Overview of BD Security Instructor: Fei Hu ECE 493/593 Big
























































61 Slides870.60 KB
Overview of BD Security Instructor: Fei Hu ECE 493/593 Big Data Security
Why overview (not much math details here)? - This is still week 2, we need to have a big picture of this field - Later on we will use 14 weeks to cover each detailed scheme
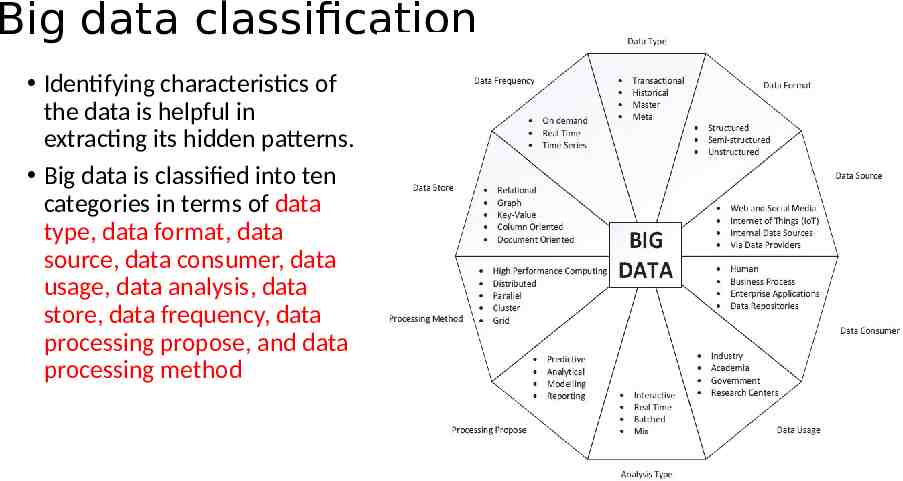
Big data classification Identifying characteristics of the data is helpful in extracting its hidden patterns. Big data is classified into ten categories in terms of data type, data format, data source, data consumer, data usage, data analysis, data store, data frequency, data processing propose, and data processing method
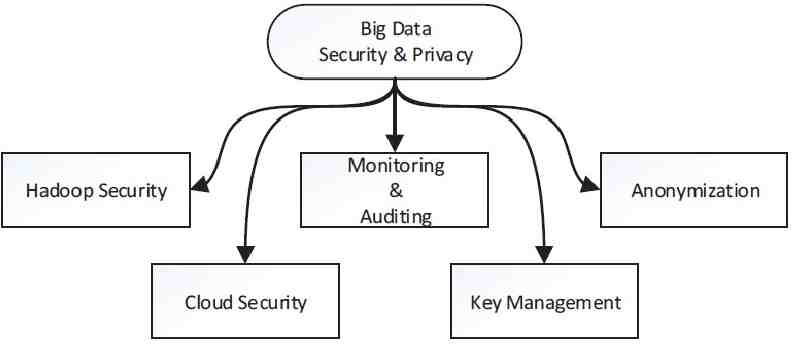
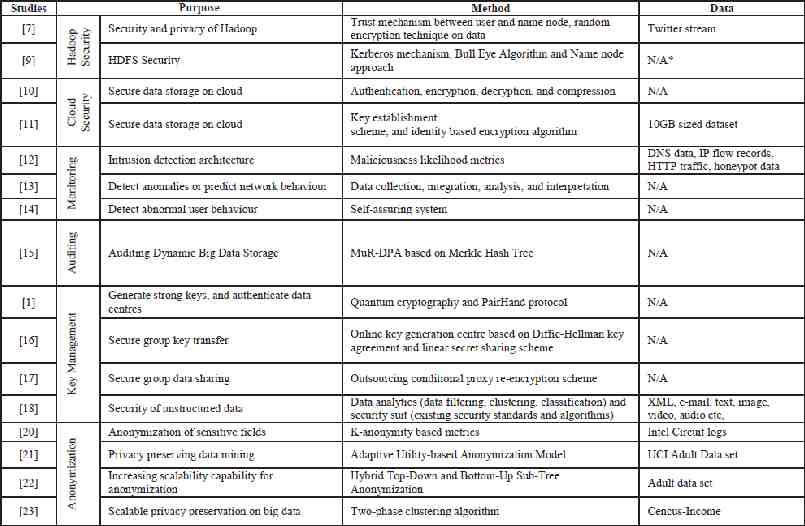
Hadoop Security Hadoop is a distributed process framework and it was not originally developed for security. A trust mechanism has been implemented between user and name node, which is component of HDFS and manages data nodes. According to this mechanism user must authenticate himself to access name node. Firstly, user sends hash result, then name node produces hash result too; it compares these two generated functions. If comparison result is correct, access system is provided. In this step, SHA-256 (one of the hashing techniques) is used for authentication. Random encryption techniques such as RSA, Rijndael, AES and RC6 has been also used on data in order that a hacker does not gain an access to the whole data.
