Introducere in Business Intelligence (3) Conf. Bologa Ana-Ramona























































60 Slides1.79 MB
Introducere in Business Intelligence (3) Conf. Bologa Ana-Ramona ASE, Bucuresti
Agenda 1. Modelarea datelor in BI 2. Advanced analytics (in memory, big data) 3. Baze de date orientate pe coloane in contextul Big data
Modelarea datelor reprezinta vizual natura datelor, regulile de business respectate de date si cum vor fi utilizate in baza de date are doua parti esentiale: 1. Proiectare logica 2. Proiectare fizica modelul datelor nu va include toate datele si codul din baza de date, dar va avea obiecte de tip: tabela, coloana, restrictie, relatie
Ciclul de modelare a datelor 1. Colectarea cerintelor de business – interactiune 2. 3. 4. 5. cu analistul de business si utilizatorii finali pt cerintele de raportare Modelarea conceptuala a datelor – identificarea entitatilor principale si a relatiilor dintre ele Modelarea logica a datelor – reprezinta toate cerintele de business , extinzand modelul conceptul cu atribute, chei, relatii, text descriptiv Modelarea fizica a datelor – model complet ce include tabele, coloane, relatii, proprietati fizice Crearea bazei de date – entitati- tabele, atribute - coloane, tipuri de date, restrictii , indecsi
Pasi pentru crearea modelului logic 1. Identificarea cerintelor de business 2. Analiza cerintelor de business 3. Crearea modelului conceptual al datelor. Aprobarea lui de catre reprezentantii de business 4. Crearea noului model logic de date care include urmatoarele: Selectarea BD tinta (pt generare scripturi pentru schema fizica) Crearea unui document cu abrevieri standard pentru obiectele logice/fizice Crearea domeniilor Crearea regulilor Crearea valorilor implicite Crearea entitatilor si adaugarea de definitii Asignarea tipurilor de date/domeniilor pt atribute Adaugarea de restrictii CHECK/reguli sau valori implicite Crearea de chei primare sau unice Crearea indecsilor Daca e necesara, crearea subtipurilor si supertipurilor (mostenire) Identificarea relatiilor intre entitati si crearea cheilor externe Validarea modelului de date Aprobarea modelului logic
Pasi pentru crearea modelului fizic 1. Crearea modelului fizic pe baza modelului logic 2. Adaugarea de proprietati specifice bazei de date 3. Generarea scripturilor SQL din modelul fizic; trimiterea lor catre DBA 4. Compararea bazei de date cu modelul datelor 5. Crearea unui document de log pentru urmarirea modificarilor modelului In transformarea model logic - model fizic, tipurile de date pot fi complet diferite, conform cerintelor de raportare si restrictiilor fizice (lungimea numelor tabelelor, numelor coloanelor etc) STANDARDIZARE in modelul logic datelor (aceeasi denumire, tip, abrevieri)
Notatii Notatii pentru modelarea datelor: Information Engineering (IE), Barker, IDEF1X, Unified Modeling Language (UML)
Implementare Data Warehouse Strategii de implementare Strategie de tip organizatie / top – down / metodologie Inmon Strategie de tip Data Mart / bottom – up / metodologie Kimball Aplicate corect, ambele strategii conduc la o implementare corecta de Data Warehouse
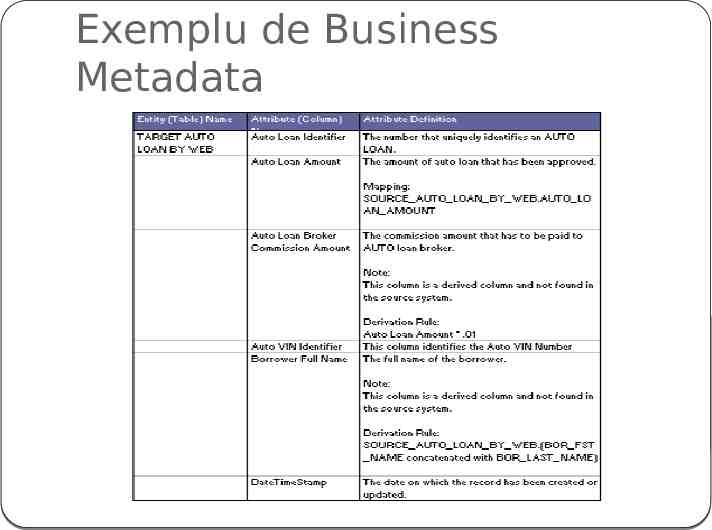
Depozit de modele de date Modelele datelor si metadatele referitoare la acestea sunt stocate intr-un Data Model Repository – acces concurent, pe baza de privilegii Business metadata text aditional , definitie a unui termen (tabela, coloana) asigura intelegerea comuna a semnificatiei util in generarea rapoartelor atat pentru echipa tehnica, cat si pentru non-tehnica, Metadate TABELA – numele sistemului sursa, numele entitatii sursa, regulile de business pentru transformarea tabelei sursa, utilizarea tabelei in rapoarte Metadate COLOANA – coloana sursa, regulile de business pentru transformarea coloanei sursa, utilizarea coloanei in rapoarte
