Datenbanken zur Entscheidungsunterstützung Data Warehousing Prof. Dr.



















24 Slides163.50 KB
Datenbanken zur Entscheidungsunterstützung Data Warehousing Prof. Dr. T. Kudraß
Einführung Zunehmender Bedarf nach Analyse aktueller und historischer Daten – Identifizierung interessanter Patterns – Entscheidungsfindung (Decision Support) zur Unterstützung von Business-Strategien (z.B. Marketing) Schwerpunkt liegt auf komplexer, interaktiver Analyse sehr großer Datenmengen – Integration von Daten aus allen Teilen des Unternehmens – Natur der Daten ist statisch (keine Updates) On-Line Analytic Processing (OLAP) – Lange Lese-Transaktionen On-line Transaction Processing (OLTP) – Traditionelle Verarbeitung Integration von OLAP-Features in DBMS (Zusammenwachsen beider Technologien) Angebot eigenständiger Decision Support-Produkte Prof. Dr. T. Kudraß
Drei Komplementäre Trends Data Warehousing: Konsolidieren von Daten aus vielen Quellen in einem großen Repository – Laden, periodische Synchronisation der Replikate – Syntaktische Integration (z.B. Datenformate) – Semantische Integration OLAP: – Komplexe SQL-Queries und Views – Queries basieren auf Spreadsheet-artigen Operationen und “mehrdimensionaler” Sicht der Daten – Interaktive und “online” Anfragen Data Mining: – Suche nach interessanten Trends und Abweichungen (wird hier nicht näher behandelt!) Prof. Dr. T. Kudraß
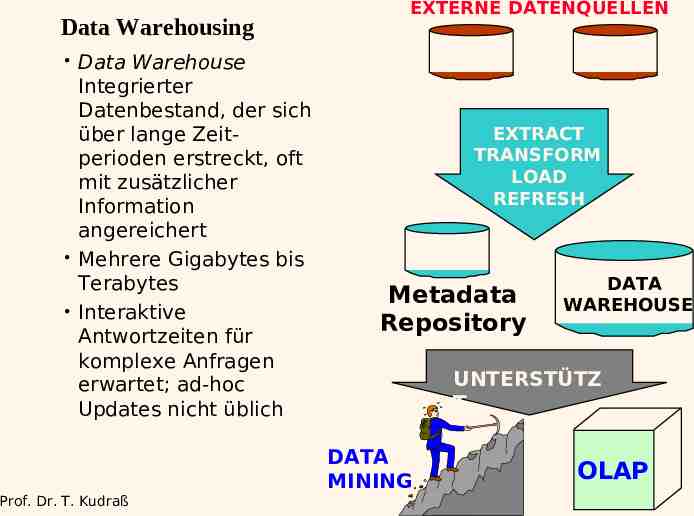
Data Warehousing Data Warehouse Integrierter Datenbestand, der sich über lange Zeitperioden erstreckt, oft mit zusätzlicher Information angereichert Mehrere Gigabytes bis Terabytes Interaktive Antwortzeiten für komplexe Anfragen erwartet; ad-hoc Updates nicht üblich EXTERNE DATENQUELLEN EXTRACT TRANSFORM LOAD REFRESH Metadata Repository UNTERSTÜTZ T DATA MINING Prof. Dr. T. Kudraß DATA WAREHOUSE OLAP
Aufgaben beim Warehousing Semantische Integration: Beim Bezug von Daten aus unter-schiedlichen Quellen, sind alle Arten von Heterogenitäten zu beseitigen, z.B. – Verschiedene Währungen und Maßeinheiten – Unterschiede in den Schemas – Verschiedene Wertebereiche Heterogene Quellen: Zugriff auf Daten in unterschiedlichsten Formaten und Repositories – Möglichkeiten der Replikation ausnutzen Load, Refresh, Purge: – Daten müssen ins Warehouse geladen werden (Load) – Daten müssen periodisch aktualisiert werden (Refresh) – Veraltete Daten müssen entfernt werden (Purge) Metadata-Management: Verwaltung der Informationen über Daten im Warehouse (Quellen, Ladezeit, Konsistenzanforderungen etc.) Prof. Dr. T. Kudraß