Hadoop Distributed File System (HDFS) An unit that cause the security weakness is Hadoop Distributed File System (HDFS). In order to achieve HDFS authentication issue, Kerberos mechanism based on Ticket Granting Ticket or Service Ticket have been used as first method. The second method is to monitor all sensitive information in 360 by using Bull Eye algorithm. This algorithm has been used to achieve data security and manage relations between the original data and replicated data. It is also allowed only by authorized person to read or write critical data. To handle name node problems, two name nodes have been proposed: one of them is master and the other is slave. If something happened to master node, administrator gives data to slave name node with Name Node Security Enhance (NNSE)’s permission. Therefore latency and data availability problems are addressed.
Cloud Security The widespread use of cloud computing for such reasons as broad network access, on-demand service, resource pooling and being elastic, has become a good application environment for big data. However, the cloud faces traditional threats and new attacks. 1,000 papers published on cloud security
Monitoring and Auditing Intrusion detection and prevention procedures on the whole network traffic is quite difficult. To solve this problem, a security monitoring architecture has been developed by analyzing DNS traffic, IP flow records, HTTP traffic and honeypot data. The proposed solution includes storing and processing data in distributed sources through data correlation schemes. At this stage, three likelihood metrics are calculated to identify whether domain name, individual packets, or whole traffic flow is malicious. According to the score obtained through this calculation, an alert occurs in detection system, or the process is terminated by the prevention system. According to performance analysis with open source big data platforms on electronic payment activities of a company data, Spark and Shark produce faster and more steady results than Hadoop, Hive and Pig.
big data security event monitoring system model Network security systems for big data should find abnormalities quickly and identify correct alerts from heterogeneous data. Therefore, a big data security event monitoring system model has been proposed which consists of four modules: data collection, integration, analysis, and interpretation. Data collection includes security and network devices’ logs and event information. Data integration process is performed by data filtering and classifying. In data analysis module, correlations and association rules are determined to catch events. Finally, data interpretation provides visual and statistical outputs to knowledge database that makes decisions, predict network behavior and respond events.
self-assuring system The separation of non-suspicious and suspicious data behaviors is another issue of monitoring big data. Therefore, a self-assuring system which includes four modules has been suggested. (1) The first module contains keywords that are related to untrusted behavior, and it is called library. (2) The second module records identification information about events when a suspicious behavior occurs, and this step is named as a low-critical log. (3) High critical log (the third module) counts low critical logs’ frequency and checks whether low critical logs reach the threshold’s value. (4) The last module is a self-assuring system, and the user is blocked by the system if he/she has been detected as suspicious.
Protect unstructured data Due to the variety of big data, ensuring the safety of the unstructured data like e-mail, XML or media is more difficult than the structured data. Therefore, a security suit has been developed for data node consisting of different types of data and security services for each data type. The proposed approach contains two stages, data analytics, and security suite. (1) Firstly, filtering, clustering and classification based on data sensitivity level is done in data analytics phase. (2) Then data node of databases is created and a scheduling algorithm selects the appropriate service according to security (identification, confidentiality, integrity, authentication, non-repudiation) and sensitivity level (sensitive, confidential, public) from security suite. For example, to provide privacy of sensitive text data, 3DES algorithm is selected.
Big data Privacy - Anonymization Data harvesting for analytics causes big privacy concerns. Protecting personally identifiable information (PII) is increasingly difficult because the data are shared too quickly. To eliminate privacy concerns, the agreement between the company and the individual must be determined by policies. Personal data must be anonymized (de-identified) and transferred into secure channels. However, the identity of the person can be uncovered depending on the algorithms and the artificial intelligence analysis of company. The predictions made by this analysis can lead to unethical issues.