Exemplu de Business Metadata
Beneficii Reducerea duratei dezvoltarii sistemului BI prin intelegerea sistemelor sursa Acuratete ridicata a rezultatelor BI Transparenta crescuta care le permite utilizatorilor si dezvoltatorilor sa isi dea seama ce informatii sunt disponibile
QPM- Qlikview Project Methodology Metodologie proprie QLIK, 2011 Descrie activitatile legate de managementul unui proiect Qlikview ti etapele de realizarea a unei aplicatii BI, inclusiv documente si livrabile Etape: 1. initierea proiectului, 2. etapa de planificare, 3. etapa de executie, 4. etapa de implementare 5. etapa de evaluare
QPM- Qlikview Project Methodology
Q1. Initierea proiectului Definirea obiectivului initial - corelat cu obiectivele debusiness; Planificarea si bugetarea initiala activitati: Estimarea duratei proiectului si a perioadei de timp alocata fiecarei etape ; Stabilirea resurselor necesare; Definirea unui plan initial cu activitatile proiectului si cu perioada alocata fiecarei activitati; Pregatirea bugetului proiectului; Definirea cerintelor initiale cu urmatoarele activitati: Definirea cerintelor de business si a restrictiilor; Identificarea cerintelor initiale legate de sursele de date
Q1. Initierea proiectului (cont) Întelegerea modului cum sunt create, stocate, transportate si raportate datele Stabilirea transformarilor necesare asupra datelor; Identificarea cerintelor legate de integrarea datelor Realizarea unei mapari sursa-destinatie; Specificarea cerintelor infrastructurii Specificarea cerintelor de securitate (criptarea, autentificare sti autorizarea accesului la date ); Descrierea diferitelor solutii si utilizarea unui model SWOT pentru fiecare solutie. Identificarea solutiei optime.
Q2. Planificarea Planificarea managementului proiectului cu urmatoarele activitati: Actualizarea cerintelor de business si ierarhizarea lor Estimarea efortului necesar pentru implementarea cerintelor de business. Validarea obiectivului si a scopului proiectului; Planificarea etapelor de executie si implementare; Revizuirea resurselor necesare pentru urmatoarele etape si actualizarea planului de organizare a proiectului; Alocarea resurselor la roluri si responsabilitati, alocarea rolurilor si a responsabilitatilor la fiecare task, pentru etapa de executie; Revizuirea bugetului, tinând cont de ultimele modificari din planul proiectului; Analiza riscului Crearea planului final al proiectului.
Q2. Planificarea (cont) Planificarea platformei Qlikview Enterprise cu urmatoarele activitati: Realizarea modelului dimensional initial Definirea cerintelor pentru ETL (initiala si incrementala) Definirea arhitecturii aplicatiilor Identificarea riscurilor asociate cu arhitectura stabilita si evaluarea nivelului initial de risc
Q3. Executia – iterativa (3 sapt/iter) Dezvoltarea dezvoltarea procesului de încarcare a datelor (configurarea conexiunilor, dezvoltarea scriptului de încarcare initiala a datelor); crearea modelului de date (crearea fisierelor QVD); dezvoltarea interfetei - abordare DAR (Dashboards, Analysis, Reports) Testarea se va verifica daca sursele de date conectate sunt valide; se va verifica corectitudinea expresiilor create; se vor testa panourilor de bord pentru a verifica daca afiseaza indicatorii ceruti; se vor testa diferite scenarii de business; se va verifica daca a fost configurata corect securitatea aplicatiei. Revizuirea si validarea de catre client Rafinarea solutiei
Q4. Implementarea Training-ul utilizatorilor; Managementul metadatelor; Initierea procesului de mentenanta; Migrarea –mutarea aplicatiilor în productie; Suport pentru utilizatori.
