Sultanate of Oman Ministry of Higher Education University of Nizwa




















23 Slides1.16 MB
Sultanate of Oman Ministry of Higher Education University of Nizwa Big Data AND Hadoop Prepared by : Amal Al Muqrishi Course Title: Advanced Database Systems - INFS504
Outline Big data and its challenges Apache Hadoop Requirements for Hadoop Apache Hadoop modules Hadoop Distributed File System Hadoop MapReduce Hadoop and RDBMS Comparison Advanced Database Systems - INFS504
Big data The data is growing rapidly because of Users Systems Sensors Applications Big data: It is a term for data sets that are so large or complex that traditional data processing applications are inadequate to deal with them. Advanced Database Systems - INFS504
Challenges of Big data Challenges of Big data that called V attributes : Velocity : means the data comes at high speed Volume : focus on large and growing files Variety : means the files come in various formats (e.g. text, sound and video) How to handle the big data ? How to process big data with reasonable cost and time? Advanced Database Systems - INFS504
What is Apache Hadoop? Hadoop: It is an open source, Java-based programming framework that supports the processing and storage of extremely large data sets in a distributed computing environment. It is part of the Apache project sponsored by the Apache Software Foundation. Advanced Database Systems - INFS504
Who Uses Hadoop? Advanced Database Systems - INFS504
Requirements for Hadoop Must support partial failure Must be scalable Advanced Database Systems - INFS504
Partial Failures Failure of a single component must not cause the failure of the entire system only a degradation of the application performance Failure should not result in the loss of any data Advanced Database Systems - INFS504
Component Recovery If a component fails, it should be able to recover without restarting the entire system Component failure or recovery during a job must not affect the final output Advanced Database Systems - INFS504
Scalability Increasing resources should increase load capacity Increasing the load on the system should result in a graceful decline in performance for all jobs Not system failure Advanced Database Systems - INFS504
Hadoop modules Hadoop consists of numerous functional modules : At a minimum, Hadoop uses Hadoop Common as a kernel to provide the framework's essential libraries. Hadoop Distributed File System (HDFS), which is capable of storing data across thousands of commodity servers to achieve high bandwidth between nodes. Hadoop MapReduce, which provides the programming model used to tackle large distributed data processing - mapping data and reducing it to a result. Hadoop Yet Another Resource Negotiator (YARN), which provides resource management and scheduling for user applications. Advanced Database Systems - INFS504
