On-line documents 3 Day 22 – 10/17/14 LING 3820 & 6820 Natural













19 Slides1.03 MB
On-line documents 3 Day 22 - 10/17/14 LING 3820 & 6820 Natural Language Processing Harry Howard Tulane University
Course organization 2 http://www.tulane.edu/ howard/LING3820 / The syllabus is under construction. http://www.tulane.edu/ howard/ CompCultEN/ Chapter numbering 3.7. How to deal with non-English characters 4.5. How to create a pattern with Unicode characters 6. Control NLP, Prof. Howard, Tulane University 17-Oct-2014
3 Open Spyder NLP, Prof. Howard, Tulane University 17-Oct-2014
4 Review How to download a file from Project Gutenberg NLP, Prof. Howard, Tulane University 17-Oct-2014
The global working directory 5 2.2.1. How to set the global working directory in Spyder I am getting tired of constantly double-checking that Python saves my stuff to pyScripts, but fortunately Spyder can do it for us. Open Spyder: On a Mac, click on the python menu (top left). In Windows, click on the Tools menu. Open Preferences Global working directory Startup At startup, the global working directory is: the following directory: /Users/harryhow/Documents/pyScripts Set the next two selections to "the global working directory". Leave the last untouched & unchecked. NLP, Prof. Howard, Tulane University 17-Oct-2014
gutenLoader 6 def gutenLoader(url, name): 1.from urllib import urlopen 2.download urlopen(url) 3.text download.read() 4.print 'text length ' str(len(text)) 5.lineIndex text.index('*** START OF THIS PROJECT GUTENBERG EBOOK') 6.startIndex text.index('\n',lineIndex) 7.endIndex text.index('*** END OF THIS PROJECT GUTENBERG EBOOK') 8.story text[startIndex:endIndex] 9.print 'story length ' str(len(story)) 10.tempFile open(name,'w') 11.tempFile.write(story.encode('utf8')) 12.tempFile.close() 13.print 'File saved' 14.return NLP, Prof. Howard, Tulane University 17-Oct-2014
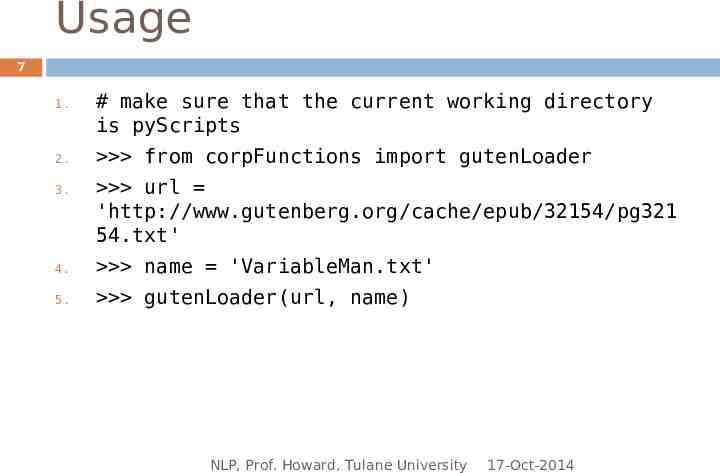
Usage 7 1. 2. 3. # make sure that the current working directory is pyScripts from corpFunctions import gutenLoader url 'http://www.gutenberg.org/cache/epub/32154/pg321 54.txt' 4. name 'VariableMan.txt' 5. gutenLoader(url, name) NLP, Prof. Howard, Tulane University 17-Oct-2014