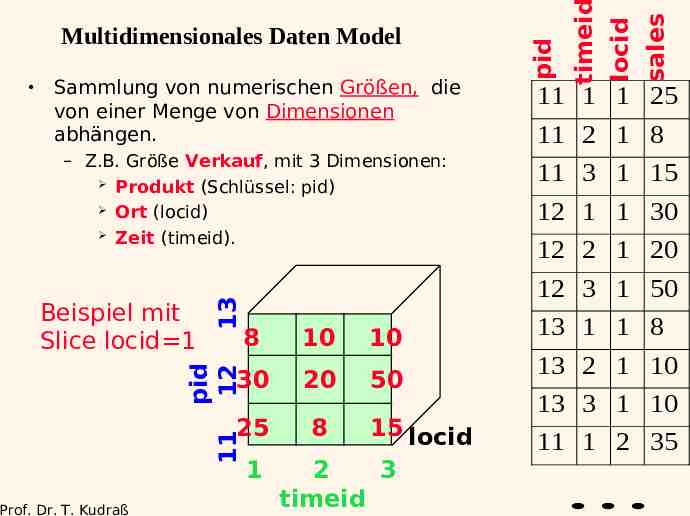
8 10 10 30 20 50 25 8 11 Prof. Dr. T. Kudraß 11 1 1 25 11 2 1 8 11 3 1 15 12 1 1 30 12 2 1 20 12 3 1 50 pid 12 Beispiel mit Slice locid 1 13 – Z.B. Größe Verkauf, mit 3 Dimensionen: Produkt (Schlüssel: pid) Ort (locid) Zeit (timeid). locid sales Sammlung von numerischen Größen, die von einer Menge von Dimensionen abhängen. timeid pid Multidimensionales Daten Model 1 15 locid 2 3 timeid 13 1 1 8 13 2 1 10 13 3 1 10 11 1 2 35
MOLAP vs. ROLAP MOLAP Physische Speicherung multidimensionaler Daten in einem (diskresidenten, persistenten) Array gespeichert ROLAP Physische Speicherung multidimensionaler Daten in Relationen Fakten-Tabelle Hauptrelation, die Dimensionen mit einer Größe verbindet Beispiel: Sales (pid, timeid, locid, sales) Dimensionen-Tabelle Assoziiert mit einer Dimension, enthält zusätzliche Attribute Beispiel: Products (pid, pname, category, price) Locations (locid, city, state, country) Times (timeid, date, week, month, quarter, year, holiday flag) Fakten-Tabellen sind viel kleiner als DimensionenTabellen Prof. Dr. T. Kudraß
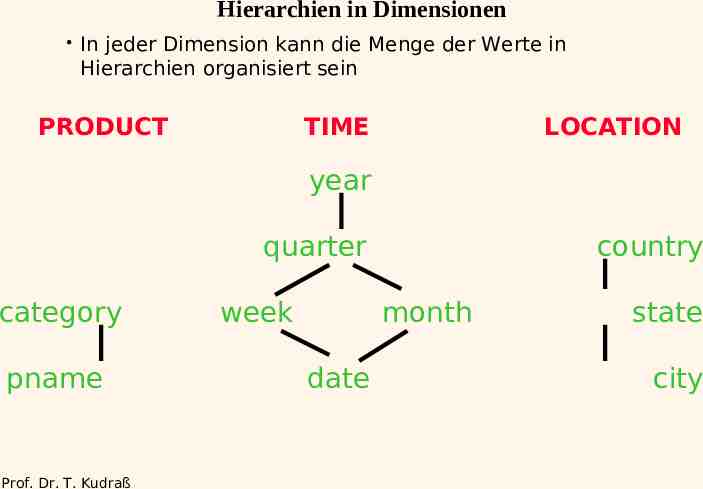
Hierarchien in Dimensionen In jeder Dimension kann die Menge der Werte in Hierarchien organisiert sein PRODUCT TIME LOCATION year quarter category pname Prof. Dr. T. Kudraß week country month date state city
OLAP-Queries Beeinflußt durch SQL und durch Spreadsheets Häufige Operation: Aggregation einer Größe über eine oder mehrere Dimensionen – Bestimme den Gesamtverkauf. – Bestimme den Gesamtverkauf für jede Stadt oder für jedes Bundesland. – Finde die Top-5 Produkte, gemessen am Gesamtverkauf. Roll-Up: Aggregation auf verschiedenen Stufen in einer Hierarchie einer Dimension – Beispiel: Gegeben sei der Gesamtverkauf pro Stadt Möglicher Roll-Up: Ermittle Gesamtverkauf pro Bundesland Drill-Down: Umgekehrte Operation zum Roll-Up – z.B.: Gegeben sei Gesamtverkauf pro Bundesland, Drill-Down möglich zur Ermittlung Gesamtverkauf pro Stadt – Drill-Down auch in einer anderen Dimension möglich, z.B. um den Gesamtverkauf pro Produkt für jedes Bundesland zu ermitteln Prof. Dr. T. Kudraß
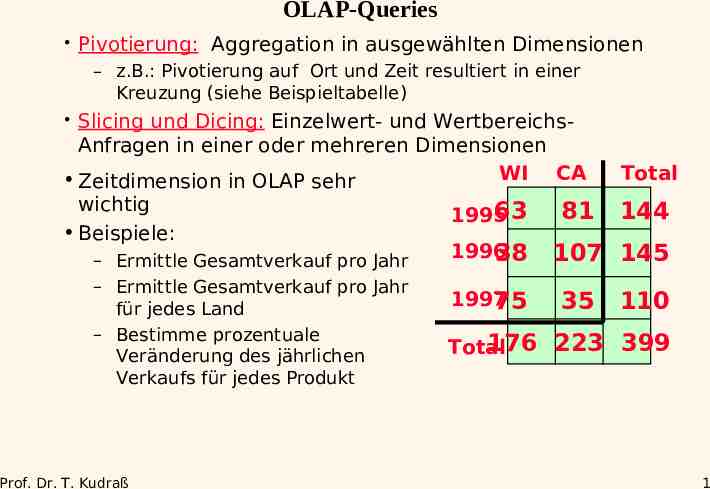