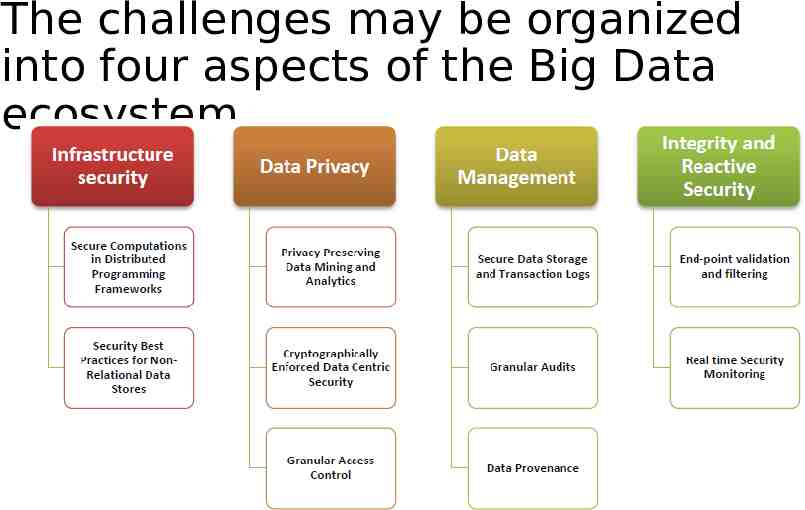
10 BD security challenges
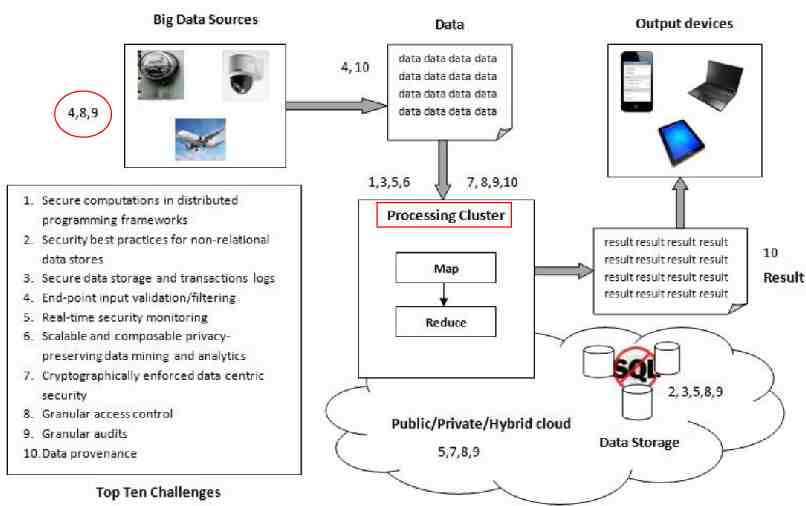
10 challenges 1. Secure computations in distributed programming frameworks 2. Security best practices for non-relational data stores 3. Secure data storage and transactions logs 4. End-point input validation/filtering 5. Real-time security monitoring 6. Scalable and composable privacy-preserving data mining and analytics 7. Cryptographically enforced data centric security 8. Granular access control 9. Granular audits 10. Data provenance
The challenges may be organized into four aspects of the Big Data ecosystem
Why those 4 aspects? In order to secure the infrastructure of Big Data systems, the distributed computations and data stores must be secured. To secure the data itself, information dissemination must be privacypreserving, and sensitive data must be protected through the use of cryptography and granular access control. Managing the enormous volume of data necessitates scalable and distributed solutions for both securing data stores and enabling efficient audits and data provenance. Finally, the streaming data emerging from diverse end-points must be checked for integrity and can be used to perform real time analytics for security incidents to ensure the health of the infrastructure.
C(1). Secure Computations in Distributed Programming Frameworks Distributed programming frameworks utilize parallel computation and storage to process massive amounts of data. For example, the MapReduce framework splits an input file into multiple chunks. In the first phase of MapReduce, a Mapper for each chunk reads the data, performs some computation, and outputs a list of key/value pairs. In the next phase, a Reducer combines the values belonging to each distinct key and outputs the result. There are two major attack prevention measures: securing the mappers and securing the data in the presence of an untrusted mapper.
Attacks to MapReduce Untrusted mappers can be altered to snoop on requests, alter MapReduce scripts, or alter results. The most difficult problem is to detect mappers returning incorrect results, which will, in turn, generate incorrect aggregate outputs. With large data sets, it is nearly impossible to identify malicious mappers that may create significant damage, especially for scientific and financial computations. Retailer consumer data is often analyzed by marketing agencies for targeted advertising or customer-segmenting. These tasks involve highly parallel computations over large data sets and are particularly suited for MapReduce frameworks such as Hadoop. However, the data mappers may contain intentional or unintentional leakages. For example, a mapper may emit a unique value by analyzing a private record, undermining users’ privacy.
Threat Models 1. Malfunctioning Compute Worker Nodes – Workers assigned to mappers in a distributed computation could malfunction due to incorrect configuration or a faulty node. A malfunctioning Worker could return incorrect output from the mapper, which may compromise the integrity of the aggregate result. Such a Worker may also be modified to leak users’ confidential data or profile users’ behaviors or preferences for privacy mining. 2. Infrastructure Attacks – Compromised Worker nodes may tap the communication among other Workers and the Master with the objective of replay, Man-In-the-Middle, and DoS attacks to the MapReduce computations. 3. Rogue Data Nodes – Rogue data nodes can be added to a cluster, and subsequently receive replicated data or deliver altered MapReduce code. The ability to create snapshots of legitimate nodes and re-introduce altered copies is a straightforward attack in cloud and virtual environments and is difficult to detect.
Solution: ensuring the trustworthiness of mappers two techniques: (1) trust establishment: It has two steps: initial trust establishment followed by periodic trust update. When a Worker sends a connection request to the Master, the Master authenticates the Worker. Only authenticated Workers with expected properties will be assigned a mapper task. Following the initial authentication, the security properties of each Worker are checked periodically for conformance with predefined security policies. (2) Mandatory Access Control (MAC): MAC ensures access to the files authorized by a predefined security policy. MAC ensures integrity of inputs to the mappers, but does not prevent data leakage from the mapper outputs.
On Mandatory Access Control (MAC) MAC is implemented in Airavat by modifying the MapReduce framework, the distributed file system, and the Java virtual machine with SELinux as the underlying operating system. MAC in SELinux ensures that untrusted code does not leak information via system resources. However it cannot guarantee privacy for computations based on output keys produced by untrusted mappers. To prevent information leakage through the outputs, it relies on a recently developed de-identification framework of differential privacy based on function sensitivity. In the context of mappers, function sensitivity is the degree of influence that an input can have the mapper output. Estimating the sensitivity of arbitrary untrusted code is difficult.
