Why Rational chose DB2 pureXML for Jazz REST Services and






























41 Slides2.40 MB
Why Rational chose DB2 pureXML for Jazz REST Services and SOA solutions Edison Ting, Advanced Xml Technologies Architect, IBM, [email protected] Simon Johnston, Senior Technical Staff Member, IBM Rational, [email protected] Session Number TLU-1533
Rational Jazz & JRS 2
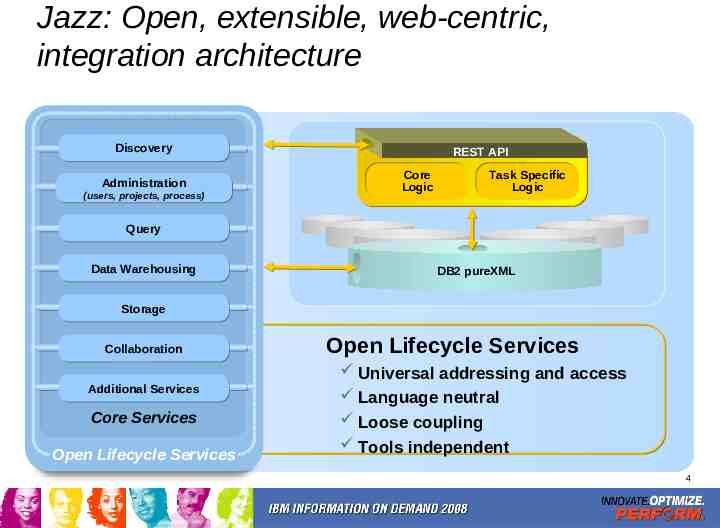
What is Rational Jazz ? An integrated development environment for the whole software lifecycle. Supports heterogeneous data independent of tools. Supports analysis, querying, and reporting of data through standard interfaces. Integrates people, tasks, and data that are distributed across time, place, and organizations. Open Lifecycle Services REST API DB2 pureXML 3
Jazz: Open, extensible, web-centric, integration architecture Discovery Administration (users, projects, process) REST API Core Logic Task Specific Logic Query Data Warehousing DB2 pureXML Storage Collaboration Additional Services Core Services Open Lifecycle Services Open Lifecycle Services Universal addressing and access Language neutral Loose coupling Tools independent 4
Rational Jazz Features: Integration of people, tasks and data across the whole software life-cycle across time, place and organizations. Tools should be invisible: – Users focus on tasks and data. – Tools provide role and task appropriate views. No boundaries between people: – Data and tasks from one tool are seamlessly visible in others. Creative Collaboration is enhanced. Non-creative procedures are automated. Governance is strong but unobtrusive. Security models address organizational and role distribution 5
What is JRS? Defines a set of RESTful web services for storage, indexing, search and query. JRS is the evolution of the Jazz Platform to enable a completely RESTful API for storage of all resources. JRS is built from Jazz components and is a key part of the Jazz Team Server platform vision and the Open Services for Lifecycle Collaboration initiative. JRS is an embodiment of the Rational Architecture Principles have a goal of creating more Internet-native architecture for Rational products. 6
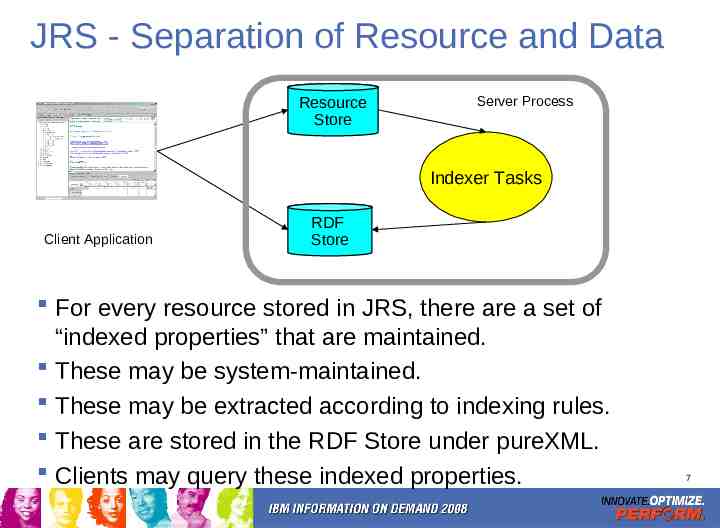
JRS - Separation of Resource and Data Resource Store Server Process Indexer Tasks Client Application RDF Store For every resource stored in JRS, there are a set of “indexed properties” that are maintained. These may be system-maintained. These may be extracted according to indexing rules. These are stored in the RDF Store under pureXML. Clients may query these indexed properties. 7
What does JRS provide? JRS provides application developers with a RESTful resource store that supports both simple resources and collections – A simple resource is one where the client chooses a URL and PUTs a representation to the server and the server will respond with the same representation on a later GET – A collection uses the Atom Syndication Format and Publishing Protocol to provide a resource which manages a collection of other resources (which may in turn be simple or collections) JRS provides an audit history on all resources, individual resource versions are URI addressable as is the entire history as a feed JRS provides indexers that are able to create queryable properties from common resource representations to support both structured query and full text search JRS provides a security model based upon Jazz Process where a server may be partitioned into separate projects and users can be assigned roles in specific projects 8
