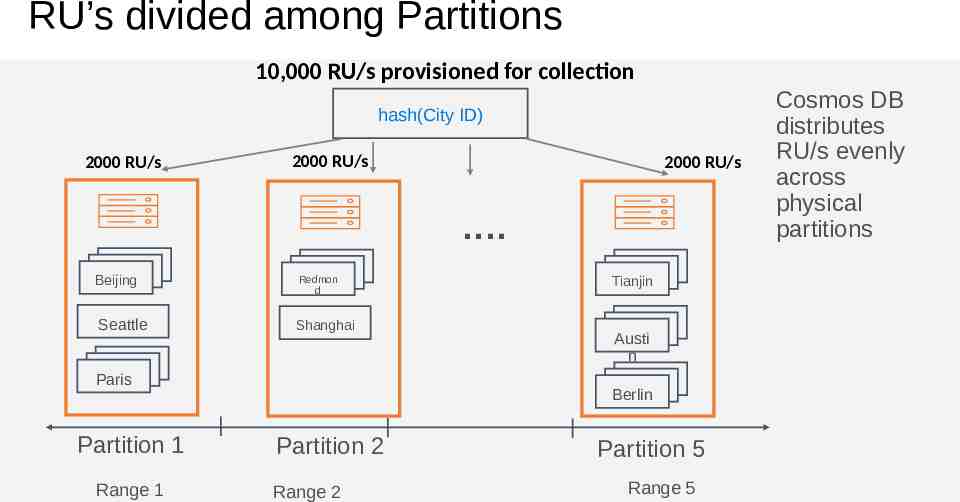
RU’s divided among Partitions 10,000 RU/s provisioned for collection hash(City ID) 2000 RU/s 2000 RU/s 2000 RU/s . Beijing Redmon d Seattle Shanghai Paris Partition 1 Range 1 Tianjin Austi n Berlin Partition 2 Range 2 Partition 5 Range 5 Cosmos DB distributes RU/s evenly across physical partitions
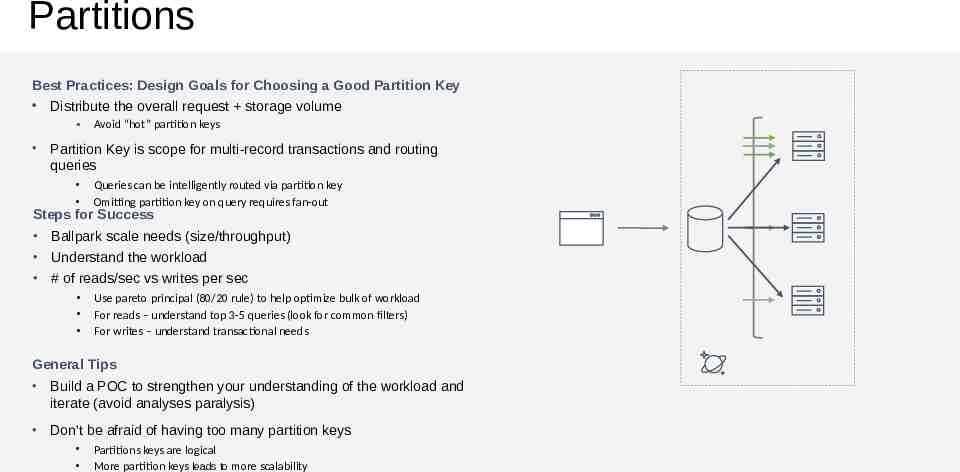
Partitions Best Practices: Design Goals for Choosing a Good Partition Key Distribute the overall request storage volume Avoid “hot” partition keys Partition Key is scope for multi-record transactions and routing queries Queries can be intelligently routed via partition key Omitting partition key on query requires fan-out Steps for Success Ballpark scale needs (size/throughput) Understand the workload # of reads/sec vs writes per sec Use pareto principal (80/20 rule) to help optimize bulk of workload For reads – understand top 3-5 queries (look for common filters) For writes – understand transactional needs General Tips Build a POC to strengthen your understanding of the workload and iterate (avoid analyses paralysis) Don’t be afraid of having too many partition keys Partitions keys are logical More partition keys leads to more scalability
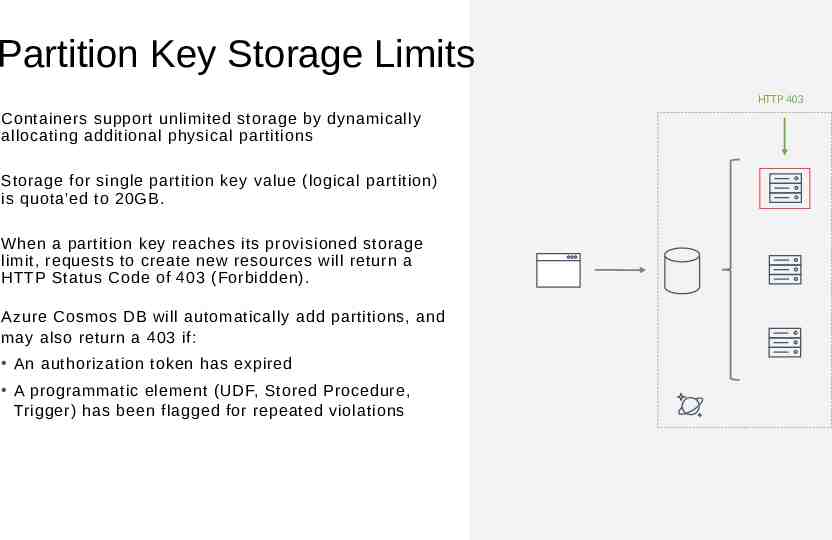