Q5. Evaluarea evaluarea aplicatiei BI - mecanisme pentru îmbunatatirea solutiei BI evaluarea managementului proiectului, evaluarea managementului riscurilor, evaluarea echipei de proiect, a rolurilor si a responsabilitatilor asociate.
Agenda 1. Modelarea datelor in BI 2. Advanced analytics (in-memory, big data) 3. Baze de date orientate pe coloane in contextul Big data
Tendintele majore in BI Advanced Analytics Mobile Cloud Social Media
Advanced Analytics O categorie de metode de analiza care pot conduce la schimbarea si imbunatatirea practicilor de business. Instrumentele de analiza traditionale – “BI este astazi ca si citirea unui ziar” date istorice, ruleaza noaptea si produc date istorice Advanced analytics – previzionarea evenimentelor si comportamentelor viitoare, permitand realizarea de analize what-if pentru a prevedea efectele potentiale ale schimbarilor economice
Business Intelligence Advantage (vezi Cursul 1) What is the best that can happen? Optimise What will happen next? Predict What if these trends continue? Statistica l Analysis Why is this happening? Alerts Raw data Clean data Standar d reports Ad hoc reports Query drill down Forecast What actions are needed? Where exactly is the problem? How many, how often, where? What happened? Degree of Intelligence
Advanced Analytics / Predictive Analytics Data Mining Regresii de date Simularea Monte Carlo Previzionarea comportamentului clientilor Segmentarea/clusterizarea clientilor Analiza cosului de cumparaturi Metode de analiza a textului - Text Analytics Previziunea stocurilor Detectarea fraudelor – Anti-Fraud Analytics Big data Analytics
Aplicatii Data Mining Predictive: Clasificare Regresia Detectarea deviatiilor Filtrare colaborativa Descriptive: Clustering Descoperirea de reguli asociative Descoperirea de modele secventiale
Amazon.com si NetFlix Filtrarea colaborativa incearca sa prevada ce alte produse ar vrea clientul sa cumpere pe baza a ce a cumparat deja si a comportamentului altor cumparatori 28
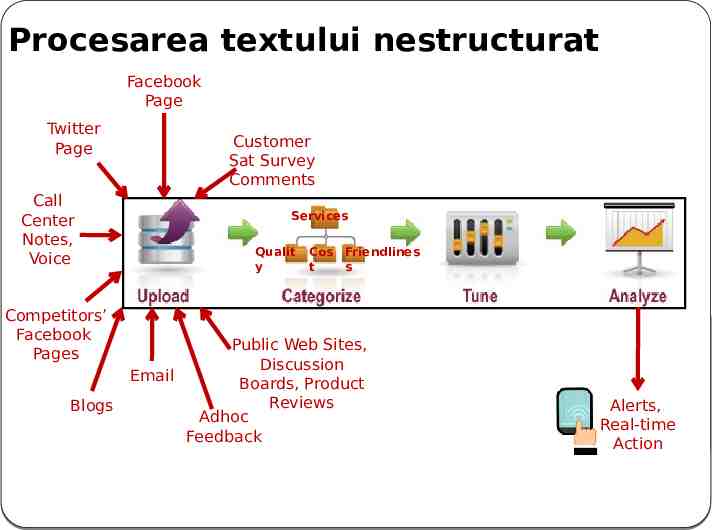
Ce este Text Analytics? transformarea comentariilor nestructurate ale unui client informatii utile, pentru a imbunatati actiunile companiei Wikipedia: un set de instrumente lingvistice, statistice si tehnici de invatare automata care modeleaza si structureaza continutul informational al surselor text pentru BI , analiza aprofundata a datelor si cercetare Tehnici de analiza bazata pe text: Social Analytics Sentiment Analysis Brand Identity Product & Brand Affinity 29 Reputation Driven Online-Economy
