How to download, configure and run a mapReduce program In












31 Slides4.42 MB
How to download, configure and run a mapReduce program In a cloudera VM Presented By: 1 Mehakdeep Singh 8868237 Amrit Singh Chaggar 8868228 Ranjodh Singh 8740179
2 Outline Cloudera Introduction Download and Configuration MapReduce Implementation
3 Cloudera - Introduction Cloudera provides a powerful data platform that enables enterprises to manage their rapidly increasing volume and variety of data. It provides products and solutions which enable: To deploy and manage Apache Hadoop and related projects. To manipulate and analyze your data To keep that data secured and protected
4 Cloudera – Products and Tools CDH Cloudera Distribution Hadoop is open-source Apache Hadoop distribution and other related open-source projects, including Cloudera Impala and Cloudera Search. Cloudera Manager It is an end-to-end application for managing CDH clusters. It automates the installation process and reduces the deployment time from weeks to minutes. Cloudera Navigator It is a fully integrated data management tool for the Hadoop platform. Audit data access and verify access privileges
5 CDH It is the complete, tested, and popular distribution of Apache Hadoop. It provides: Flexibility Integration Security Scalability High availability QuickStarts for CDH 5.8 Cloudera QuickStart VM (Single Node Cluster) make it easy to quickly get hands on CDH for testing, demo and self learning purposes. It includes a tutorial, sample data and scripts for getting started.
6 Download and Configuration Prerequisites: These 64-bit VMs require a 64-bit host OS and a virtualization product that can support a 64-bit guest OS. To use a VMware VM, you must use a player compatible with WorkStation 8.x or higher: Player 4.x or higher Fusion 4.x or higher The amount of RAM required by VM to run CDH 5 is 4 GB.
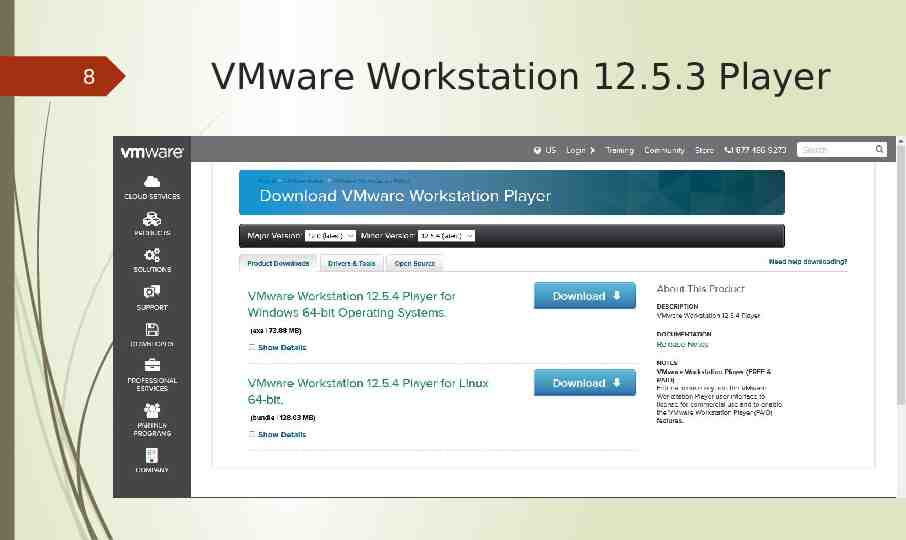
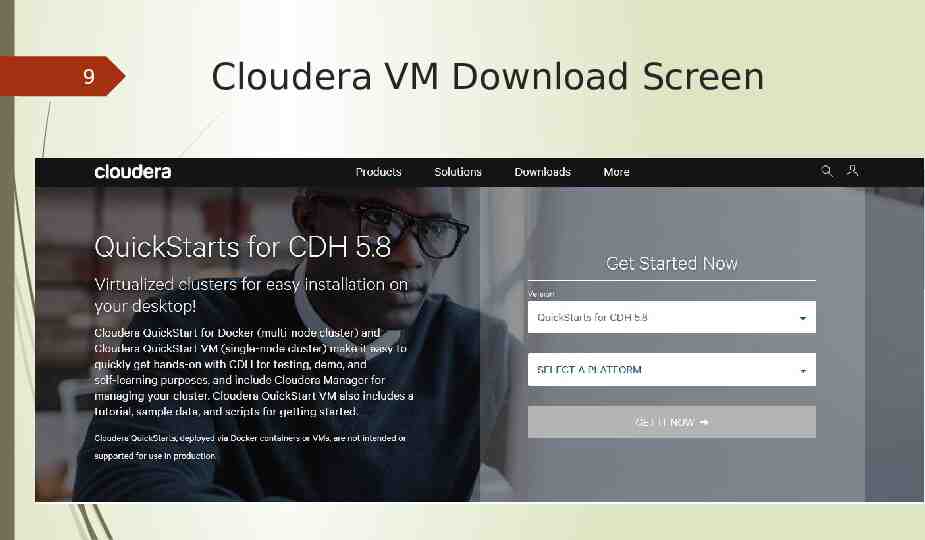
7 Download and Configuration Version used: VMware Workstation 12.5.3 Player for Windows 64-bit Operating Systems. Download Link https://my.vmware.com/en/web/vmware/free#desktop end user computing /vmware workstation player/12 0 Cloudera version used is Quickstarts for CDH 5.8 Download Link https://www.cloudera.com/downloads/quickstart vms/5-8.html NOTE: Make sure that Virtualization is enabled in BIOS settings in case of Windows.