C(2): Security Best Practices for Non-Relational Data Stores Companies dealing with large unstructured data sets may benefit by migrating from a traditional relational database (RDB) to a NoSQL database. NoSQL databases accommodate and process huge volumes of static and streaming data for predictive analytics or historical analysis. Threat trees derived from detailed threat analysis using threat-modeling techniques on widely used NoSQL databases demonstrate that NoSQL databases only have a very thin security layer, compared to traditional RDBs. In general, the security philosophy of NoSQL databases relies on external enforcement mechanisms. To reduce security incidents, the company must review security policies for the middleware and, at the same time, toughen the NoSQL database itself to match the security RDBs without compromising on its operational features. It is important that security loopholes within NoSQL databases are plugged without compromising on its outstanding analytical capabilities.
threat model of NoSQL databases – 6 aspects 1. Transactional Integrity – One of the most visible drawbacks of NoSQL is its soft approach towards ensuring transactional integrity. Introducing ‘complex integrity constraints’ into its architecture will fail NoSQL’s primary objective of attaining better performance and scalability. Techniques like Architectural Trade-off Analysis Method (ATAM) specifically deal with the trade-offs in quality requirements in architectural decision (for example, performance vs. security). This analytical method can be utilized to evaluate the level of integrity constraints that may be infused into a core architectural kernel without significantly affecting performance. 2. Lacks Authentication Mechanisms – Across the board, NoSQL uses weak authentication techniques and weak password storage mechanisms. This exposes NoSQL to replay attacks and password brute force attacks, resulting in information leakage. NoSQL uses HTTP Basic- or Digest-based authentication, which are prone to replay or man-in-the-middle attack. REST, which is another preferred communication protocol, is also based on HTTP and is prone to cross-site scripting, cross-site request forgery, injection attacks, etc. Above all, NoSQL does not support integrating third-party pluggable modules to enforce authentication. By manipulating the RESTful connection definition, it is possible to get access to the handles and configuration parameters of the underlying database, thereby gaining access to the file system. Although some of the existing NoSQL databases offer authentication at the local node level, they fail to enforce authentication across all the cluster nodes.
threat model of NoSQL databases – 6 aspects 3. Inefficient Authorization Mechanisms – Authorization techniques differ from one NoSQL solution to another. Most of the popular solutions apply authorization at higher layers rather than enforcing authorization at lower layers. More specifically, authorization is enforced on a per-database level rather than at the collection level. There is no role-based access control (RBAC) mechanism built into the architecture because defining user roles and security groups with an RBAC mechanism is impossible. 4. Susceptibility to “Injection Attacks” – Easy to employ injection techniques allow backdoor access to the file system for malicious activities. Since NoSQL architecture employs lightweight protocols and mechanisms that are loosely coupled, it is susceptible to various injection attacks like JSON injection, array injection, view injection, REST injection, GQL injection, schema injection, etc. For example, an attacker can utilize schema injection to inject thousands of columns onto the database with data of the attacker’s choice. The impact of such an attack can range from a database with corrupted data to a DoS attack resulting in total unavailability of the database.
threat model of NoSQL databases – 6 aspects 5. Lack of Consistency – The inability to simultaneously enforce all three elements of the CAP theorem (consistency, availability, and partition tolerance) while in distributed mode undermines the trustworthiness of the churned results. As a result, users are not guaranteed consistent results at any given time, as each participating node may not be entirely synchronized with the node holding the latest image. Current hashing algorithms entrusted to replicate data across the cluster nodes crumple in the event of a single node failure, resulting in load imbalance among the cluster nodes. 6. Insider Attacks - Lenient security mechanisms can be leveraged to achieve insider attacks. These attacks could remain unnoticed because of poor logging and log analysis methods, along with other rudimentary security mechanisms. As critical data is stowed away under a thin security layer, it is difficult to ensure that the data owners maintain control.
Secure NoSQL (1) It is evident from the threat models and analysis that plugging NoSQL holes by wrapping sensitive data within the thin, easily penetrable security layer of web or similar interfaces is insufficient to guarantee the security of the underlying data. Hiding NoSQL under the secure wrapper of middleware, or accessing NoSQL using a framework like Hadoop can create a virtual secure layer around the NoSQL perimeter. Object-level security at the collection- or column-level can be induced through the middleware, retaining its thin database layer. Such a methodology will ensure that there is no direct access to the data and that the data is only exposed based on the controls configured within the middleware or framework layer.
Secure NoSQL (2) Deploying the middleware layer to encapsulate the underlying NoSQL stratum can be another option to implement security. Most of the middleware software comes with ready-made support for authentication, authorization and access control. In the case of Java, Java Authentication and Authorization Services (JAAS) and SpringSource, Spring Security frameworks are deployed for authentication, authorization and access control. Such an architecture will ensure that any changes to schema, objects and/or data are validated, thus gaining better control while preserving the capabilities of NoSQL.