OLAP-Queries Pivotierung: Aggregation in ausgewählten Dimensionen – z.B.: Pivotierung auf Ort und Zeit resultiert in einer Kreuzung (siehe Beispieltabelle) Slicing und Dicing: Einzelwert- und WertbereichsAnfragen in einer oder mehreren Dimensionen WI CA Zeitdimension in OLAP sehr wichtig Beispiele: – Ermittle Gesamtverkauf pro Jahr – Ermittle Gesamtverkauf pro Jahr für jedes Land – Bestimme prozentuale Veränderung des jährlichen Verkaufs für jedes Produkt Prof. Dr. T. Kudraß 63 1995 1996 38 1997 75 81 Total 144 107 145 35 110 176 223 399 Total 1
Vergleich mit SQL-Queries Die Kreuzung von Tabellen, die durch Pivotierung entsteht, kann auch durch eine Menge von SQL-Anfragen berechnet werden: Einträge SELECT SUM(S.sales) FROM Sales S, Times T, Locations L WHERE S.timeid T.timeid AND S.locid L.locid GROUP BY T.year, L.state SELECT SUM(S.sales) SELECT SUM(S.sales) FROM Sales S, Times T FROM Sales S, Location L WHERE S.timeid T.timeid WHERE S.locid L.locid GROUP BY T.year GROUP BY L.state Untere Zeile Prof. Dr. T. Kudraß Rechte Spalte 1
CUBE-Operator Verallgemeinerung des gezeigten Beispiels: – Bei k Dimensionen gibt es 2 k mögliche SQL GROUP BY Queries, die durch Pivotierung auf einer Teilmenge der Dimensionen erzeugt werden können CUBE pid, locid, timeid BY SUM Sales – Äquivalent zum Roll-Up von Sales auf allen 8 Teilmengen der Menge {pid, locid, timeid} – Jeder Roll-Up korrespondiert mit einer SQL-Query der Form: Gegenwärtig viel Anstrengungen zur Optimierung des CUBEOperators Prof. Dr. T. Kudraß SELECT SUM(S.sales) FROM Sales S GROUP BY grouping-list 1
Datenbankentwurf für OLAP TIMES PRODUCTS timeid dat wee mont quarte yea holiday fla e k h r r g (Fakten-Tabelle) pid timei locid sale SALES d s LOCATIONS pid pnam categor pric locid city state countr e y e y Fakten-Tabelle in BCNF; Dimensionen-Tabelle unnormalisiert – Dimensionen-Tabellen sind klein – Updates/Inserts/Deletes in Dimensionen-Tabelle selten – Deshalb Anomalien weniger bedeutsam als gute Performance Diese Art von Schema in OLAP-Anwendungen sehr gebräuchlich, genannt Star Schema Berechnung des Joins auf diesen Relationen: Star Join Prof. Dr. T. Kudraß 1
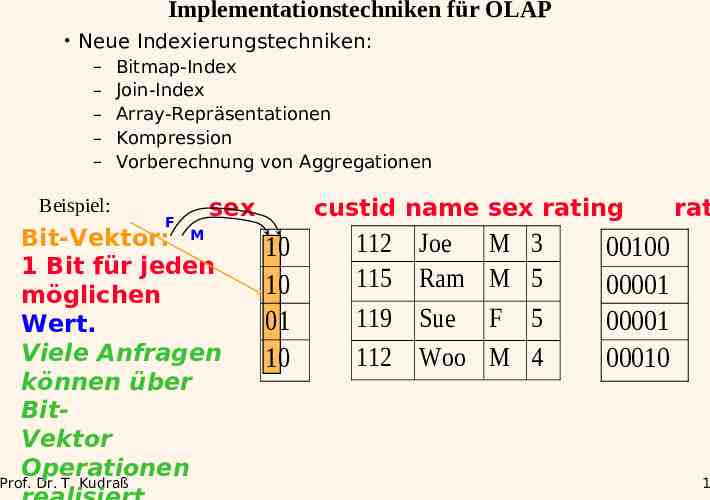
Implementationstechniken für OLAP Neue Indexierungstechniken: – – – – – Bitmap-Index Join-Index Array-Repräsentationen Kompression Vorberechnung von Aggregationen Beispiel: F sex Bit-Vektor: M 1 Bit für jeden möglichen Wert. Viele Anfragen können über BitVektor Operationen Prof. Dr. T. Kudraß custid name sex rating 10 10 01 10 112 115 119 112 Joe Ram Sue Woo M M F M 3 5 5 4 rat 00100 00001 00001 00010 1