Partition Key Storage Limits HTTP 403 Containers support unlimited storage by dynamically allocating additional physical partitions Storage for single partition key value (logical partition) is quota'ed to 20GB. When a partition key reaches its provisioned storage limit, requests to create new resources will return a HTTP Status Code of 403 (Forbidden). Azure Cosmos DB will automatically add partitions, and may also return a 403 if: An authorization token has expired A programmatic element (UDF, Stored Procedure, Trigger) has been flagged for repeated violations
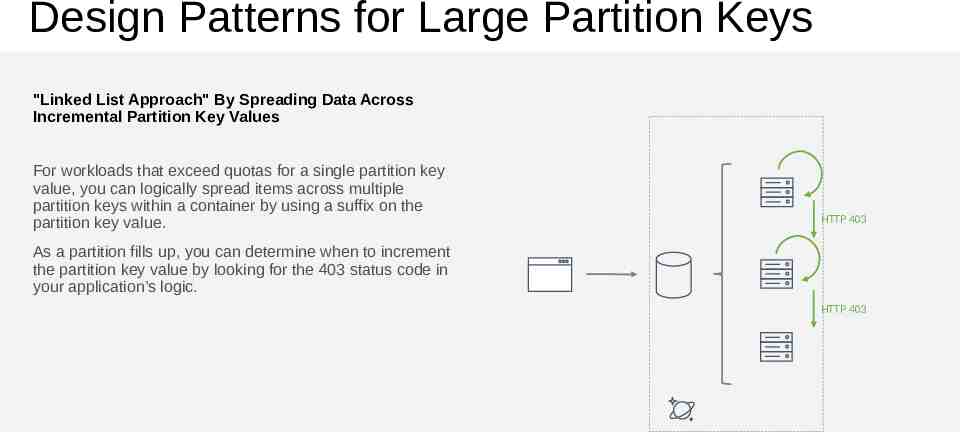
Design Patterns for Large Partition Keys "Linked List Approach" By Spreading Data Across Incremental Partition Key Values For workloads that exceed quotas for a single partition key value, you can logically spread items across multiple partition keys within a container by using a suffix on the partition key value. HTTP 403 As a partition fills up, you can determine when to increment the partition key value by looking for the 403 status code in your application’s logic. HTTP 403
Design Patterns For Large Partition Keys "Circular Buffer" Approach By Reusing Unique Ids As you insert new items into a container’s partition, you can increment the unique id for each item in the partition. When you get a 403 status code, indicating the partition is full, you can restart your unique id and upsert the items to replace older documents. 15 HTTP 403 ARD 15 2 3 4 5 6 7 8 9 10 11 12 13 14
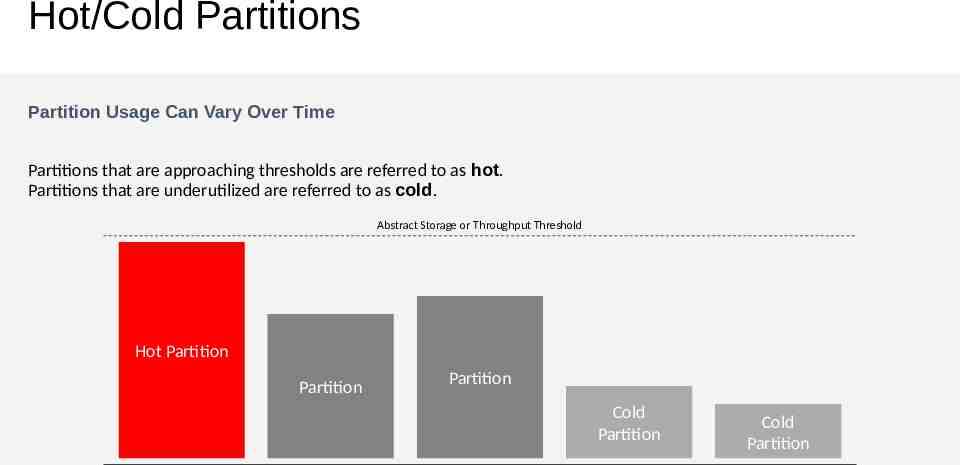