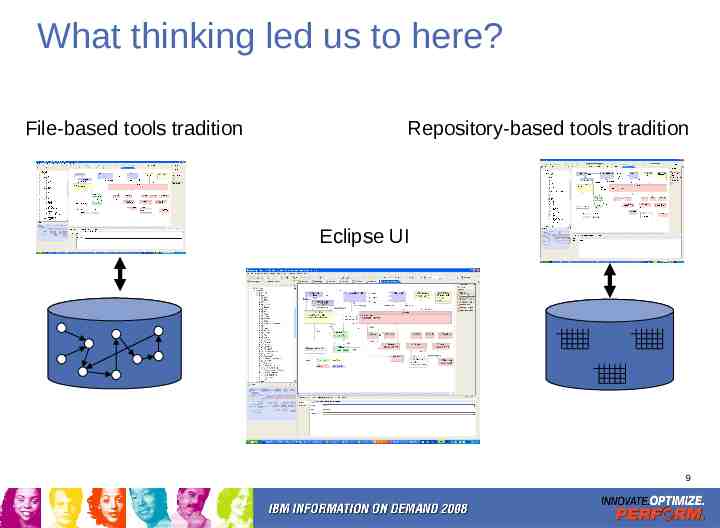
What thinking led us to here? File-based tools tradition Repository-based tools tradition Eclipse UI 9
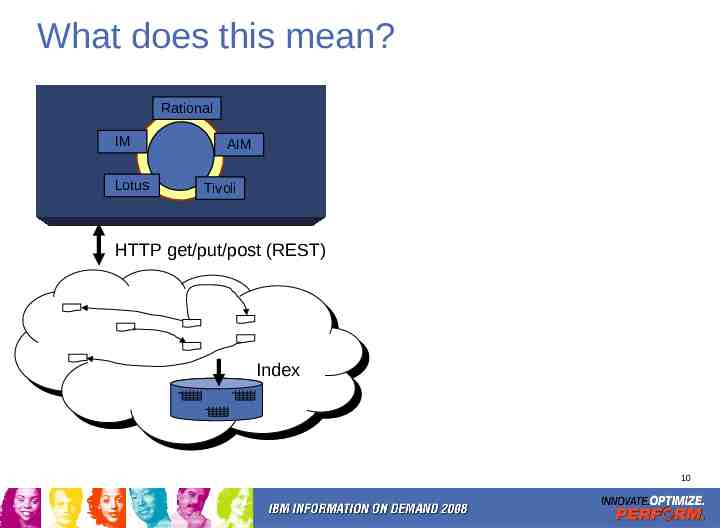
What does this mean? Rational IM Lotus AIM Tivoli HTTP get/put/post (REST) Index 10
A paradigm shift Before After Closed systems, special tricks Open systems, simplicity Data in files, rows Data are web resources Lists, trees, graphs Flat resource space with query, search Assume what’s at the end of a “link” Discover what’s at the end of a “link” Fixed “scope” of the UI No boundaries on UI Data formats are proprietary Data formats are open Data formats are fixed Data formats are extensible Passion for open systems and standards HTTP and ATOM/APP No “special tricks” – mixed clients and servers Published, standardized data formats (resource representations) Open, extensible [meta-]model through typeless URIs Client driven by data mime-types, not [meta-]model assumptions Rely on universal search and query, not fixed lists, trees, graphs 11
Hasn’t this been done (and failed) before? Many previous attempts at more integrated team software engineering environments – ADCycle, PCTE, – None particularly successful Naïve approach: – Assume integration around a database/repository – Design a data model for software engineering for the repository – Provide some sort of framework for tools to integrate around the repository 12
What are our assumptions ? You cannot get all the data in a single database/repository – But you do have to cross-link all the data wherever it is – And you have to be able to query the data wherever it is You cannot design a single data model – Individual teams customize – Communities can’t agree Frameworks are a two-edged sword. Powerful for some, but . – Constrain language and execution environments – Barrier to adoption – Difficult to mature and evolve – Tend to tightly couple components Process awareness brings another dimension Social network awareness brings yet another 13
Data not in a repository All data represented as resources on the internet – URLs, HTTP – no exceptions, no special stuff (e.g. “links”) All data access through HTTP GET/PUT/POST/DELETE Data formats defined as resource representations Resources cross-linked by putting url of one resource in another We like XML but not a requirement – JPEG, Java, other formats 14
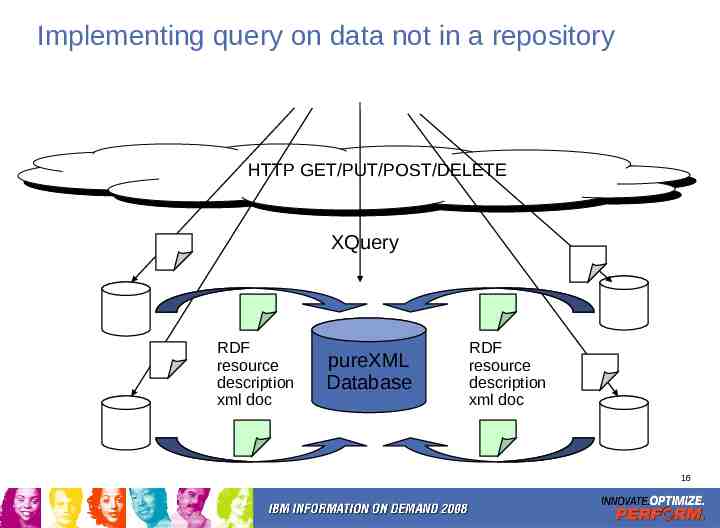
Query on data not in a repository We need real query, not just search – “Give me a list of all the new test cases that should be run on last night’s build” Query is enormously powerful – HTTP is like database CRUD on the internet – HTTP APP allows the internet to work like a universal hierarchical database – HTTP Query allows the internet to work like a universal relational (or better) datastore Static Database Schemas aren’t possible (we don’t know the data ahead of time) – How do you implement query without a fixed schema (and without complex administration)? 15