Join-Index Betrachte den Join von Sales, Products, Times, and Locations, vielleicht noch mit zusätzlicher Selektionsbedingung (z.B. country “USA”) – Ein Join-Index kann zur Beschleunigung solcher Joins konstruiert werden. – Der Index enthält [s,p,t,l] , wenn es Tupel gibt (mit sid) s in Sales, p in Products, t in Times and l in Locations, die die Join(und evtl. auch Selektions-) Bedingung erfüllen. Problem: Anzahl der Join-Indexe kann schnell wachsen – Passiert, wenn mehrere Spalten in jeder Dimensions-Tabelle an Selektionen und Joins mit der Fakten-Tabelle beteiligt – Dieses Problem wird durch eine Variante des Join-Index adressiert: – Für jede Spalte mit einer zusätzlichen Selektionsbedingung (z.B. Land), baue einen Index mit [c,s], wenn ein Tupel der Dimensions-Tabelle mit Wert c in der Selektions-Spalte mit einem Tupel aus Sales mit sid s joint – Wenn Indexe Bitmaps sind: Bitmapped Join Index. Prof. Dr. T. Kudraß 1
Bitmapped Join-Index TIMES PRODUCTS timeid date wee monthquarte yea holiday fla k r r g (Fakten-Tabelle) SALES pid timei locid sale d s LOCATIONS pid pnam categor pric e y e locid city state countr y Betrachte eine Query mit Bedingung price 10 and country “USA”: – Angenommen, Tupel (mit sid) s in Sales joint mit einem Tupel p mit Preis 10 und einem Tupel l mit country “USA”. Es gibt zwei Join-Indexe: 1.) Enthält [10,s]. 2.) Enthält [USA,s]. Durchschnitt dieser Indexe verrät, welche Sales-Tupel zum Join gehören und die gegebene Selektion erfüllen Prof. Dr. T. Kudraß 1
Views und Decision Support OLAP-Anfragen sind typischerweise Aggregationen – Vorberechnung (Precomputation) ist wesentlich für interaktive Antwortzeit – Der CUBE ist praktisch eine Sammlung von AggregatAnfragen, mit Vorberechnung als wichtigem Lösungsansatz – Zu lösendes Problem: Was läßt sich am besten vorberechnen mit einem begrenzten Speicherplatzumfang, um vorberechnete Ergebnisse zu speichern? Data Warehouse kann als eine Sammlung von asynchron replizierten Tabellen und periodisch aktualisierten Views angesehen werden – Führt zu einem großen Interesse am Problem der View Maintenance – View Maintenance: Konsistenzkontrolle zwischen Sichten und den zugrunde liegenden Basistabellen Prof. Dr. T. Kudraß 1