Secure NoSQL (3) In order to maintain performance, the ability to scale to demand, and the security of the overall system, it is necessary to integrate NoSQL into a framework, thereby offloading the security components onto the framework. Such a framework should be tightly coupled with the underlying operating system so that policy-based security layers can be burned onto the lower substratum (kernel layer). This will ensure that the missing RBAC can be enforced in order to (1) limit access to the underlying data, (2) preserve the thinness of the database layer, and (3) maintain the analytical capability of NoSQL.
Secure NoSQL (4) As an alternative to vulnerable NoSQL data, encryption provides better protection. Hadoop employs file-layer encryption to provide unswerving protection, irrespective of the operating system, platform or storage type. With the availability of products capable of offering encryption, demand for handling streaming data and processing them in-memory is on the rise. Encryption solutions seem to be a cost effective way to address several of the known data-security issues.
C(3). Secure Data Storage and Transactions Logs Network-based, distributed, auto-tier storage systems are a promising solution that possess advanced features such as transparent service, good scalability and elasticity. However, auto-tier storage systems generate new vulnerabilities due to a lack of physical possession, untrusted storage service, or inconsistent security policies. The threat model for auto-tier storage systems includes 7 major scenarios:
Threat models (1 -3) 1. Confidentiality and Integrity – In addition to those attempting to steal sensitive information or damage user data, storage service providers are also assumed to be untrustworthy third parties. Data transmission among tiers in a storage system provides clues that enable the service provider to correlate user activities and data set. Without being able to break the cipher, certain properties can be revealed. 2. Provenance – Due to the extremely large size, it is infeasible to download the entire data set to verify its source, availability and integrity. Lightweight schemes are desired to provide verification that is probabilistically accurate and incurs low computing and communication overhead. 3. Availability – Auto-tiering also places challenges on the service providers to guarantee constant availability. Not only does weaker security at lower tiers risk Denial of Service (DoS) attacks, the performance gap between lower tiers and higher tiers also extends the backup windows during periods of fast restore and disaster recovery.
Threat models (4 -5) 4. Consistency – It is now typical that data can flow among tiers and is shared by multiple users. To maintain consistency among multiple duplicates stored at difference locations is non-trivial. Two issues that need to be addressed carefully are write-serializability and multi-writer multi-reader (MWMR) problems . 5. Collusion Attacks – While a data owner stores the cipher text in an auto-tier storage system and distributes the key and permission access to the users, each user is authorized to have access to a certain portion of the data set. Also, the service provider cannot interpret the data without the cipher key materials. However, if the service provider colludes with users by exchanging the key and data, they will obtain a data set that they are not entitled to.
Threat models (6-7) 6. Roll-Back Attacks – In a multi-user environment, the service provider can launch rollback attacks on users. When an updated version of a data set has been uploaded into storage, the service provider can fool the user by delivering the outdated version. Certain evidence is required to help users ensure that data is up-to-date, and the user should have the capability of detecting the inconsistency. This is also referred to as “User’s Freshness.” 7. Disputes – A lack of recordkeeping will lead to disputes between users and the storage service provider, or among users. When data loss or tampering occurs, transmission logs/records are critical to determining responsibility. For example, a malicious user outsources data to a storage system. Later, the user reports data loss and asks for compensation for his claimed loss. In this case, a well-maintained log can effectively prevent fraud.
C(4) End-Point Input Validation/Filtering Many Big Data uses in enterprise settings require data collection from a variety of sources, including end-point devices. For example, a security information and event management system (SIEM) may collect event logs from millions of hardware devices and software applications in an enterprise network. A key challenge in the data collection process is input validation: how can we trust the data? How can we validate that a source of input data is not malicious? And how can we filter malicious input from our collection? Input validation and filtering is a daunting challenge posed by untrusted input sources, especially with the bring-your-own-device (BYOD) model.
Threat Models A threat model for input validation has four major scenarios: 1. An adversary may tamper with a device from which data is collected, or may tamper with the data collection application running on the device to provide malicious input to a central data collection system. For example, in the case of iPhone feedback voting, an adversary may compromise an iPhone (i.e., the iPhone’s software platform) or may compromise the iPhone app that collects user feedback. 2. An adversary may perform ID cloning attacks (e.g., Sybil attacks) on a data collection system by creating multiple fake identities (e.g., spoofed iPhone IDs) and by then providing malicious input from the faked identities. The challenges of Sybil attacks become more acute in a BYOD scenario. Since an enterprise’s users are allowed to bring their own devices and use them inside the enterprise network, an adversary may use her device to fake the identity of a trusted device and then provide malicious input to the central data collection system. 3. A more complicated scenario involves an adversary that can manipulate the input sources of sensed data. For example, instead of compromising a temperature sensor, an adversary may be able to artificially change the temperature in a sensed location and introduce malicious input to the temperature collection process. Similarly, instead of compromising an iPhone or a GPS-based location sensing app running on the iPhone, an adversary may compromise the GPS signal itself by using GPS satellite simulators [7]. 4. An adversary may compromise data in transmission from a benign source to the central collection system (e.g., by performing a man-in-the-middle attack or a replay attack).