Implementing query on data not in a repository HTTP HTTPGET/PUT/POST/DELETE GET/PUT/POST/DELETE XQuery RDF resource description xml doc pureXML Database RDF resource description xml doc 16
Why a separate query server/database? Need to enable query across data in multiple servers/databases – Even if we could get to one server/database technology, we could not get to a single database because of customer environments and scenarios Need to keep query database separate from operational database – Need to keep operational schema private (evolution of function, e.g. versioning), but need to make query schema public (so you can write queries) – Need to isolate performance of operational store from performance impact of query Not all data is XML – E.g. JPEG 17
Don’t want a database schema, but do need joins. Database Schema constrains the data you can store and query – Things known ahead of time, things that don’t change shape Others recognize need for schema-less storage – E.g. Google BigTable, Amazon SimpleDB, but they don’t support joins DB2 PureXML is a thing of beauty – Does not require a schema – Supports rich XML Indexing and XQuery features – Solves perennial storage/query problems Query table RDF (xml column) rdf:description /rdf:description 18
Not a single data model Define representations of resources for “atomic” concepts – For developers: Requirement, use-case, actor, class, package, diagram, defect, change-set, build, milestone plan, test plan, test-case, test-result, deployment package etc. – For other stakeholders: process, program, task, organization unit, many more Typeless hrefs connect resources – Name the role/link, not the type Mime-type of retrieved resource determines processing, not assumption about “appropriate” type Result – A loosely-coupled federation of small data models – Resources from customized or alternative data models can substitute in the same resource graph – Use query rather than GET to find information about neighboring resources without understanding the resource representation (“summarizer” knew that) 19
Make Frameworks optional We don’t like mandating frameworks, but we want . – To avoid every product team implementing its own server infrastructure – A unified administration and backup experience for IBM products used singly and together What is a user? What is a project? How are resources secured? – Rich query across all data and all products – Standard collaboration features everywhere – Social network awareness, instant messaging, blogs, wikis, email integration, review/feedback/comment/annotate – Support for process enactment everywhere 20
JRS and pureXML 21