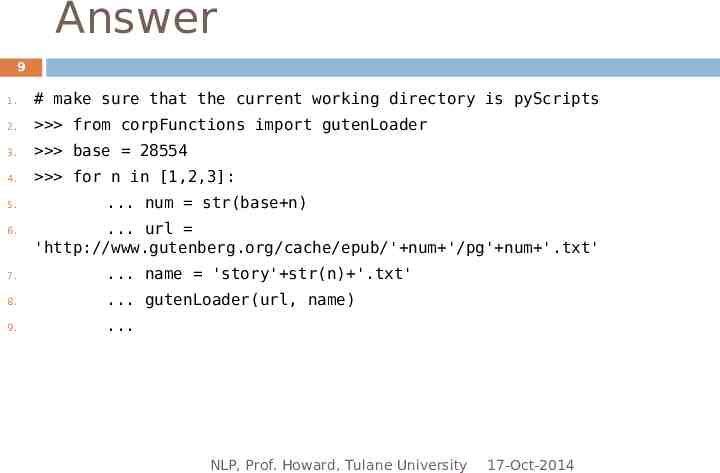
Homework 8 Since the documents in Project Gutenberg are numbered consecutively, you can download a series of them all at once with a for loop. Write the code for doing so. HINT: remember that strings and intergers are different types. To turn a string into an integer, use the built-in str() method, e.g. str(1). NLP, Prof. Howard, Tulane University 17-Oct-2014
Answer 9 1. # make sure that the current working directory is pyScripts 2. from corpFunctions import gutenLoader 3. base 28554 4. for n in [1,2,3]: 5. 6. . num str(base n) . url 'http://www.gutenberg.org/cache/epub/' num '/pg' num '.txt' 7. . name 'story' str(n) '.txt' 8. . gutenLoader(url, name) 9. . NLP, Prof. Howard, Tulane University 17-Oct-2014
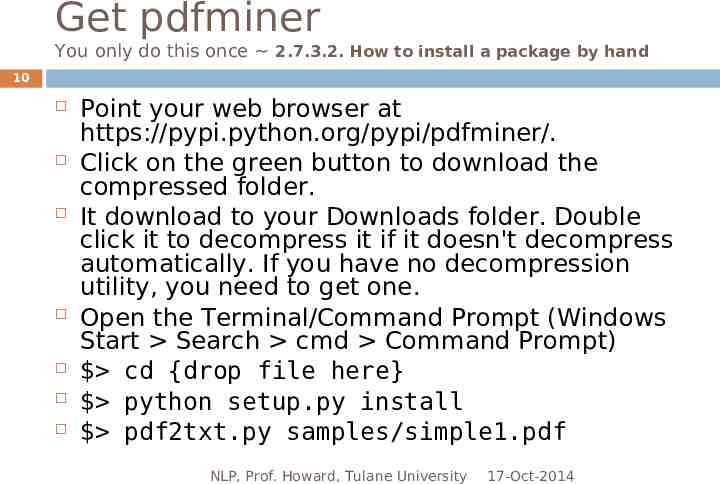
Get pdfminer You only do this once 2.7.3.2. How to install a package by hand 10 Point your web browser at https://pypi.python.org/pypi/pdfminer/. Click on the green button to download the compressed folder. It download to your Downloads folder. Double click it to decompress it if it doesn't decompress automatically. If you have no decompression utility, you need to get one. Open the Terminal/Command Prompt (Windows Start Search cmd Command Prompt) cd {drop file here} python setup.py install pdf2txt.py samples/simple1.pdf NLP, Prof. Howard, Tulane University 17-Oct-2014
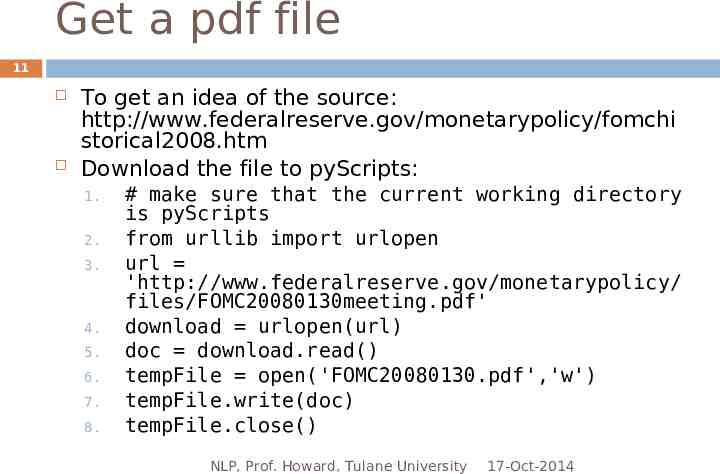
Get a pdf file 11 To get an idea of the source: http://www.federalreserve.gov/monetarypolicy/fomchi storical2008.htm Download the file to pyScripts: 1. 2. 3. 4. 5. 6. 7. 8. # make sure that the current working directory is pyScripts from urllib import urlopen url 'http://www.federalreserve.gov/monetarypolicy/ files/FOMC20080130meeting.pdf' download urlopen(url) doc download.read() tempFile open('FOMC20080130.pdf','w') tempFile.write(doc) tempFile.close() NLP, Prof. Howard, Tulane University 17-Oct-2014
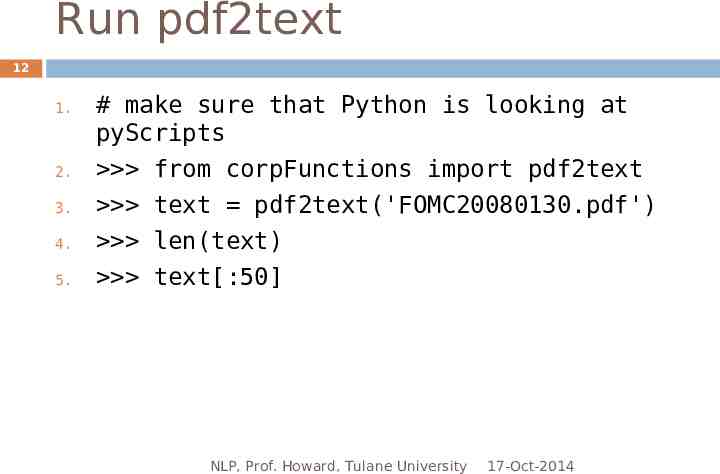