Hot/Cold Partitions Partition Usage Can Vary Over Time Partitions that are approaching thresholds are referred to as hot. Partitions that are underutilized are referred to as cold. Abstract Storage or Throughput Threshold Hot Partition Partition Partition Cold Partition Cold Partition
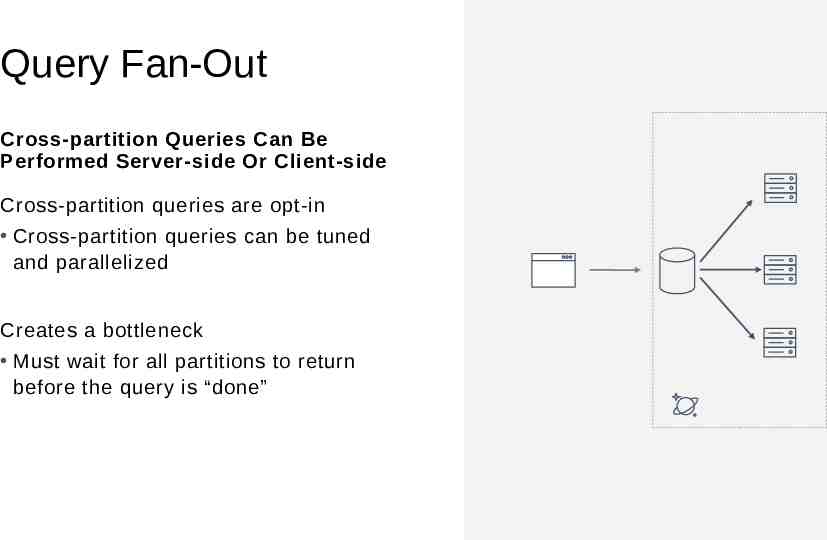
Query Fan-Out Cross-partition Queries Can Be Performed Server-side Or Client-side Cross-partition queries are opt-in Cross-partition queries can be tuned and parallelized Creates a bottleneck Must wait for all partitions to return before the query is “done”
Cross-Partition SDK Example IQueryable DeviceReading crossPartitionQuery client.CreateDocumentQuery DeviceReading ( UriFactory.CreateDocumentCollectionUri("db", "coll"), new FeedOptions { EnableCrossPartitionQuery true, MaxDegreeOfParallelism 10, MaxBufferedItemCount 100 }) .Where(m m.MetricType "Temperature" && m.MetricValue 100) .OrderBy(m m.MetricValue);
DEMO Cross-Partition Query
Query Fan-Out Querying Across Partitions Is Not Always A Bad Thing If you have relevant data to return, creating a cross-partition query is a perfectly acceptable workload with a predictable throughput. In an ideal situation, queries are filtered to only include relevant partitions. Blind Query Fan-outs Can Add Up You are charged 1 RU for each partition that doesn’t have any relevant data. Multiple fan-out queries can quickly max out RU/s for each partition
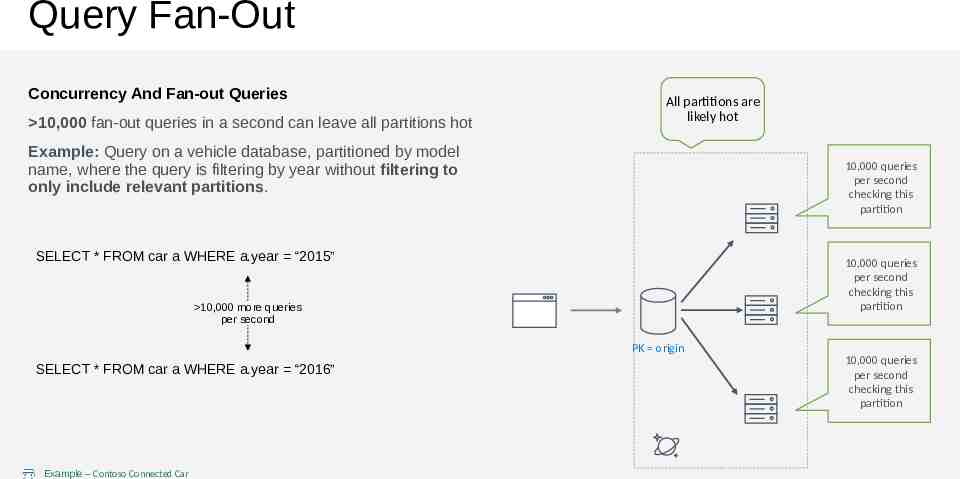