JRS Sample Resource Definition Resource album xmlns " http: // example .com/ xmlns / music " Definition name A Matter of Life and Death / name label EMI / label publisher Sanctuary Records / publisher JRS Resource producer Kevin Shirley / producer Specific Indexer engineer Martin Birch / engineer releasedYear 2006 / releasedYear artist / jazz / resources / musicdb / artists /artist -1 / artist JRS Index genre Rock / genre pureXML document genre Heavy Metal / genre and index. disk is "1" of "1"/ duration 72 :06 / duration track id "track -01" name Different World / name trackNumber 1 / trackNumber *JRS takes resource duration 10 :01 / duration writer / jazz / resources / musicdb / artists /artist -101 / writer aware definition files writer / jazz / resources / musicdb / artists /artist -102 / writer and run resource / track specific indexers. / album 22
JRS RDF Index Specification Resource Definition indexSpecification xmlns "" namespace JRS Resource " http: // example .com/ xmlns / music " Specific Indexer index element "/ album / name "/ Index element "/ album / releasedYear “ JRS Index objectType " dateTime "/ pureXML document index element "/ album / artist " and index. objectType "uri"/ index element "/ album / genre "/ index secondaryElement "/ album / track /@id" object "./ name "/ *JRS resource specific index secondaryElement "/ album / track /@id" object "./ trackNumber " objectType "int"/ indexers extract items / indexSpecification following the index specification, to build JRS resource indexes. 23
JRS Resource Index Documents rdf:Description xmlns:rdf " http: // www.w3.org /1999/02/22 - rdf -syntax -ns#" xmlns:dc " http: // purl .org/dc/ terms /" xmlns:jrs " http: // jazz .net/ xmlns /v0 .6" xmlns:ns " http: // example .com/ xmlns / music #" Resource Definition rdf:about "/ jazz / resources / musicdb / albums /album -1 " JRS Resource rdf:type rdf:resource " http: // example .com/ xmlns / music # album "/ Specific Indexer ns:name A Matter of Life and Death / ns:name ns:releasedYear rdf:datatype " http: // www.w3.org /2001/ XMLSchema # integer " 2006 / ns:releasedYear JRS Index ns:artist rdf:resource "/ jazz / resources / musicdb / artists /artist -1"/ pureXML document ns:genre Rock / ns:genre and index. ns:genre Heavy Metal / ns:genre / rdf:Description *JRS resource specific indexer builds RDF xml documents and stores rdf:Description them in pureXML. xmlns:rdf " http: // www.w3.org /1999/02/22 - rdf -syntax -ns#" These documents xmlns:ns " http: // example .com/ xmlns / music #" rdf:about "/ jazz / resources / musicdb / albums /album -1# track -01" describe the resources. ns:name Different World / ns:name ns:trackNumber rdf:datatype " http: // www.w3.org /2001/ XMLSchema # integer " 1 / ns:trackNumber / rdf:Description 24
On JRS, RDF, and pureXML As the indexed properties where always described as (S,P,O) triplets, it was logical to use RDF as the serialization form – when GET resource-uri ?properties – when returning properties in search and query results – when storing indexes into pureXML The original query implementation was to store indexed properties in the Jazz Repository – which only supported queries using URL-encoded pairs, which was not sufficiently expressive to support our client queries. – pureXML’s xquery support allowed for very flexible and rich queries on the indexed properties. – solution is to store the RDF documents in pureXML and enable these to be queried using rich xquery expressions. 25
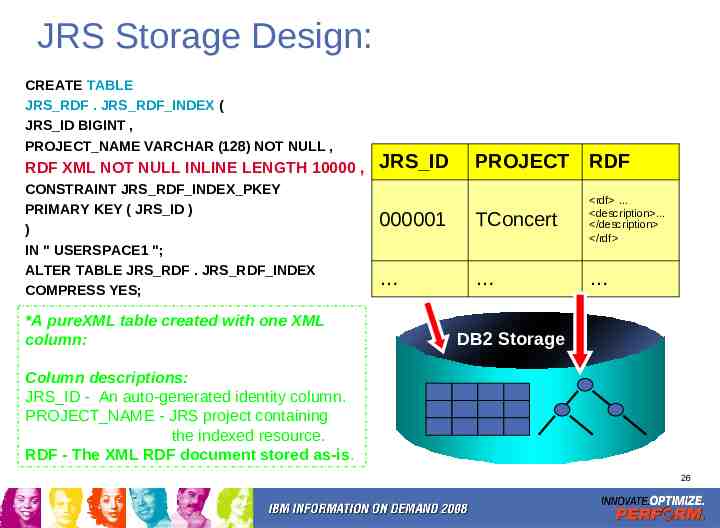