View Modification (Berechnung On Demand) View CREATE VIEW RegionalSales(category,sales,state) AS SELECT P.category, S.sales, L.state FROM Products P, Sales S, Locations L WHERE P.pid S.pid AND S.locid L.locid Query SELECT R.category, R.state, SUM(R.sales) FROM RegionalSales AS R GROUP BY R.category, R.state SELECT R.category, R.state, SUM(R.sales) Modifizierte FROM (SELECT P.category, S.sales, L.state Query FROM Products P, Sales S, Locations L WHERE P.pid S.pid AND S.locid L.locid) AS R GROUP BY R.category, R.state Schachtelung von FROM in SQL:1999 möglich Prof. Dr. T. Kudraß 1
View Materialization (Vorberechnung) Angenommen, wir berechnen RegionalSales und speichern dies mit einem geclusterten B Baum-Index auf [category,state,sales]. – Somit kann die eben gestellte Anfrage durch einen Scan nur auf dem Index bearbeitet werden SELECT R.state, SUM(R.sales)SELECT R.state, SUM(R.sales) FROM RegionalSales R FROM RegionalSales R WHERE R.category “Laptop”WHERE R. state “Wisconsin” GROUP BY R.state GROUP BY R.category Index auf vorberechneter View sehr hilfreich! Prof. Dr. T. Kudraß Index weniger sinnvoll (Scan auf der gesamten Blatt-Ebene erforderlich) 1
Fragen bei Materialisierung von Sichten Welche Sichten sollten materialisiert werden, welche Indexe sollten auf den vorberechneten Ergebnissen gebaut werden? Mit einer Anfrage und einer Menge materialisierter Sichten: Können wir die materialisierten Sichten benutzen, um die Anfrage zu beantworten? Wie häufig sollten wir materialisierte Sichten aktualisieren (Refresh), um sie mit den zugrundeliegenden Tabellen konsistent zu machen? – Probleme beim inkrementellen Refresh? Refresh einfach bei neu hinzugekommenen Tupeln in der Basisrelation, problematisch bei gelöschten Tupeln in der BR Unterschiedliche View Maintenance Policies möglich: – Lazy: Sicht wird aktualisiert, wenn zugehörige Anfrage aufgerufen wird (falls nicht schon Konsistenz vorhanden ist) – Periodisch: Materialisierte Sichten in festen Zeitabständen aktualisiert (Snapshots) – Forced: Aktualisierung nach einer bestimmten Zahl von Änderun-gen in der Basistabelle Prof. Dr. T. Kudraß 2