Query Fan-Out Concurrency And Fan-out Queries 10,000 fan-out queries in a second can leave all partitions hot All partitions are likely hot Example: Query on a vehicle database, partitioned by model name, where the query is filtering by year without filtering to only include relevant partitions. 10,000 queries per second checking this partition SELECT * FROM car a WHERE a.year “2015” 10,000 queries per second checking this partition 10,000 more queries per second PK origin SELECT * FROM car a WHERE a.year “2016” Example – Contoso Connected Car 10,000 queries per second checking this partition
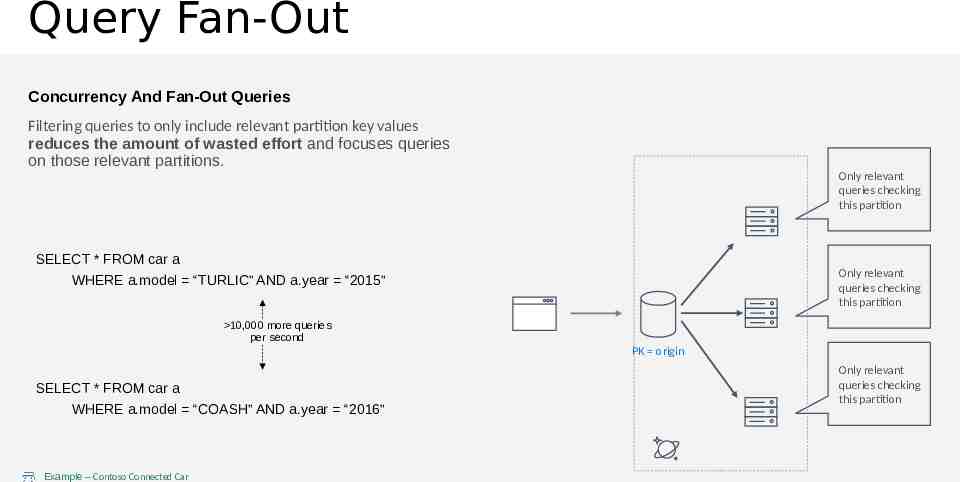
Query Fan-Out Concurrency And Fan-Out Queries Filtering queries to only include relevant partition key values reduces the amount of wasted effort and focuses queries on those relevant partitions. Only relevant queries checking this partition SELECT * FROM car a Only relevant queries checking this partition WHERE a.model “TURLIC” AND a.year “2015” 10,000 more queries per second PK origin SELECT * FROM car a WHERE a.model “COASH” AND a.year “2016” Example – Contoso Connected Car Only relevant queries checking this partition
Review: Choosing a partition Key For each Cosmos DB container, you should specify a partition key. It should satisfy the following core properties: Evenly distribute requests Evenly distribute storage Have a high cardinality (each partition can grow up to 10 GB in size)