JRS Storage Design: CREATE TABLE JRS RDF . JRS RDF INDEX ( JRS ID BIGINT , PROJECT NAME VARCHAR (128) NOT NULL , RDF XML NOT NULL INLINE LENGTH 10000 , CONSTRAINT JRS RDF INDEX PKEY PRIMARY KEY ( JRS ID ) ) IN " USERSPACE1 "; ALTER TABLE JRS RDF . JRS RDF INDEX COMPRESS YES; *A pureXML table created with one XML column: JRS ID PROJECT RDF 000001 TConcert rdf description /description /rdf DB2 Storage Column descriptions: JRS ID - An auto-generated identity column. PROJECT NAME - JRS project containing the indexed resource. RDF - The XML RDF document stored as-is. 26
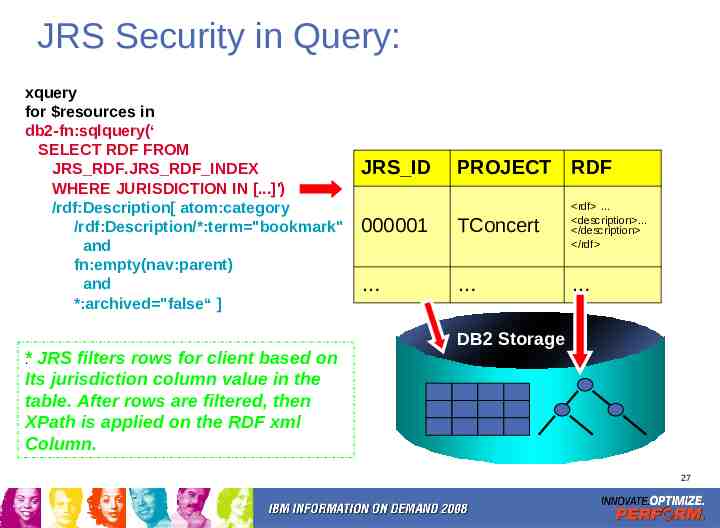
JRS Security in Query: xquery for resources in db2-fn:sqlquery(‘ SELECT RDF FROM JRS RDF.JRS RDF INDEX WHERE JURISDICTION IN [.]') /rdf:Description[ atom:category /rdf:Description/*:term "bookmark" and fn:empty(nav:parent) and *:archived "false“ ] .* JRS filters rows for client based on Its jurisdiction column value in the table. After rows are filtered, then XPath is applied on the RDF xml Column. JRS ID PROJECT RDF 000001 TConcert rdf description /description /rdf DB2 Storage 27
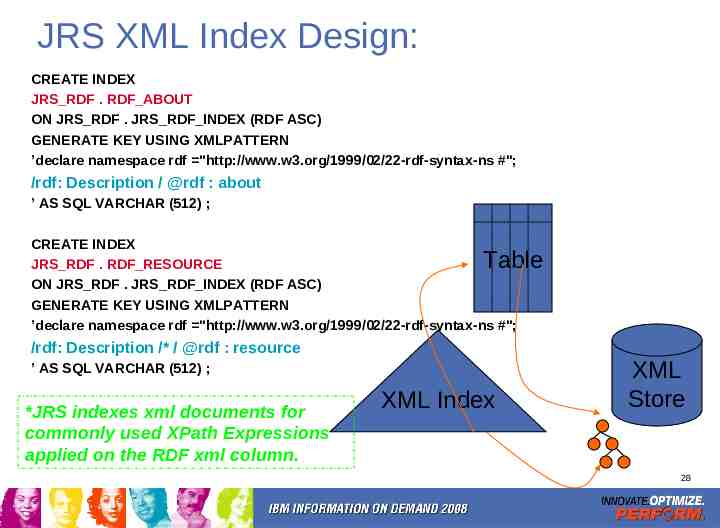
JRS XML Index Design: CREATE INDEX JRS RDF . RDF ABOUT ON JRS RDF . JRS RDF INDEX (RDF ASC) GENERATE KEY USING XMLPATTERN ’declare namespace rdf "http://www.w3.org/1999/02/22-rdf-syntax-ns #"; /rdf: Description / @rdf : about ’ AS SQL VARCHAR (512) ; CREATE INDEX JRS RDF . RDF RESOURCE ON JRS RDF . JRS RDF INDEX (RDF ASC) GENERATE KEY USING XMLPATTERN ’declare namespace rdf "http://www.w3.org/1999/02/22-rdf-syntax-ns #"; Table /rdf: Description /* / @rdf : resource ’ AS SQL VARCHAR (512) ; *JRS indexes xml documents for commonly used XPath Expressions applied on the RDF xml column. XML Index XML Store 28
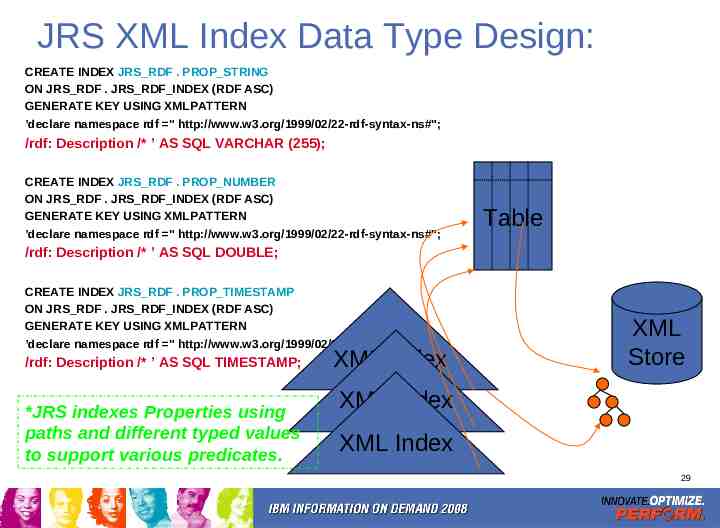
JRS XML Index Data Type Design: CREATE INDEX JRS RDF . PROP STRING ON JRS RDF . JRS RDF INDEX (RDF ASC) GENERATE KEY USING XMLPATTERN ’declare namespace rdf " http://www.w3.org/1999/02/22-rdf-syntax-ns#"; /rdf: Description /* ’ AS SQL VARCHAR (255); CREATE INDEX JRS RDF . PROP NUMBER ON JRS RDF . JRS RDF INDEX (RDF ASC) GENERATE KEY USING XMLPATTERN ’declare namespace rdf " http://www.w3.org/1999/02/22-rdf-syntax-ns#"; Table /rdf: Description /* ’ AS SQL DOUBLE; CREATE INDEX JRS RDF . PROP TIMESTAMP ON JRS RDF . JRS RDF INDEX (RDF ASC) GENERATE KEY USING XMLPATTERN ’declare namespace rdf " http://www.w3.org/1999/02/22-rdf-syntax-ns#"; /rdf: Description /* ’ AS SQL TIMESTAMP; *JRS indexes Properties using paths and different typed values to support various predicates. XML Index XML Store XML Index XML Index 29
JRS resource queries: xquery declare namespace rdf " http :// www.w3.org /1999/02/22 - rdf -syntax -ns #"; declare namespace wi " http :// www. jazz .net/ xmlns / workitems /"; for index in collection (’ JRS RDF INDEX ’) / rdf: Description where index /rdf: type / @rdf : resource " http :// example .com/ xmlns / music # album " and index / music : releasedYear 2000 return index /fn: string ( @rdf : about ); JRS RDF Indexes in pureXML *JRS accepts xquery queries on resource properties, which it feeds to pureXML for processing. 30