8 VMware Workstation 12.5.3 Player
9 Cloudera VM Download Screen
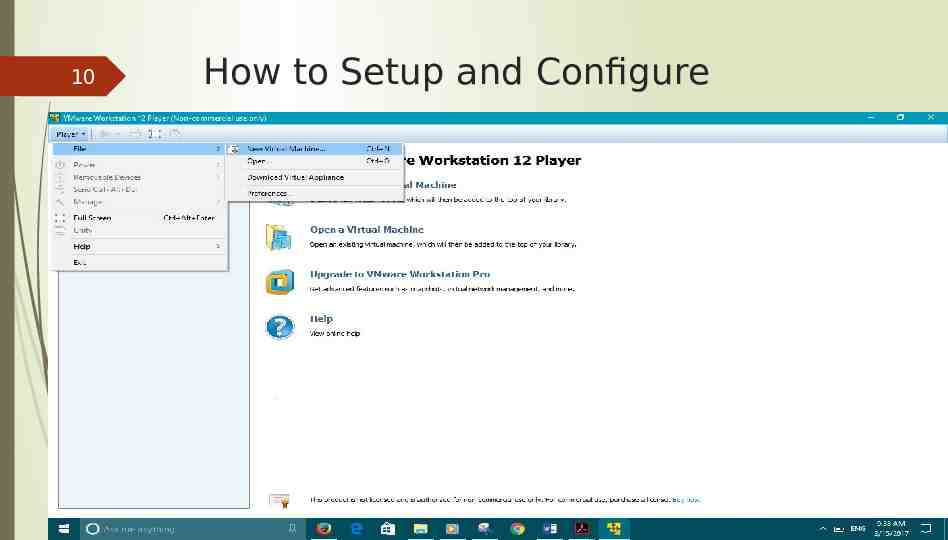
10 How to Setup and Configure
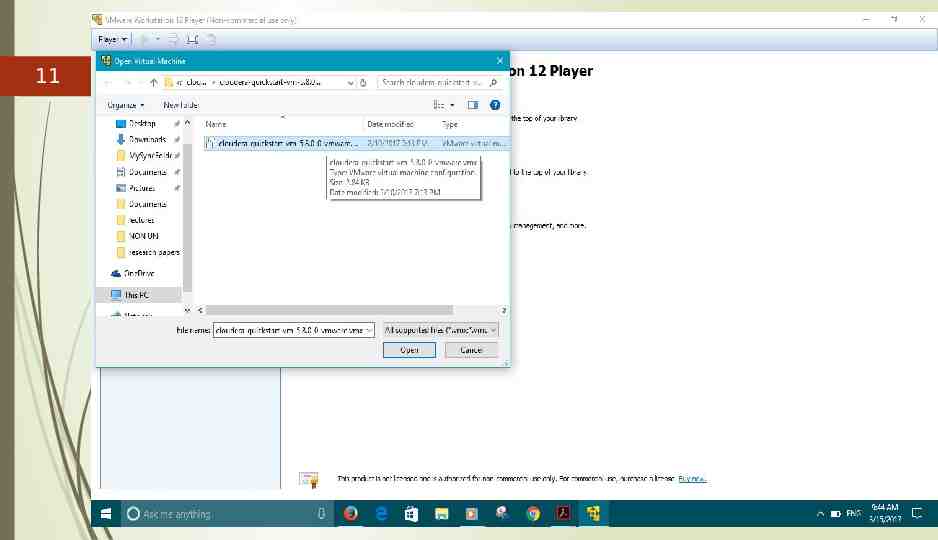
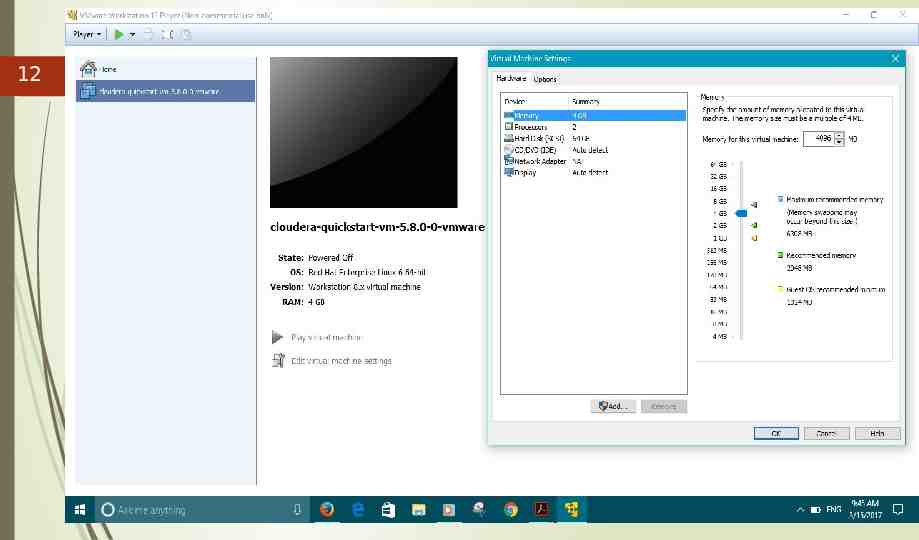
11
12
1 3
14
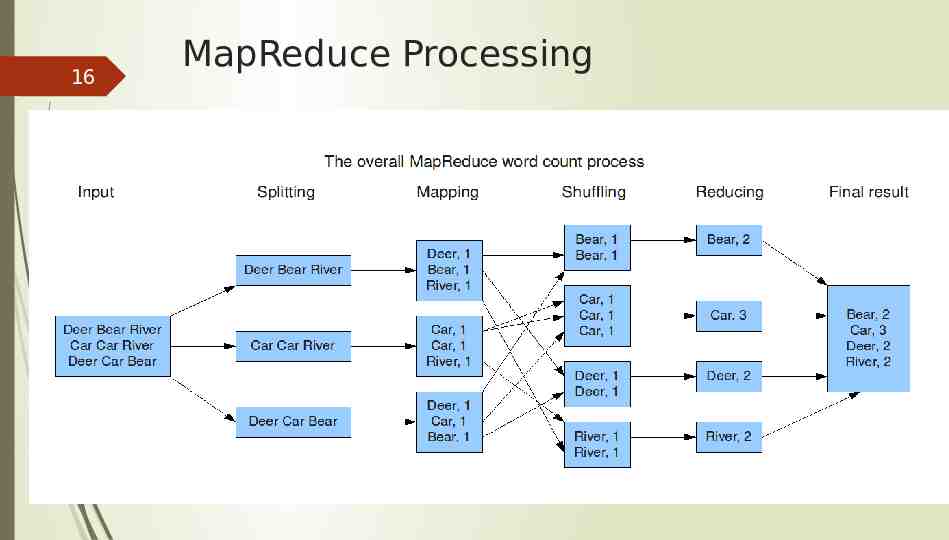
15 MapReduce A MapReduce job splits a large data set into independent chunks and organizes them into key, value pairs for parallel processing. This parallel processing improves the speed and reliability of the cluster, returning solutions more quickly and with greater reliability. The Map function divides the input into ranges by the InputFormat and creates a map task for each range in the input. The JobTracker distributes those tasks to the worker nodes. The output of each map task is partitioned into a group of key-value pairs for each reduce. The Reduce function then collects the various results and combines them to answer the larger problem that the master node needs to solve. Each reduce pulls the relevant partition from the machines where the maps executed, then writes its output back into HDFS. Thus, the reduce is able to collect the data from all of the maps for the keys and combine them to solve the problem.