Overcome attacks Given the above threat model, solutions to the input validation problem fall into two categories: (a) solutions that prevent an adversary from generating and sending malicious input to the central collection system. Preventing an adversary from sending malicious input requires tamper-proof software and defenses against Sybil attacks. Research on the design and implementation of tamper-proof secure software has a very long history in both academia and industry. (b) solutions that detect and filter malicious input at the central system if an adversary successfully inputs malicious data. Defense schemes against ID cloning attacks and Sybil attacks have been proposed in diverse areas such as peer-to-peer systems, recommender systems, vehicular networks, and wireless sensor networks. Many of these schemes propose to use trusted certificates and trusted devices to prevent Sybil attacks.
C(5) Real-Time Security Monitoring One of the most challenging Big Data analytics problems is real-time security monitoring, which consists of two main angles: (a) monitoring the Big Data infrastructure itself and (b) using the same infrastructure for data analytics. An example of (a) is the monitoring of the performance and health of all the nodes that make up the Big Data infrastructure. An example of (b) would be a health care provider using monitoring tools to look for fraudulent claims or a cloud provider using similar Big Data tools to get better real-time alert and compliance monitoring. These improvements could provide a reduction in the number of false positives and/or an increase in the quality of the true positives.
Threat models Security monitoring requires that the Big Data infrastructure, or platform, is inherently secure. Threats to a Big Data infrastructure include rogue admin access to applications or nodes, (web) application threats, and eavesdropping on the line. Such an infrastructure is mostly an ecosystem of different components, where (a) the security of each component and (b) the security integration of these components must be considered. For example, if we run a Hadoop cluster in a public cloud, one has to consider: 1. The security of the public cloud, which itself is an ecosystem of components consisting of computing, storage and network components. 2. The security of the Hadoop cluster, the security of the nodes, the interconnection of the nodes, and the security of the data stored on a node. 3. The security of the monitoring application itself, including applicable correlation rules, which should follow secure coding principles and best practices. 4. The security of the input sources (e.g., devices, sensors) that the data comes from.
C(6) Scalable and Composable Privacy-Preserving Data Mining and Analytics A recent analysis of how companies are leveraging data analytics for marketing purposes included an example of how a retailer was able to identify a teen’s pregnancy before her father learned of it [28]. Similarly, anonymizing data for analytics is not enough to maintain user privacy. For example, AOL released anonymized search logs for academic purposes, but users were easily identified by their searches [29]. Netflix faced a similar problem when anonymized users in their data set were identified by correlating Netflix movie scores with IMDB scores.
Threat models A threat model for user privacy shows three major scenarios: 1. An insider in the company hosting the Big Data store can abuse her level of access and violate privacy policies. An example of this scenario is the case of a Google employee who stalked teenagers by monitoring their Google chat communications [30]. 2. If the party owning the data outsources data analytics, an untrusted partner might be able to abuse their access to the data to infer private information from users. This case can apply to the usage of Big Data in the cloud, as the cloud infrastructure (where data is stored and processed) is not usually controlled by the owners of the data. 3. Sharing data for research is another important use. However, as we pointed out in the introduction to this section, ensuring that the data released is fully anonymous is challenging because of re-identification. EPIC’s definition of re-identification is the process by which anonymized personal data is matched with its true owner. Several examples of re-identification can be seen in EPIC’s website [31].
C(7) Cryptographically Enforced Data-Centric Security There are two fundamentally different approaches to controlling the visibility of data to different entities, such as individuals, organizations and systems. The first approach controls the visibility of data by limiting access to the underlying system, such as the operating system or the hypervisor. The second approach encapsulates the data itself in a protective shell using cryptography. Both approaches have their benefits and detriments. Historically, the first approach has been simpler to implement and, when combined with cryptographically-protected communication, is the standard for the majority of computing and communication infrastructure.
Threat models (1) Threat models in cryptography are mathematically defined through an interaction between systems implementing the protocol and an adversary, which is able to access the externally visible communications and to compute any probabilistic polynomial time function of the input parameters. Threat models for four major scenarios are: 1. For a cryptographically-enforced access control method using encryption, the adversary should not be able to identify the corresponding plaintext data by looking at the ciphertext, even if given the choice of a correct and an incorrect plaintext. This should hold true even if parties excluded by the access control policy collude among each other and with the adversary.
Threat models (2-4) 2. For a cryptographic protocol for searching and filtering encrypted data, the adversary should not be able to learn anything about the encrypted data beyond whether the corresponding predicate was satisfied. Recent research has also succeeded in hiding the search predicate itself so that a malicious entity learns nothing meaningful about the plaintext or the filtering criteria. 3. For a cryptographic protocol for computation on encrypted data, the adversary should not be able to identify the corresponding plaintext data by looking at the ciphertext, even if given the choice of a correct and an incorrect plaintext. Note that this is a very stringent requirement because the adversary is able to compute the encryption of arbitrary functions of the encryption of the original data. In fact, a stronger threat model called chosen ciphertext security for regular encryption does not have a meaningful counterpart in this context – the search to find such a model continues [38]. 4. For a cryptographic protocol ensuring the integrity of data coming from an identified source, there could be a range of threat models. The core requirement is that the adversary should not be able to forge data that did not come from the purported source. There could also be some degree of anonymity in the sense that the source could only be identified as being part of a group. In addition, in certain situations (maybe legal), a trusted third party should be able to link the data to the exact source.