JRS resource join queries: XQUERY declare namespace rdf " http :// www.w3.org /1999/02/22 - rdf -syntax -ns#"; declare namespace music " http :// example .com/ xmlns / music #"; for artist in collection (’ JRS RDF INDEX ’) / rdf: Description [ rdf: type / @rdf : resource " http :// example .com/ xmlns / music # artist “ ] for artistsInAlbum collection (’ JRS RDF INDEX ’) / rdf: Description [ rdf: type / @rdf : resource " http :// example .com/ xmlns / music # album “ ] / music : artist / @rdf : resource where artist / @rdf : about artistsInAlbum return artist / music : name / text () JRS RDF Indexes in pureXML *Clients can issue very flexible join queries on JRS indexes to expose complex relationships between resources. 31
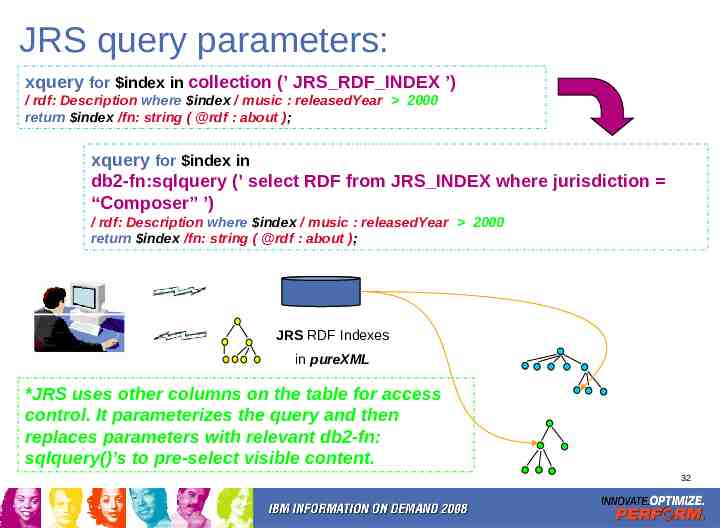
JRS query parameters: xquery for index in collection (’ JRS RDF INDEX ’) / rdf: Description where index / music : releasedYear 2000 return index /fn: string ( @rdf : about ); xquery for index in db2-fn:sqlquery (’ select RDF from JRS INDEX where jurisdiction “Composer” ’) / rdf: Description where index / music : releasedYear 2000 return index /fn: string ( @rdf : about ); JRS RDF Indexes in pureXML *JRS uses other columns on the table for access control. It parameterizes the query and then replaces parameters with relevant db2-fn: sqlquery()’s to pre-select visible content. 32
JRS HTTP Post Exchange: The request: POST / jazz / projects / main / query HTTP /1.1 Host : example .com Accept : */* Content - Type : application / xquery Content - Length : 256 xquery declare namespace rdf " http :// www.w3.org /1999/02/22 - rdf -syntax -ns #"; declare namespace music " http :// example .com/ xmlns / music #"; collection (’ JRS RDF INDEX ’) / rdf: Description [ rdf: type / @rdf : resource " http :// example .com/ xmlns / music # album " and music : releasedYear 2000] / fn: string ( @rdf : about ); The response: HTTP /1.1 200 OK Date : Thu , 20 Mar 2008 14:18:07 GMT Content - Length : 256 Last - Modified : Thu , 20 Mar 2008 14:18:07 GMT feed xmlns "" * Clients and JRS communicate using standard HTTP message exchanges. Results are in standard Atom format 33
JRS XQuery Samples: -- *** Effectively get all resource descriptions XQUERY declare namespace rdf " http :// www.w3.org /1999/02/22 - rdf -syntax -ns#"; collection (’ JRS RDF INDEX ’)// rdf: Description ; -- *** Find all Rock albums XQUERY declare namespace rdf " http :// www.w3.org /1999/02/22 - rdf -syntax -ns#"; declare namespace music " http :// example .com/ xmlns / music #"; collection (’ JRS RDF INDEX ’)/rdf: Description [ rdf: type / @rdf : resource " http :// example .com/ xmlns / music # album " and index / music : genre " Rock "]/ fn: string ( @rdf : about ); -- *** Find artist for all albums XQUERY declare namespace rdf " http :// www.w3.org /1999/02/22 - rdf -syntax -ns#"; declare namespace music " http :// example .com/ xmlns / music #"; for artist in collection (’ JRS RDF INDEX ’)/rdf: Description for artistsInAlbum collection (’ JRS RDF INDEX ’)/rdf: Description [ rdf: type / @rdf : resource " http :// example .com/ xmlns / music # album "]/ music : artist / @rdf : resource where artist /rdf: type / @rdf : resource " http :// example .com/ xmlns / music # artist " and artist / @rdf : about artistsInAlbum return artist / music : name / text (); 34