16 MapReduce Processing
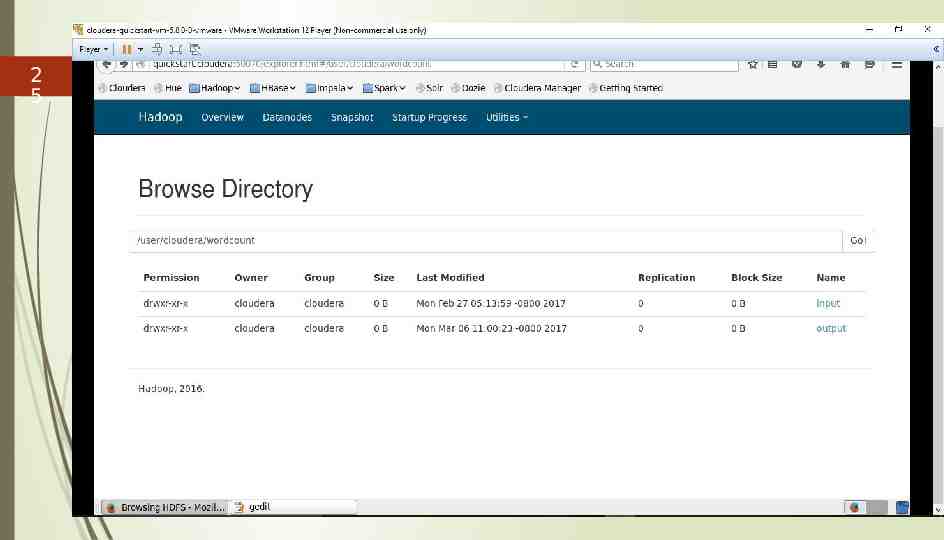
17 How to run MapReduce program 1) Create the input and output locations in hdfs by using the following commands. sudo su hdfs // to access hdfs. By default it is cloudera Hadoop fs -mkdir /user/cloudera // creates folder cloudera within user folder hadoop fs -chown cloudera /user/cloudera // changes ownership of user/cloudera to cloudera exit // exits bash hadoop fs -mkdir /user/cloudera/wordcount /user/cloudera/wordcount/input This creates two folders. 