Solutions 1. Identity and attribute based encryption [49], [50] methods enforce access control using cryptography. In identity-based systems, plaintext can be encrypted for a given identity and the expectation is that only an entity with that identity can decrypt the ciphertext. Any other entity will be unable to decipher the plaintext, even with collusion. Attribute-based encryption extends this concept to attribute-based access control. 2. Boneh and Waters [40] construct a public key system that supports comparison queries, subset queries and arbitrary conjunction of such queries. 3. In a breakthrough result [41] in 2009, Gentry constructed the first fully homomorphic encryption scheme. Such a scheme allows one to compute the encryption of arbitrary functions of the underlying plaintext. Earlier results [42] constructed partially homomorphic encryption schemes. 4. Group signatures [43] enable individual entities to sign their data but remain identifiable only in a group to the public. Only a trusted third party can pinpoint the identity of the individual.
C(8) Granular Access Control The security property that matters from the perspective of access control is secrecy – preventing access to data by people that should not have access. The problem with coarse-grained access mechanisms is that data that could otherwise be shared is often swept into a more restrictive category to guarantee sound security. Granular access control gives data managers more precision when sharing data, without compromising secrecy.
Granular access control – 3 issues Granular access control can be decomposed into three sub-problems. The first is keeping track of secrecy requirements for individual data elements. In a shared environment with many different applications, the ingesters (those applications that contribute data) need to communicate those requirements to the queriers. This coordination requirement complicates application development, and is often distributed among multiple development teams. The second sub-problem is keeping track of roles and authorities for users. Once a user is properly authenticated, it is still necessary to pull security-related attributes for that user from one or more trusted sources. LDAP, Active Directory, OAuth, OpenID, and many other systems have started to mature in this space. One of the continual challenges is to properly federate the authorization space, so a single analytical system can respect roles and authorities that are defined across a broad ecosystem. The third sub-problem is properly implementing secrecy requirements with mandatory access control. This is a logical filter that incorporates the requirements coupled with the data and the attributes coupled with a user to make an access decision. This filter is usually implemented in the application space because there are few infrastructure components that support the appropriate level of granular access controls.
Solution The first challenge is to pick the appropriate level of granularity required for a given domain. Row-level protection, where a row represents a single record, is often associated with security that varies by data source. Column-level protection, where a column represents a specific field across all records, is often associated with sensitive schema elements. A combination of row- and column-level security is more granular still but can break down under analytical uses. Table transformations, or question-focused data sets, often do not preserve row- or column-orientation, so they require a solution with even finer granularity. Cell-level access control supports labeling every atomic nugget of information with its releasability and can support a broad set of data transformation uses.
C(9) Granular Audits In order to discover a missed attack, audit information is necessary. Audit information is crucial to understand what happened and what went wrong. It is also necessary due to compliance, regulation and forensic investigation. Auditing is not something new, but the scope and granularity might be different in real-time security contexts. For example, in these contexts there are more data objects, which are probably (but not necessarily) distributed.
Significance of auditing Compliance requirements (e.g., PCI, Sarbanes-Oxley) require financial firms to provide granular auditing records. Additionally, the cost of losing records containing private information is estimated at 200/record. Legal action – depending on the geographic region – might follow in case of a data breach. Key personnel at financial institutions require access to large data sets containing personally identifiable information (PII), such as social security numbers. In another potential use case, marketing firms want access to personal social media information to optimize their deployment of online ads.
Threat Models for auditing Key factors for auditing comprise the following: 1. Completeness of the required audit information (i.e., having access to all the necessary log information from a device or system). 2. Timely access to audit information. This is especially important in case of forensics, for example, where time is of the essence. 3. Integrity of the information or, in other words, audit information that has not been tampered with. 4. Authorized access to the audit information. Only authorized people can access the information and only the parts they need to perform their job. Threats (e.g., unauthorized access, removal of data, tempering with log files) to those key factors will jeopardize the audit data and process.
Solutions Implementation of audit features starts on the individual component level. Examples include enabling syslog on routers, application logging, and enabling logging on the operating system level. After this, a forensics or SIEM tool collects, analyzes and processes this information. The amount of recording is subject to the limitations of the SIEM tool in processing the volume and velocity of the audit data. Ironically, the audit data might have the characteristics of Big Data itself and, as such, may need to be processed by a Big Data infrastructure. To separate the use of the Big Data infrastructure and the audit of this infrastructure, it is recommended to have the forensics/SIEM tool implemented and used outside of the Big Data infrastructure when feasible. Another approach would be to create an “Audit Layer/Orchestrator,” which would abstract the required (technical) audit information from the auditor. This orchestrator would take the auditor’s requests (i.e., who had access to data object X on date D), collect the necessary audit information from the required infrastructure components, and returns this information to the auditor.