More Information 35
Other DB2 pureXML Sessions at IOD Introduction to DB2 pureXML: TAD-1485 Wed 2.00 Querying XML Data: An Introduction for SQL Developers TLU-1712Thu 8.30 DB2 pureXML Introduction and Survival Guide TLU-1504Thu 11.30 Making the Transition to DB2 pureXML DB2 pureXML Customers: TLU-1197Mon 3.45 DB2 pureXML Production Experiences at UCLA TLU-1533Tue 8.30 Why Rational chose DB2 pureXML for Jazz REST Services and SOA solutions BGV-1659 Tue 11.30 Implementing an Effective Electronic Government Solution - NY State Tax BHC-1677 Tue 11.30 Improving Health Care in China With a DB2 XML EMR Solution BCS-1438 Tue 2.15 Learn How Verizon Streamlined their Order System TDZ-2146 Tue 2.15 Real-world Usage of pureXML BGV-1659 Tue 3.45 Using XML for Effective Cross-agency Shared Services in Public Security TLU-1993Wed 8.30 Flowers and Financial Services: B2B With DB2 pureXML TLU-1437Wed 10.00 Implementing an Enterprise Order Database With DB2 pureXML at Verizon TAD-2255 Thu 8.30 DB2 and Data Studio: Building a Web Application Without the Web Application TLU-1678Thu 3.30 DB2 pureXML Customers - Trends and Successes Meet the Expert: MTE-3277 Meet the Expert: Henrik Loeser 36
Other DB2 pureXML Sessions at IOD Sessions: TAD-1906 Mon 10.30 SOA and pureXML: The Role of DB2 in an Innovative Architecture TDZ-1489 Mon 10.30 Query XML Data in DB2 9 for z/OS BGV-1661 Wed 10.00 Streamline Govt Processing Through Electronic Forms and DB2 pureXML TLU-1622Wed 2.00 Top 10 Best Practices for DB2 pureXML TDZ-1810 Thu 8.30 Ten Essential DBA Tasks for DB2 9 for z/OS pureXML Birds of a Feather: BOF-1633 BOF-1815 Thu 5.30 Thu 5.30 DB2 pureXML Users - Best practices & Requirements DB2 9 for z/OS pureXML Real-world Experiences Hands-on Labs: HOL-1934 HOL-2584 HOL-2716 HOL-1933 HOL-2585 HOL-1923 HOL-2583 HOL-1848 Tue 2.15 EForms Application With DB2 pureXML and Lotus Forms Wed 10.00 DBA for pureXML in DB2 9 for z/OS Wed 10.00 Advanced DB2 pureXML Thu 10.00 pureXML Industry Applications Thu 10.00 Learning SQL/XML with CLP and SPUFI Thu 2.00 Demonstrating DB2 9.5 pureXML in an SOA Application Environment Thu 2.00 Learning pureXML in DB2 9 for z/OS with IBM Data Studio Fri 8.30 Introduction to DB2 pureXML 9.5 37
DB2 pureXML Resources Web site www.ibm.com/software/data/db2/xml/ Wiki www.ibm.com/developerworks/wikis/display/db2xml/ Forum www.ibm.com/developerworks/forums/forum.jspa?forumID 1423/ Team Blog www.ibm.com/developerworks/blogs/page/purexml ChannelDB2 User Group www.channeldb2.ning.com/group/pureXML 38
Search for the XML Superstar XML Contest Quick Facts www.xmlchallenge.com Global programming contest featuring DB2 9 technology No purchase required but download and use of DB2 9 mandatory Multiple ways for developers and students to participate Over 30 countries running the contest. US Contest open now. Blog about the contest or join contest groups on Facebook, LinkedIn, ChannelDb2, etc. (Keywords: “XML Superstar”) Latest News Contest @ IOD Register for the contest at the US Contest launched on Developer Den and win a Oct 1 FREE DB2 certification Prizes include laptops, voucher valid till Dec 31 2008 iPods, Wiis, Cameras, GPS Use the camera @ Developer devices Den to create your own video Other countries running Get a FREE T-shirt, bookmark contest currently: India, or Rubik’s Cube China, Singapore, Thailand, Vietnam, Indonesia, Malaysia, Philippines, Poland, Portugal, Turkey Participants India: 45,000 students India: 1,200 developers China: 9,000 developers Turkey: 560 students Multiple workshops for students and professionals in NA, EMEA and AP 39