1. wordcount in cloudera 2. input in wordcount
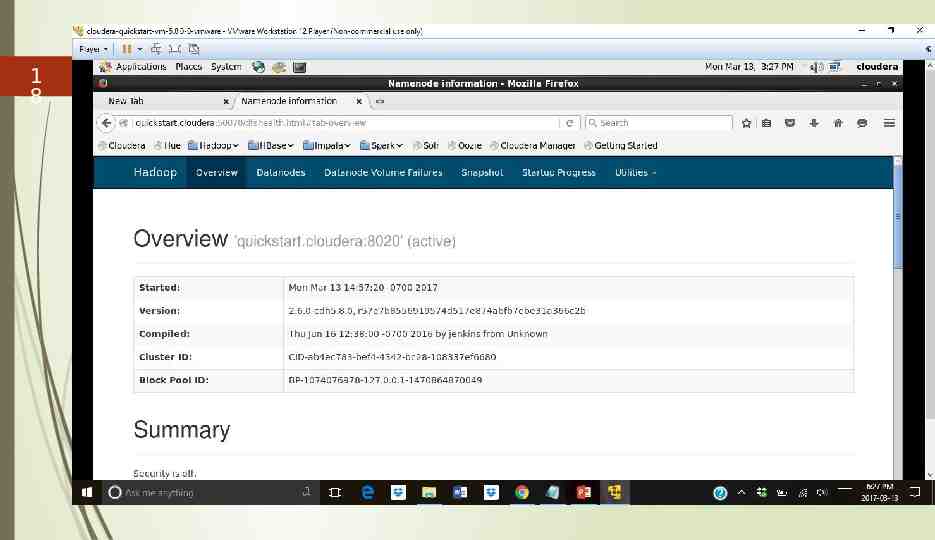
1 8
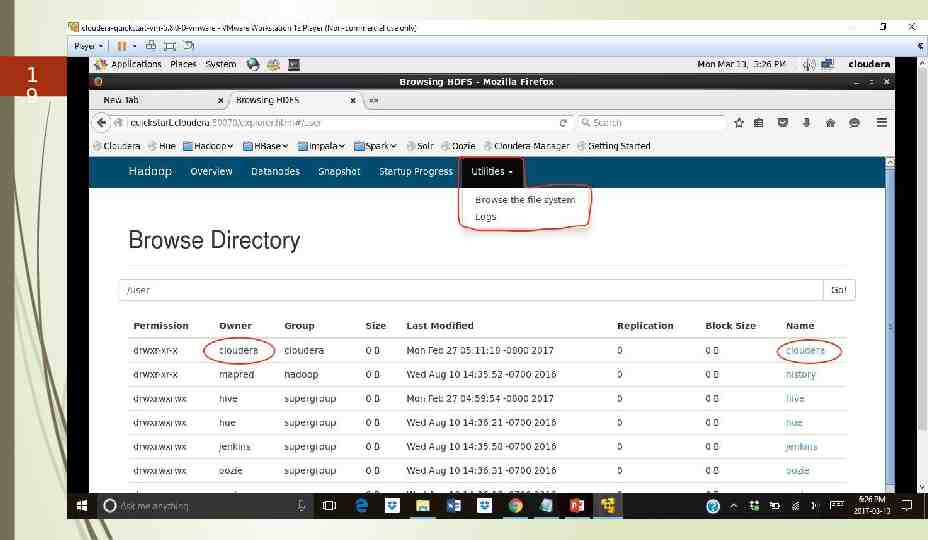
1 9
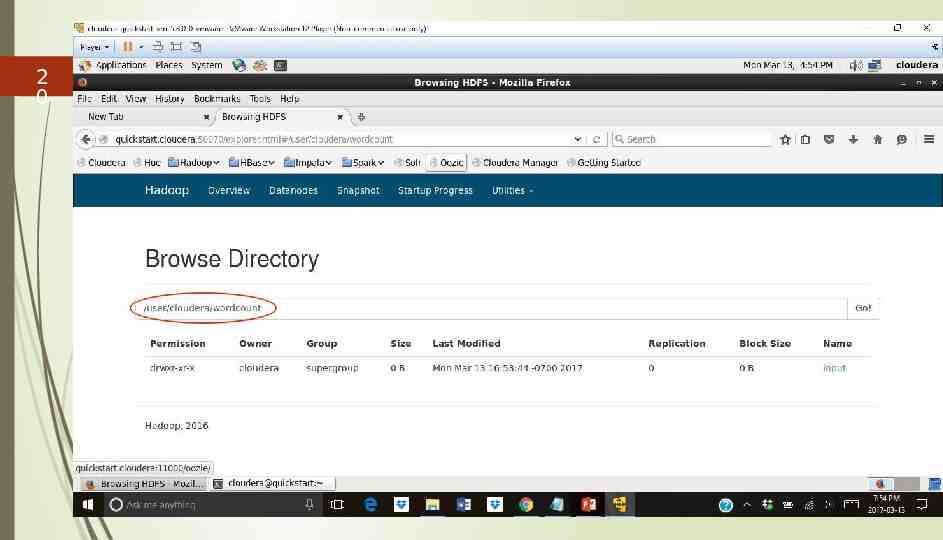
2 0
21 Next step is creating the input files hadoop fs -put file* /user/cloudera/wordcount/input //to put the files from Local storage to HDFS cd /usr/lib/hadoop-mapreduce/ contains files including Wordcount // change the directory to /Hadoopmapreduce. This folder some sample jar the one for