Review: Choosing a partition Key In addition, there are a few other areas to consider: Queries can be intelligently routed via partition key: Queries that are scoped to a single partition (or small set of partitions) will consume fewer RU’s than queries that must “fanout” and check every partition No partition key with query - requires fan-out Multi-document transactions must be within a single partition
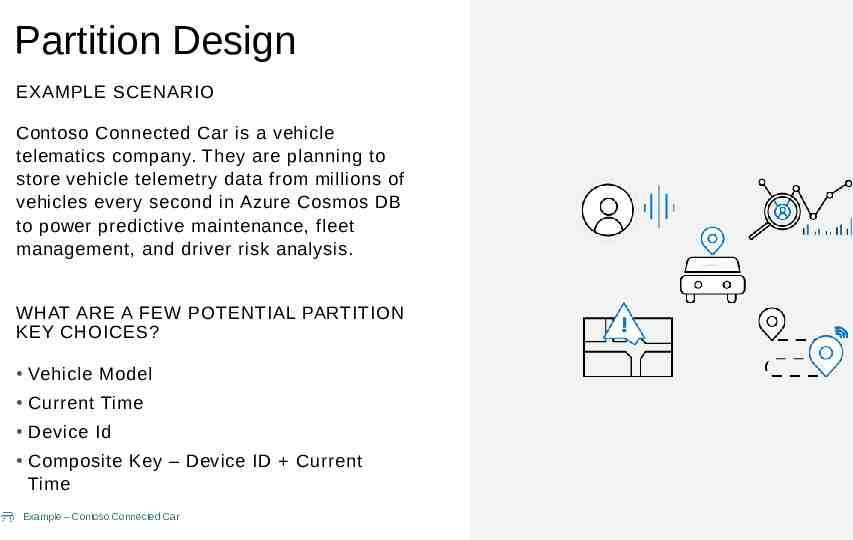
Partition Design EXAMPLE SCENARIO Contoso Connected Car is a vehicle telematics company. They are planning to store vehicle telemetry data from millions of vehicles every second in Azure Cosmos DB to power predictive maintenance, fleet management, and driver risk analysis. WHAT ARE A FEW POTENTIAL PARTITION KEY CHOICES? Vehicle Model Current Time Device Id Composite Key – Device ID Current Time Example – Contoso Connected Car
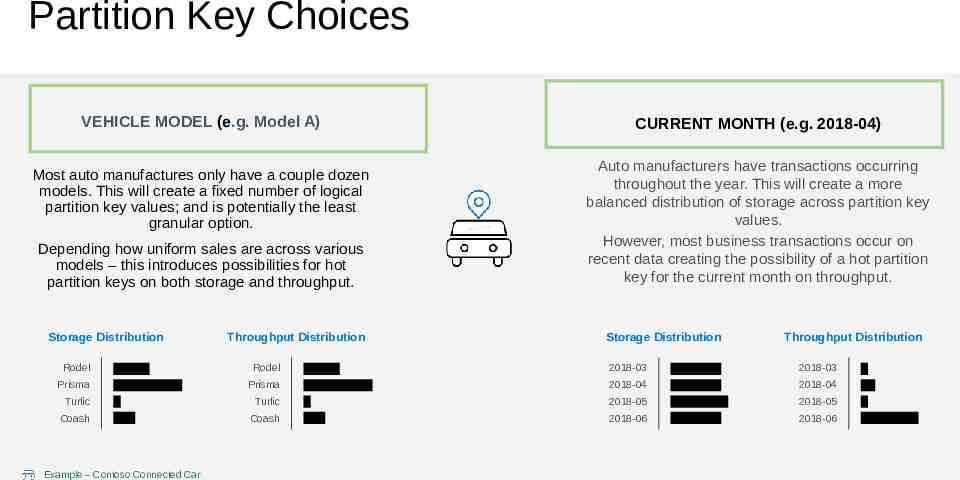
Partition Key Choices VEHICLE MODEL (e.g. Model A) Most auto manufactures only have a couple dozen models. This will create a fixed number of logical partition key values; and is potentially the least granular option. Depending how uniform sales are across various models – this introduces possibilities for hot partition keys on both storage and throughput. Storage Distribution Throughput Distribution CURRENT MONTH (e.g. 2018-04) Auto manufacturers have transactions occurring throughout the year. This will create a more balanced distribution of storage across partition key values. However, most