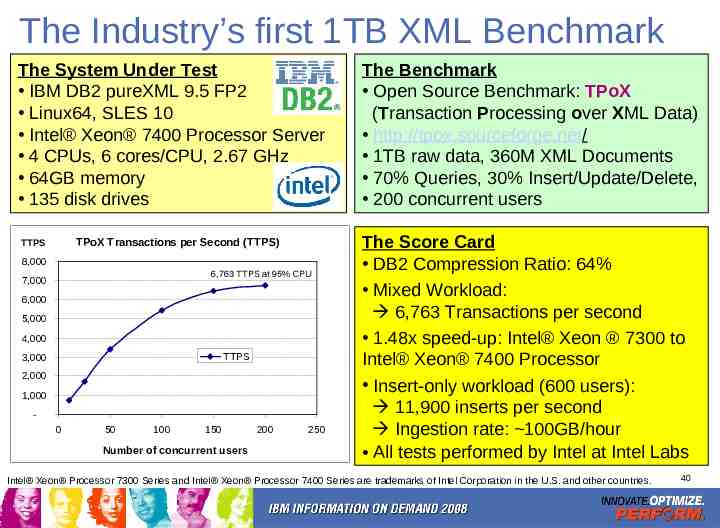
The Industry’s first 1TB XML Benchmark The System Under Test IBM DB2 pureXML 9.5 FP2 Linux64, SLES 10 Intel Xeon 7400 Processor Server 4 CPUs, 6 cores/CPU, 2.67 GHz 64GB memory 135 disk drives TPoX Transactions per Second (TTPS) TTPS 8,000 6,763 TTPS at 95% CPU 7,000 6,000 5,000 4,000 TTPS 3,000 2,000 1,000 0 50 100 150 Number of concurrent users 200 250 The Benchmark Open Source Benchmark: TPoX (Transaction Processing over XML Data) http://tpox.sourceforge.net/ 1TB raw data, 360M XML Documents 70% Queries, 30% Insert/Update/Delete, 200 concurrent users The Score Card DB2 Compression Ratio: 64% Mixed Workload: 6,763 Transactions per second 1.48x speed-up: Intel Xeon 7300 to Intel Xeon 7400 Processor Insert-only workload (600 users): 11,900 inserts per second Ingestion rate: 100GB/hour All tests performed by Intel at Intel Labs Intel Xeon Processor 7300 Series and Intel Xeon Processor 7400 Series are trademarks of Intel Corporation in the U.S. and other countries. 40
Disclaimer Copyright IBM Corporation 2008. All rights reserved. U.S. Government Users Restricted Rights - Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. THE INFORMATION CONTAINED IN THIS PRESENTATION IS PROVIDED FOR INFORMATIONAL PURPOSES ONLY. WHILE EFFORTS WERE MADE TO VERIFY THE COMPLETENESS AND ACCURACY OF THE INFORMATION CONTAINED IN THIS PRESENTATION, IT IS PROVIDED “AS IS” WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED. IN ADDITION, THIS INFORMATION IS BASED ON IBM’S CURRENT PRODUCT PLANS AND STRATEGY, WHICH ARE SUBJECT TO CHANGE BY IBM WITHOUT NOTICE. IBM SHALL NOT BE RESPONSIBLE FOR ANY DAMAGES ARISING OUT OF THE USE OF, OR OTHERWISE RELATED TO, THIS PRESENTATION OR ANY OTHER DOCUMENTATION. NOTHING CONTAINED IN THIS PRESENTATION IS INTENDED TO, NOR SHALL HAVE THE EFFECT OF, CREATING ANY WARRANTIES OR REPRESENTATIONS FROM IBM (OR ITS SUPPLIERS OR LICENSORS), OR ALTERING THE TERMS AND CONDITIONS OF ANY AGREEMENT OR LICENSE GOVERNING THE USE OF IBM PRODUCTS AND/OR SOFTWARE. IBM, the IBM logo, ibm.com, DB2, and pureXML are trademarks or registered trademarks of International Business Machines Corporation in the United States, other countries, or both. If these and other IBM trademarked terms are marked on their first occurrence in this information with a trademark symbol ( or ), these symbols indicate U.S. registered or common law trademarks owned by IBM at the time this information was published. Such trademarks may also be registered or common law trademarks in other countries. A current list of IBM trademarks is available on the Web at “Copyright and trademark information” at www.ibm.com/legal/copytrade.shtml Other company, product, or service names may be trademarks or service marks of others. 41