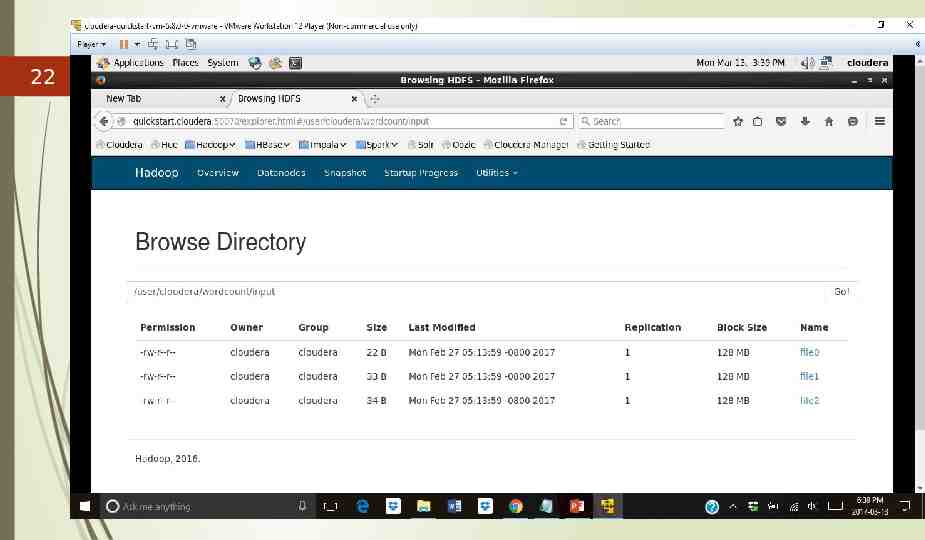
22
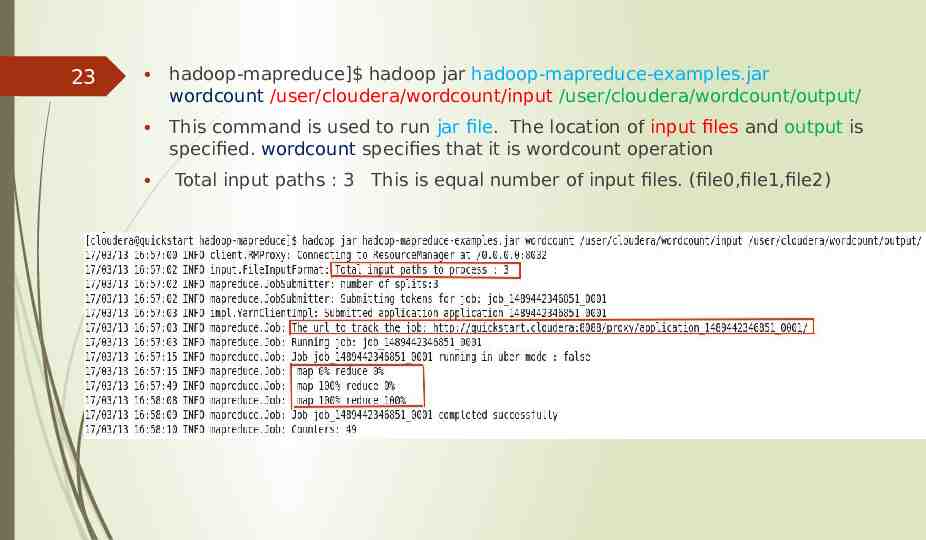
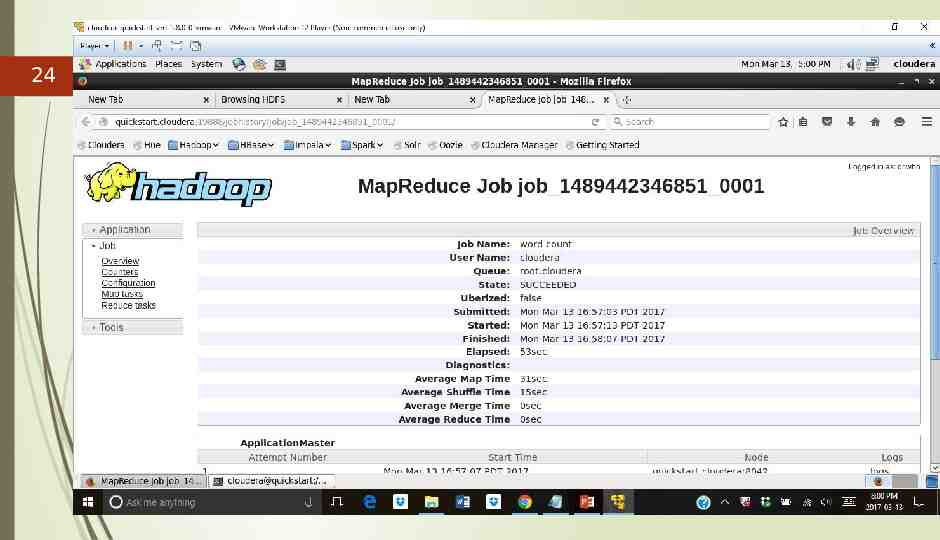
23 hadoop-mapreduce] hadoop jar hadoop-mapreduce-examples.jar wordcount /user/cloudera/wordcount/input /user/cloudera/wordcount/output/ This command is used to run jar file. The location of input files and output is specified. wordcount specifies that it is wordcount operation Total input paths : 3 This is equal number of input files. (file0,file1,file2)