Hadoop modules Hadoop also supports a range of related projects that can complement and extend Hadoop's basic capabilities. Complementary software packages include: Apache Flume Apache HBase Apache Hive Apache Oozie Apache Phoenix Apache Pig Apache Sqoop Apache Spark Apache Storm Apache ZooKeeper Advanced Database Systems - INFS504
Hadoop Distributed File System HDFS is a file system written in Java based on the Google’s FS Responsible for storing data on the cluster Data files are split into blocks and distributed across the nodes in the cluster Each block is replicated multiple times The NameNode keeps track of which blocks make up a file and where they are stored Advanced Database Systems - INFS504
Data Replication Advanced Database Systems - INFS504
Data Retrieval When a client wants to retrieve data Communicates with the NameNode to determine which blocks make up a file and on which data nodes those blocks are stored Then communicated directly with the data nodes to read the data Advanced Database Systems - INFS504
MapReduce Overview A method for distributing computation across multiple nodes Each node processes the data that is stored at that node Consists of two main phases Map Reduce Advanced Database Systems - INFS504
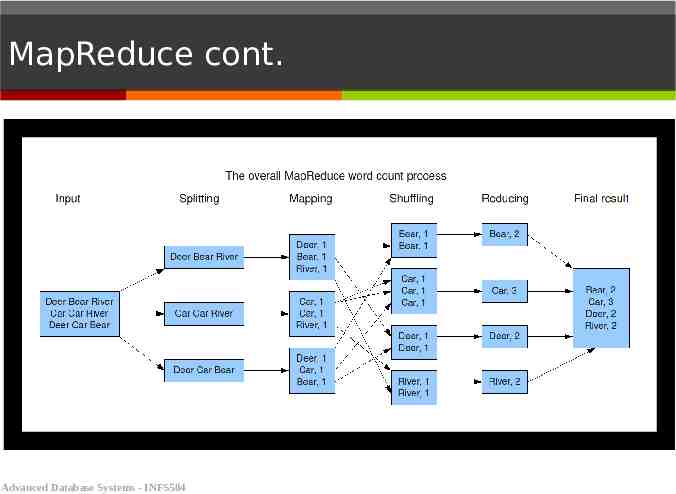
MapReduce cont. The Mapper: Reads data as key/value pairs Shuffle and Sort: Output from the mapper is sorted by key All values with the same key are guaranteed to go to the same machine The Reducer: Called once for each unique key Gets a list of all values associated with a key as input The reducer outputs zero or more final key/value pairs Usually just one output per input key Advanced Database Systems - INFS504
MapReduce cont. Advanced Database Systems - INFS504
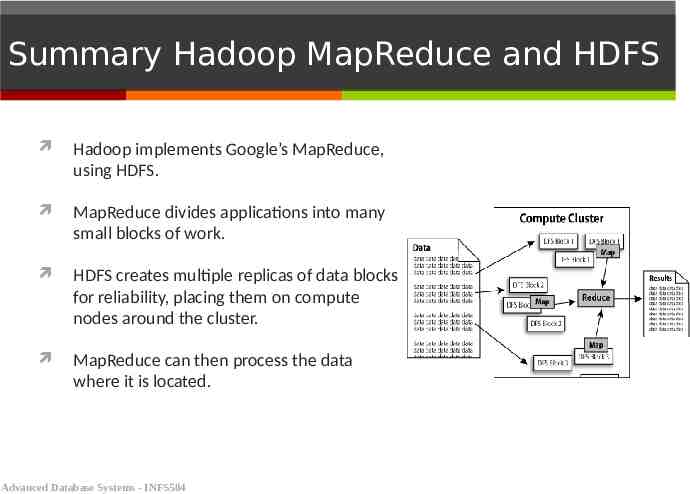
Summary Hadoop MapReduce and HDFS Hadoop implements Google’s MapReduce, using HDFS. MapReduce divides applications into many small blocks of work. HDFS creates multiple replicas of data blocks for reliability, placing them on compute nodes around the cluster. MapReduce can then process the data where it is located. Advanced Database Systems - INFS504
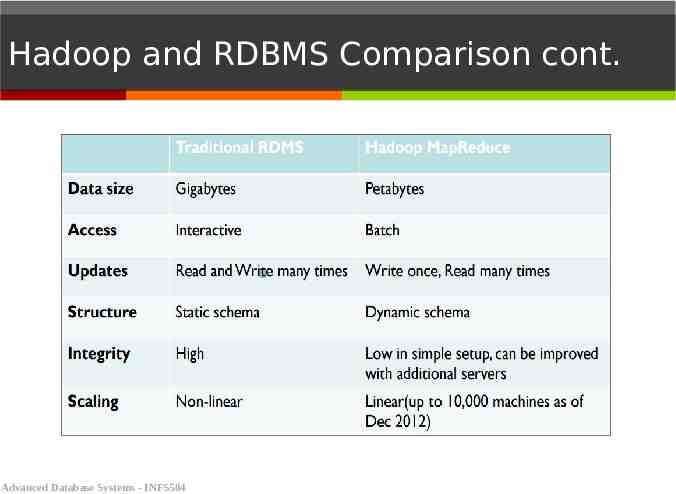
Hadoop and RDBMS Comparison The traditional systems, such as Relational Database Management Systems (RDBMS), are not able to handle the big data, while hadoop handles the issues by using HDFS for storage and Hadoop MapReduce for analysis and processing Hadoop fits well to analyze whole dataset in a batch fashion RDMS is for real-time data retrieval with low-latency and small data sets Advanced Database Systems - INFS504
Hadoop and RDBMS Comparison cont. Advanced Database Systems - INFS504
Summary Big data and its challenges Velocity, Volume, and Variety Apache Hadoop Requirements for Hadoop Must support partial failure Must be scalable Apache Hadoop modules Hadoop Distributed File System Hadoop MapReduce Hadoop and RDBMS Comparison Advanced Database Systems - INFS504