C(10) Data Provenance Provenance metadata will grow in complexity due to large provenance graphs generated from provenance-enabled programming environments in Big Data applications. Analysis of such large provenance graphs to detect metadata dependencies for security and/or confidentiality applications is computationally intensive. Several key security applications require a digital record with, for example, details about its creation. Examples include detecting insider trading for financial companies or determining the accuracy of the data source for research investigations. These security assessments are time-sensitive in nature and require fast algorithms to handle the provenance metadata containing this information. In addition, data provenance complements audit logs for compliance requirements, such as PCI or Sarbanes-Oxley.
Threat models in data provenance (1) Secure provenance in Big Data applications first requires the provenance records to be reliable, provenance-integrated, privacy-preserving, and access-controllable. At the same time, due to the characteristics of Big Data, provenance availability and scalability should also be carefully addressed. Specifically, the threats to the provenance metadata in Big Data applications can be formally modeled into three categories: 1. Malfunctioning Infrastructure Components – In Big Data applications, when large numbers of components collaboratively generate large provenance graphs from provenance-enabled programming environments, it is inevitable that some infrastructure components could sporadically malfunction. Once the malfunction occurs, provenance data cannot be timely generated and some malfunctions could lead to incorrect provenance records. As a result, the malfunctioning infrastructure components will reduce the provenance availability and reliability.
Threat models (2-3) 2. Infrastructure Outside Attacks – Since provenance is pivotal to the usability of Big Data applications, it naturally becomes a target in Big Data applications. An outside attacker can forge, modify, replay, or unduly delay the provenance records during its transmission to destroy the usability of the provenance, or violate privacy by eavesdropping and analyzing the records. 3. Infrastructure Inside Attacks – Compared to the outside attacks, the infrastructure inside attacks are more harmful. An inside attacker could modify and delete the stored provenance records and audit logs to destroy the provenance system in Big Data applications.
Solutions To address the above threats, two research issues need to be engaged to ensure the trustworthiness and usability of secure provenance in Big Data applications i.e., (1) securing provenance collection and (2) fine-grained access control of provenance.
Solution (1) To secure provenance collection, the source components that generate provenance in the infrastructure should be first authenticated. In addition, periodic status updates should be generated to ensure the health of the source components. To guarantee the accuracy of the provenance records, the provenance should be taken through an integrity check to assure that it is not forged or modified. Furthermore, the consistency between the provenance and its data should also be verified because inconsistency can lead to wrong decisions. Since the provenance sometimes contains sensitive information pertaining to the data, encryption techniques are required to achieve provenance confidentiality and privacy preservation [32]. Finally, compared to the small-scale, static data applications, the provenance collection for Big Data should be efficient to accommodate ever-increasing volume, variety, and velocity of information. In this way, secure provenance collection is efficiently achieved in Big Data applications. In other words, the provenance collection is secure against malfunctioning infrastructure components and outside attacks.
Solution (2) To resist the infrastructure inside attacks, fine-grained access control of provenance is desired. In Big Data applications, the provenance records include not only the provenance of different application data, but also the provenance for the Big Data infrastructure itself. Therefore, the number of provenance records in Big Data applications is much larger than that in small-scale, static data applications. For these large-volume, complex, and sometimes sensitive provenance, access control is required. Otherwise, it would not be possible to deal with the infrastructure inside attacks. Fine-grained access control assigns different rights to different roles to access provenance in Big Data applications. At the same time, data independent persistence should also be satisfied when updating the large provenance graphs. For example, even though a data objective is removed, since it serves as an ancestor of other data objectives, its provenance should be kept in the provenance graph. Otherwise, the provenance graph will become disconnected and incomplete. Furthermore, fine-grained access control should be dynamic and scalable, and flexible revocation mechanisms should also be supported.
Implementations Provenance is crucial for the verification, audit trails, assurance of reproducibility, trust, and fault detection in many big-data applications. To retrofit provenance in existing cloud infrastructure for Big Data applications, we must address secure provenance collection and fine-grained access control effectively. To address the secure provenance collection, fast and lightweight authentication technique should be integrated into the current provenance in existing cloud infrastructure (e.g., PASOA [33]). In addition, secure channels should be established between infrastructure components to achieve end-to-end security. Finally, fine-grained access control (e.g., revocable ABE access control [34]) should be integrated into the current provenance storage system (e.g., PASS [35]) to achieve provenance storage and access security in Big Data applications.
Summary Here we have highlighted the top ten security and privacy problems that need to be addressed to make Big Data processing and computing infrastructure more secure. Common elements specific to Big Data arise from the use of multiple infrastructure tiers (both storage and computing) for processing Big Data; the use of new compute infrastructures such as NoSQL databases (for fast throughput necessitated by Big Data volumes) that have not been thoroughly vetted for security issues; the non-scalability of encryption for large data sets; the non-scalability of real-time monitoring techniques that might be practical for smaller volumes of data; the heterogeneity of devices that produce the data; and the confusion surrounding the diverse legal and policy restrictions that lead to ad hoc approaches for ensuring security and privacy. Many of the items in this list serve to clarify specific aspects of the attack surface of the entire Big Data processing infrastructure that should be analyzed for these threats.