business transactions occur on recent data creating the possibility of a hot partition key for the current month on throughput. Storage Distribution Throughput Distribution Rodel Rodel 2018-03 2018-03 Prisma Prisma 2018-04 2018-04 Turlic Turlic 2018-05 2018-05 Coash Coash 2018-06 2018-06 Example – Contoso Connected Car
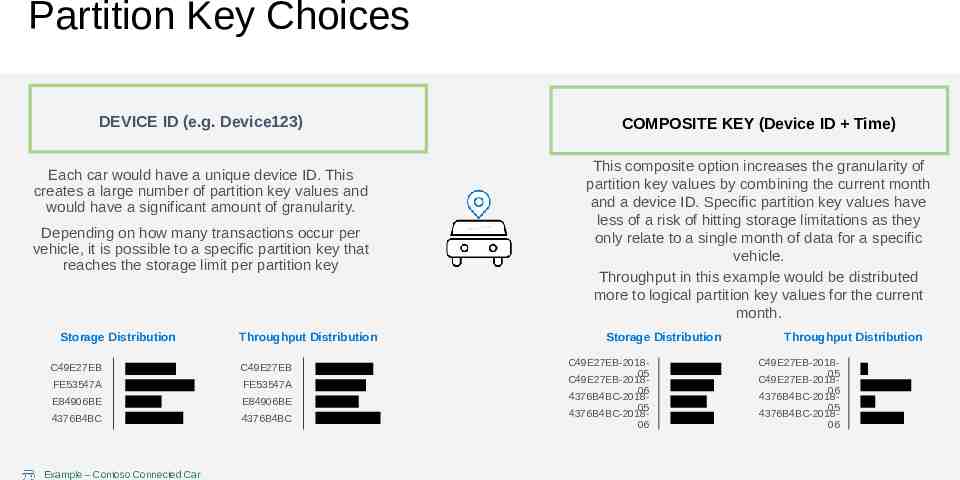
Partition Key Choices DEVICE ID (e.g. Device123) Each car would have a unique device ID. This creates a large number of partition key values and would have a significant amount of granularity. Depending on how many transactions occur per vehicle, it is possible to a specific partition key that reaches the storage limit per partition key Storage Distribution Throughput Distribution C49E27EB C49E27EB FE53547A FE53547A E84906BE E84906BE 4376B4BC 4376B4BC Example – Contoso Connected Car COMPOSITE KEY (Device ID Time) This composite option increases the granularity of partition key values by combining the current month and a device ID. Specific partition key values have less of a risk of hitting storage limitations as they only relate to a single month of data for a specific vehicle. Throughput in this example would be distributed more to logical partition key values for the current month. Storage Distribution C49E27EB-201805 C49E27EB-201806 4376B4BC-201805 4376B4BC-201806 Throughput Distribution C49E27EB-201805 C49E27EB-201806 4376B4BC-201805 4376B4BC-201806