24
2 5
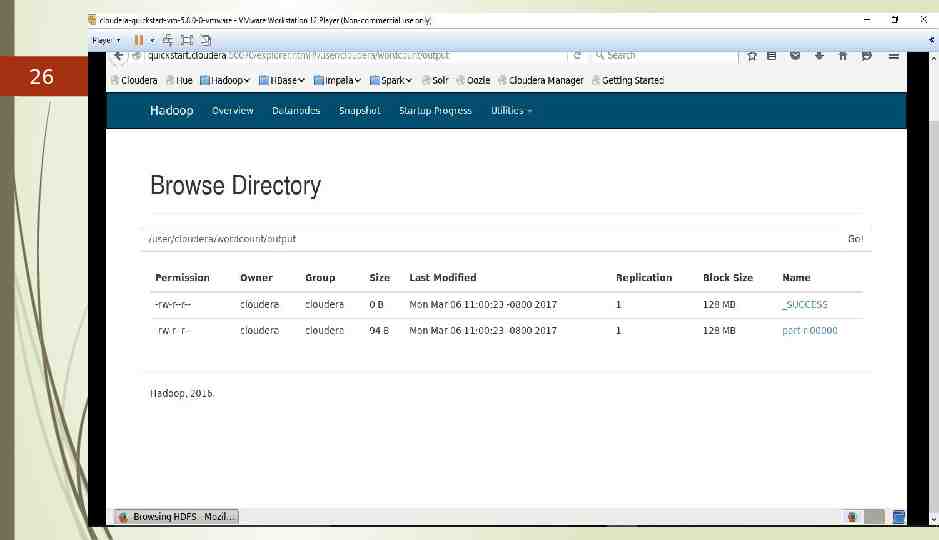
26
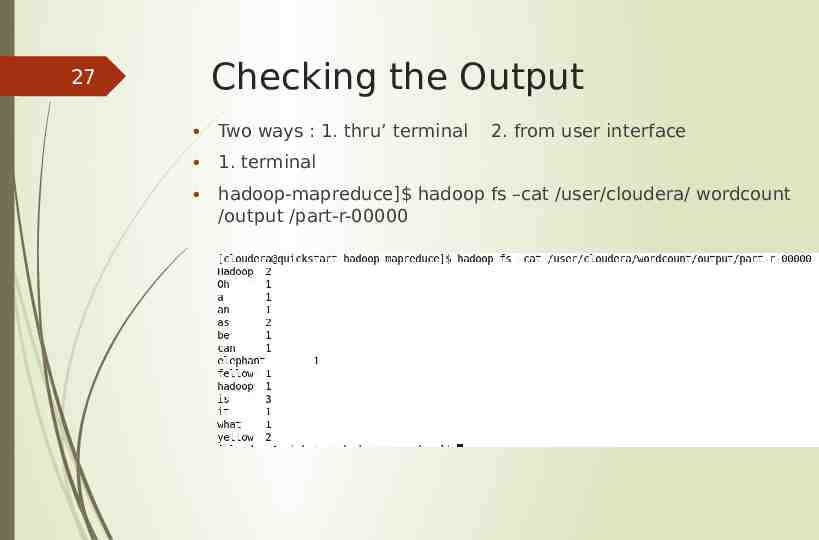
27 Checking the Output Two ways : 1. thru’ terminal 2. from user interface 1. terminal hadoop-mapreduce] hadoop fs –cat /user/cloudera/ wordcount /output /part-r-00000
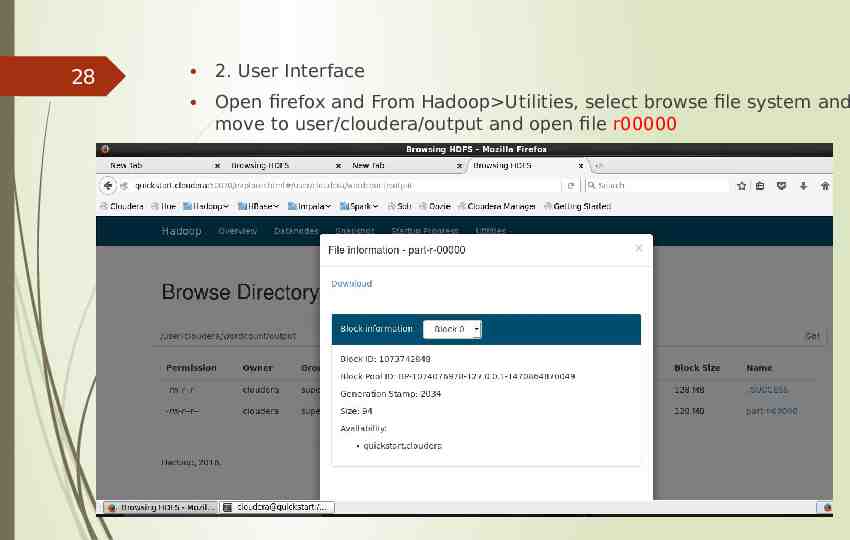
28 2. User Interface Open firefox and From Hadoop Utilities, select browse file system and move to user/cloudera/output and open file r00000