Interaktive Queries: Alternative zu View Materialization Top N Queries: Finde die ersten N Tupel des AnfrageErgebnisses Beispiel: Finden die 10 billigsten Autos! Wäre gut, wenn die DB die Kostenberechnung für alle Autos vermeiden könnte vor dem Sortieren, um die billigsten 10 herauszufinden – Idee: Schätze einen Kosten-Grenzwert c, so daß die 10 billigsten Autos allesamt weniger als c kosten, aber auch nicht viel mehr weniger. Füge dann die Selektionsbedingung cost c hinzu und führe die Anfrage aus. Prof. Dr. T. Kudraß Falls Schätzwert richtig, kann die Berechnung für Autos, die mehr als c kosten, vermieden werden Bei falscher Schätzung muß die Selektion zurückgesetzt und die Original-Anfrage erneut berechnet werden 2
Top N Queries SELECT P.pid, P.pname, S.sales FROM Sales S, Products P WHERE S.pid P.pid AND S.locid 1 AND S.timeid 3 ORDER BY S.sales DESC OPTIMIZE FOR 10 ROWS SELECT P.pid, P.pname, S.sales FROM Sales S, Products P WHERE S.pid P.pid AND S.locid 1 AND S.timeid 3 AND S.sales c ORDER BY S.sales DESC OPTIMIZE FOR Konstrukt ist nicht Bestandteil von SQL:1999, wird aber in kommerziellen DBMS angeboten (DB2, Oracle) Cut-off Wert c wird vom Optimierer gewählt Prof. Dr. T. Kudraß 2
Interaktive Queries: Online-Aggregation Online-Aggregation: Betrachte eine Aggregat-Query wie z.B. “Bestimme den Durchschnittsverkauf pro Bundesland“: SELECT L.state, AVG(S.sales) FROM Sales S, Location L WHERE S.locid L.locid GROUP BY L.state Können wir dem Benutzer einige Informationen liefern vor der genauen Berechnung des Durchschnitts für alle Bundesländer? – Wir können den aktuellen “laufenden Durchschnitt” für jedes Bundesland zeigen bei Voranschreiten der Berechnung – Noch besser: Nutzung von statistischen Techniken und Beispiel-Tupeln zur Aggregation anstelle eines einfachen Durchscannens der aggregierten Tabelle – Definition von Grenzen wie z.B. “Durchschnitt für Wisconsin ist 2000 102 mit 95% Wahrscheinlichkeit Wir sollten auch nicht-blockierende Algorithmen verwenden (also z.B. keinen Merge Sort). Blockieren: Keine Ausgabe von Tupeln, bevor nicht alle Eingabe-Tupel verarbeitet sind! Prof. Dr. T. Kudraß 2
Zusammenfassung Decision Support ist schnell wachsendes Teilgebiet von Datenbanken Beinhaltet die Erzeugung von Data Warehouses große konsolidierte Data Repositories Warehouses verwenden komplizierte Analyse-Techniken: – komplexe SQL-Anfragen – “multidimensionale” OLAP-Anfragen (beeinflußt durch SQL und Spreadsheets) Neue Techniken erforderlich für: – – – – Datenbank-Entwurf Indexierung View Maintenance Interaktive Queries Prof. Dr. T. Kudraß 2