Procesarea textului nestructurat Facebook Page Twitter Page Customer Sat Survey Comments Call Center Notes, Voice Competitors’ Facebook Pages Blogs Services Qualit y Cos Friendlines t s Public Web Sites, Discussion Email Boards, Product Reviews Adhoc Feedback 30 Alerts, Real-time Action
Factori : Modelele de procesare Data Mining Baze de date distribuite Baze de date in cluster Baze de date pe coloane In-memory Database Analytics In-database Analytics Real-time Data warehouses Procesare la sursa
“In-memory” BI Incarca setul de date in RAM – raspuns mult mai rapid SO pe 32 biti puteau adresa doar 4 GB de memorie RAM SO pe 64 de biti pot adresa pana la 1 terabyte (TB) RAM Utilizeaza tehnici de compresie complexe si stocarea pe coloane Unele solutii reduc/ elimina agregatele, cuburile Reduce costurile IT si timpul de implementare al aplicatiilor BI
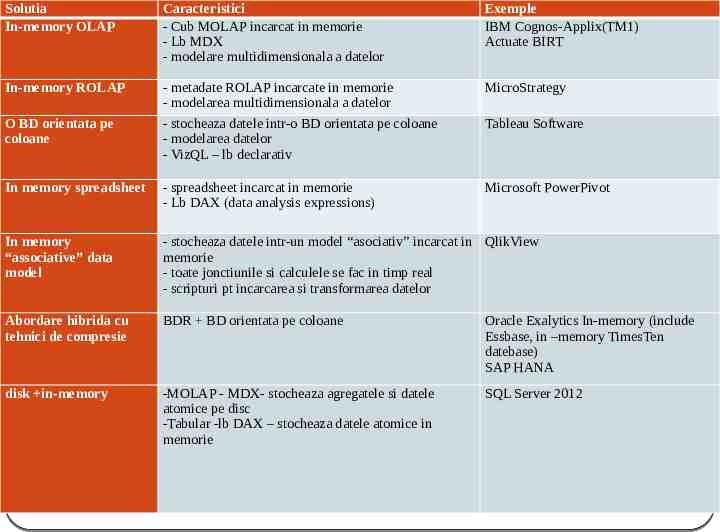
Solutia In-memory OLAP Caracteristici - Cub MOLAP incarcat in memorie - Lb MDX - modelare multidimensionala a datelor Exemple IBM Cognos-Applix(TM1) Actuate BIRT In-memory ROLAP - metadate ROLAP incarcate in memorie - modelarea multidimensionala a datelor - stocheaza datele intr-o BD orientata pe coloane - modelarea datelor - VizQL – lb declarativ MicroStrategy In memory spreadsheet - spreadsheet incarcat in memorie - Lb DAX (data analysis expressions) Microsoft PowerPivot In memory “associative” data model - stocheaza datele intr-un model “asociativ” incarcat in QlikView memorie - toate jonctiunile si calculele se fac in timp real - scripturi pt incarcarea si transformarea datelor Abordare hibrida cu tehnici de compresie BDR BD orientata pe coloane Oracle Exalytics In-memory (include Essbase, in –memory TimesTen datebase) SAP HANA disk in-memory -MOLAP - MDX- stocheaza agregatele si datele atomice pe disc -Tabular -lb DAX – stocheaza datele atomice in memorie SQL Server 2012 O BD orientata pe coloane Tableau Software
Qlikview utilizeaza un model de date “in-memory” - stocheaza toate datele in RAM, deci timp de raspuns mai mici utilizeaza algoritmi de compresie complecsi datele sunt comprimate la 10% din dimensiunea lor originala atunci cand sint incarcate in documentul QlikView utilizeaza diferite surse de date: baze de date (conexiune prin ODBC, OLEDB), fisiere (Excel, CSV, HTML, XML, etc. ) exista de asemenea, diferiti conectori la aplicatiile SAP, Salesforce, retele sociale cum ar Twitter.