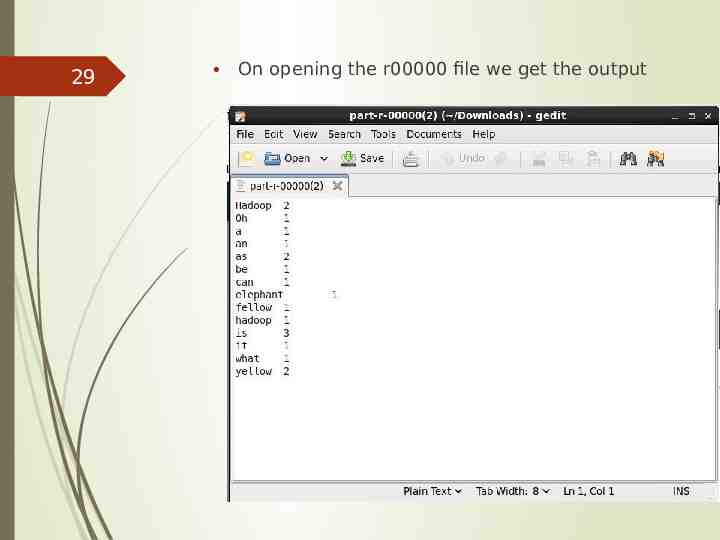
29 On opening the r00000 file we get the output
30 References https://my.vmware.com/en/web/vmware/free#desktop end user comput ing/vmware workstation player/12 0 https://www.cloudera.com/downloads/quickstart vms/5-8.html https://www.cloudera.com/documentation/enterprise/latest/topics/cloude ra quickstart vm.html#xd 583c10bfdbd326ba-3ca24a24-13d80143249-7f9d https://www.cloudera.com/documentation/other/tutorial/CDH5/topics/ht usage.html
31






