STEPHEN G. POWELL KENNETH R. BAKER MANAGEMENT SCIENCE CHAPTER





















22 Slides1.21 MB
STEPHEN G. POWELL KENNETH R. BAKER MANAGEMENT SCIENCE CHAPTER 6 POWERPOINT CLASSIFICATION AND PREDICTION METHODS The Art of Modeling with Spreadsheets Compatible with Analytic Solver Platform FOURTH EDITION
INTRODUCTION Analysts engage in three types of tasks: 1) descriptive, 2) predictive and 3) prescriptive. Predictive methods include: – Classification, to predict which class an individual record will occupy (e.g., will a particular customer buy?) – Prediction, to predict a numerical outcome for an individual record (e.g., how much will that customer spend?) Now that data is plentiful, data mining enables more accurate prediction. Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 2
THE PROBLEM OF OVER-FITTING Data includes both patterns (stable, underlying relationships) and noise (transient, random effects). Noise has no predictive value; so a model is over-fit when it incorporates noise. The figure below right shows results from two predictive models— polynomial and linear—applied to the same data set. The polynomial model predicts sales almost 50 times the actual value, where the linear model is far more realistic (and accurate). Be skeptical of data and skeptical of results. Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 3
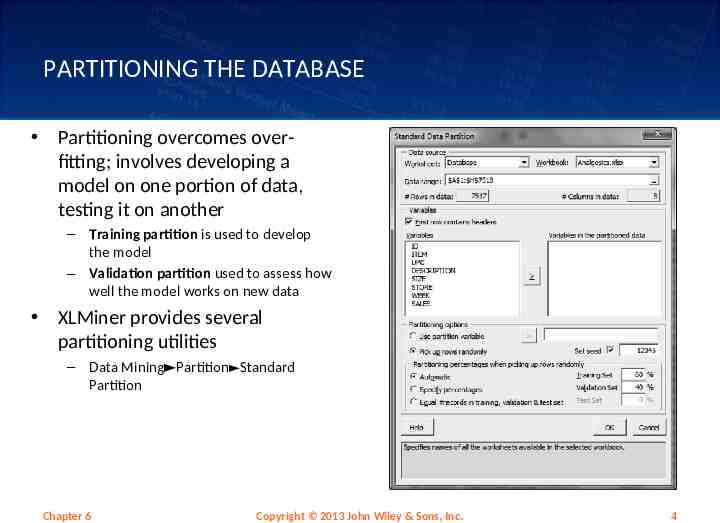
PARTITIONING THE DATABASE Partitioning overcomes overfitting; involves developing a model on one portion of data, testing it on another – Training partition is used to develop the model – Validation partition used to assess how well the model works on new data XLMiner provides several partitioning utilities – Data Mining Partition Standard Partition Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 4
PERFORMANCE MEASURES The ultimate goal of data analysis is to predict the future. To classify new instances (e.g., whether a registered voter will vote) – We measure predictive accuracy by instances correctly classified For numerical predictions (e.g., number of votes received by the winner in each state) – Accuracy measured by differences between predicted and actual outcomes Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 5
SIX WIDELY-USED CLASSIFICATION/PREDICTION METHODS k-Nearest Neighbor Naïve Bayes Classification and Prediction Trees Multiple Linear Regression Logistic Regression Neural Networks Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 6
GENERAL CAVEAT No one model is perfect, universally applicable Data mining analysts will typically build several competing models (e.g., multiple linear regression, kNearest Neighbor, Prediction Trees and Neural Networks) and implement the one that proves most effective. Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 7
THE K-NEAREST NEIGHBOR METHOD Bases classification of a new case on records most similar to the new case – E.g., by Pandora’s Music Genome Project to identify songs that appeal to a user Answers three major questions: – How to define similarity between records? – How many neighboring records to use? – What classification or prediction rule to use? Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 8
STRENGTHS AND WEAKNESSES OF THE K-NEAREST NEIGHBOR ALGORITHM Strengths: – Simplicity. Requires no assumptions as to the form of the model, few assumptions about parameters. – Only one parameter estimated (k) – Performs well where there is a large training database, or many combinations of predictor variables Weaknesses: – Provides no information on which predictors are most effective in making a good classification – Long computational times; number of records required increases faster than linearly Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 9
THE NAÏVE BAYES METHOD Similar to k-Nearest Neighborhood but, restricted to situations in which all predictor variables are categorical Example: Spam filtering, based on categorical values Word Appeared and Word did not Appear. Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 10
STRENGTHS AND WEAKNESSES OF THE NAÏVE BAYES ALGORITHM Strengths: – Remarkably simple, but often gives classification accuracy as good as or better than more sophisticated algorithms – Requires no assumptions other than class-conditional independence Weaknesses: – Requires large number of records for good results – Estimates a probability of zero for new cases with a predictor value missing from the training database – Suitable only for classification, not for estimating class probabilities Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 11
CLASSIFICATION AND PREDICTION TREES Based on the observation that there are subsets of records in a database that contain mostly 1s or 0s Identify the subsets, and we can classify a new record based on majority outcome in the subset it most resembles Example: Predict purchasing behavior of individuals for whom we know three variables, being age, income and education Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 12