Run pdf2text 12 1. 2. 3. 4. 5. # make sure that Python is looking at pyScripts from corpFunctions import pdf2text text pdf2text('FOMC20080130.pdf') len(text) text[:50] NLP, Prof. Howard, Tulane University 17-Oct-2014
13 7.3.2. How to pre-process a text with the PlaintextCorpusReader NLP, Prof. Howard, Tulane University 17-Oct-2014
NLTK 14 One of the reasons for using NLTK is that it relieves us of much of the effort of making a raw text amenable to computational analysis. It does so by including a module of corpus readers, which pre-process files for certain tasks or formats. Most of them are specialized for particular corpora, so we will start with the basic one, called the PlaintextCorpusReader. NLP, Prof. Howard, Tulane University 17-Oct-2014
PlaintextCorpusReader 15 The PlaintextCorpusReader needs to know two things: where your file is and what its name is. If the current working directory is where the file is, the location argument can be left ‘blank’ by using the null string ''. We only have one file, ‘Wub.txt’. It will also prevent problems down the line to give the method an optional third argument that relays its encoding, encoding 'utf-8'. Now let NLTK tokenize the text into words and punctuation. NLP, Prof. Howard, Tulane University 17-Oct-2014
Usage 16 1. 2. 3. 4. # make sure that the current working directory is pyScripts from nltk.corpus import PlaintextCorpusReader wubReader PlaintextCorpusReader('', 'Wub.txt', encoding 'utf-8') wubWords wubReader.words() NLP, Prof. Howard, Tulane University 17-Oct-2014
Initial look at the text 17 1. 2. 3. 4. 5. 6. 7. 8. len(wubWords) wubWords[:50] set(wubWords) len(set(wubWords)) wubWords.count('wub') len(wubWords) / len(set(wubWords)) from future import division 100 * wubWords.count('a') / len(wubWords) NLP, Prof. Howard, Tulane University 17-Oct-2014
18 Basic text analysis with NLTK 1. from nltk.text import Text 2. t Text(wubWords) 3. t.concordance('wub') 4. t.similar('wub') 5. t.common contexts(['wub','captain']) 6. t.dispersion plot(['wub']) 7. t.generate() NLP, Prof. Howard, Tulane University 17-Oct-2014
19 Next time Q6 take home Intro to text stats NLP, Prof. Howard, Tulane University 17-Oct-2014