CLASSIFICATION AND PREDICTION TREES (CONT’D) First describe the approach for classification (with numerical predictors) then how to use predictor variables for classification, as follows: 1. 2. 3. 4. 5. Pick a predictor variable. Sort its values from low to high. Define a set of split points as midpoints between each pair of values. For each split point, divide records into above/below split. Evaluate homogeneity of records in each subset (extent to which records are mostly 1s or 0s) 6. Repeat for all split points for this variable 7. Choose split point that gives most homogeneous subsets 8. Repeat for all variables 9. Split on the variable with highest homogeneity 10. Repeat for each subset of records Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 13
STRENGTHS AND WEAKNESSES OF CLASSIFICATION AND PREDICTION TREES Strengths: – Easy to understand and explain – Transparent results, can be interpreted as explicit If-Then rules – Based on few assumptions, works well even with missing data and outliers Weaknesses: – Accurate results require very large databases – Allows partitioning of only individual variables, not pairs or groups – Specific to XLMiner: only binary categorical variables allowed. Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 14
MULTIPLE LINEAR REGRESSION One of the most widely-used tools from classical statistics Used widely in natural and social sciences, more often for explanatory than predictive modeling – To determine if specific variables influence outcome variable Answers questions like: – Do the data support the claim that women are paid less than men in comparable jobs? – Is there evidence that price discounts and rebates lead to higher longterm sales? – Do data support the idea that firms that outsource manufacturing overseas have higher profits? Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 15
STRENGTHS AND WEAKNESSES OF MULTIPLE LINEAR REGRESSION Strengths: – Well-known and well-accepted model for prediction – Easy to implement and interpret – Inferential statistics (p-values and R2) are available Weaknesses: – Possible for regression model to exhibit high R2 but low predictive accuracy Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 16
LOGISTIC REGRESSION A statistical approach to classification of categorical outcome variables Similar to multiple linear regression, but can be used when the outcome has more than two values Uses data to produce a probability that a given case will fall into one of two classes (e.g., flights that leave on time/delayed, companies that will/will not default on bonds, employees who will/will not be promoted) Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 17
STRENGTHS AND WEAKNESSES OF LOGISTIC REGRESSION Strengths: – Well-known, widely used, especially in marketing – Easy to implement and fairly straightforward Weaknesses: – A facility with concept of odds often necessary – If a large number of predictor values, then often necessary to reduce them to most important through pre-processing, inferential statistics, best subset selection Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 18
NEURAL NETWORKS An outgrowth of research within artificial intelligence into how the brain works Used for classification and prediction Applied to extremely wide variety of areas (e.g., from financial applications to controlling robots) In finance: – To predict bankruptcy of firms – To trade on currency, stock or bond markets – To predict credit card fraud Complex and difficult to understand but high predictive accuracy Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 19
STRENGTHS AND WEAKNESSES OF NEURAL NETWORKS Strengths: – Highly successful in many applications (thought unsuccessful in many more) – Very flexible because the fundamental structure (the number of hidden layers and nodes) is chosen by the user – Capture complex relationships between inputs and outputs Weaknesses: – Difficult to interpret, thus hard to justify – Limited insight into underlying relationships – Requires modeler to carefully pre-process predictor variables, experiment with different sets of predictors Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 20
SUMMARY Classification methods apply when the task is to predict which class an individual record may occupy (e.g., whether a customer will buy a certain product). Prediction methods apply when the task is to predict a numerical outcome (e.g., how much a customer will buy). It is quite common for analysts to construct models using competing of the six methods, then select the most effective. Chapter 6 Copyright 2013 John Wiley & Sons, Inc. 21
COPYRIGHT 2013 JOHN WILEY & SONS, INC. All rights reserved. Reproduction or translation of this work beyond that permitted in section 117 of the 1976 United States Copyright Act without express permission of the copyright owner is unlawful. Request for further information should be addressed to the Permissions Department, John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution or resale. The Publisher assumes no responsibility for errors, omissions, or damages caused by the use of these programs or from the use of the information herein.