Qlikview script de incarcare –poate fi utilizat pt a extrage, transforma si incarca datele in modelul de date sau pt a stoca modelul (inclusiv datele) pe disc in fisiere intermediare (QVD). datele sunt stocate la nivel de detaliu, toate agregatele se realizeaza “on the fly” selectiile facute de utilizator se propaga in cascada prin tot modelul de date. Orice selectie facuta in documentul Qlikview este automat aplicata pe intregul model de date. aplicatiile QlikView pot rula pe multipli clienti/SO
Big Data Analytics Cat de multe date? Google proceaza 20 PB pe zi Facebook are 2.5 PB de date utilizator 15 TB/zi eBay are 6.5 PB de date utilizator 50 TB/zi Ce tipuri de date? Date relationale Text (Web) Date semistructurate (XML) Date sub forma de graf Social Network, Semantic Web (RDF), Streaming Data Datele se pot scana o singura data
Big data : Volum, Viteza and Varietate Volum: companiile se confrunta cu tera sau chiar petabytes de informatii. 350 bilioane de citiri de contor pentru a previziona consumul de energie Viteza: Existe procese care sunt sensibile la timp, ex detectarea fraudelor Parcurgerea a 5 milioane de tranzactii de vanzare zilnic pentru a detecta fraude Analiza 500 milioane apeluri zilnice de la clienti pentru a prevedea mai rapid nemultumirile clientilor Varietate: text, sensor data, audio, video, click streams, fisiere log Filme provenite de la camerele de supraveghere Exploatarea cresterii de 80% a datelor sub forma de imagini, video si documente pentru cresterea satisfactiei clientilor
BIG DATA nu este doar HADOOP Understand and navigate federated big data sources Federated Discovery and Navigation Manage & store huge volume of any data Hadoop File System MapReduce Structure and control data Data Warehousing Manage streaming data Stream Computing Analyze unstructured data Text Analytics Engine Integrate and govern all data sources Integration, Data Quality, Security, Lifecycle Management, MDM
Tipuri de instrumente folosite de obicei in Big Data Unde are loc procesarea? Distribuita Unde sunt stocate datele? Stocare distribuita (ex: Amazon s3) Care este modelul de procesare? Procesare distribuita (Map Reduce) Cum sunt stocate si indexate datele? Schema performanta, indiferent de baza de date Ce operatii se realizeaza pe date? Procesare analitica/Semantica (Ex. RDF/OWL)
Apache Hadoop 2008 – mai intai Yahoo, Ebay sau Facebook platforma open source procesare distribuita pe clustere de servere standard “de facto” Java based framework modele de procesare paralela cod in orice limbaj contemporan (API) SCALABILITATE, ROBUST Hadoop Distributed File System (HDFS): stocare in cluster MapReduce: motor ce procesare paralela management distribuit al resurselor
Agenda 1. Modelarea datelor in BI 2. Advanced analytics (in-memory, big data) 3. Baze de date orientate pe coloane in contextul Big data
Dificultati in analiza datelor Big data – volumul, varietatea, diversitatea – genereaza dificultati in culegerea, curatarea si procesarea datelor utilizand BD clasice Michael Stonebraker, profesor MIT – modelul relational clasic este invechit, prea lent
In 2010 Un studiu al IDC prognoza ca in urmatorii 5 ani: Majoritatea depozitelor de date vor fi stocate pe coloane; Cele mai multe BD pentru OLTP (On-Line Transaction Processing) vor fi completate sau inlocuite de o baza de date in memory; Cele mai multe servere de baze de date mari vor realiza scalabilitate orizontala prin clusterizare; Multe dintre problemele cu colectarea datelor si raportare vor fi rezolvate cu baze de date care nu vor avea nici o schema formala
Bazele de date orientate pe coloane In 1969 – TAXIR - destinat domeniului biologiei. In 1976, sistemul RAPID pentru procesarea datelor provenite din recensamântul populatiei si al locuintelor din Canada. Sybase IQ , aparut la începutul anilor ’90 Solutie foarte performanta de BI Multa vreme singurul SGBD orientat pe coloane disponibil comercial.
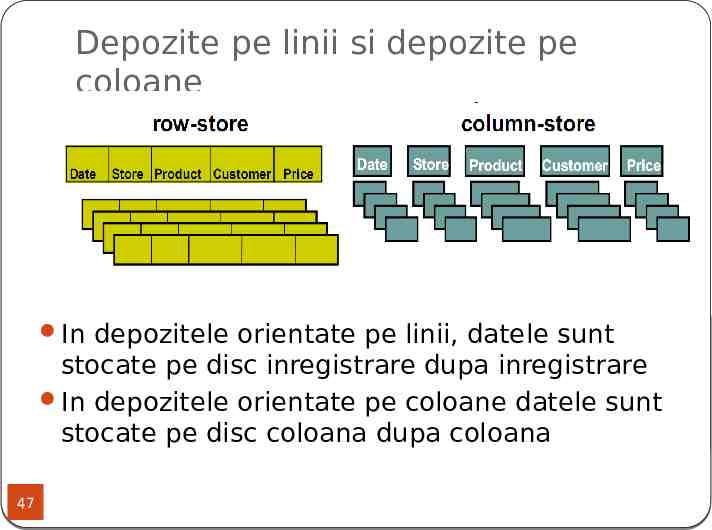
Depozite pe linii si depozite pe coloane Figura preluata din [2] In depozitele orientate pe linii, datele sunt stocate pe disc inregistrare dupa inregistrare In depozitele orientate pe coloane datele sunt stocate pe disc coloana dupa coloana 47
De ce depozite orientate pe coloane? Punand informatiile similare impreuna, minimizeaza timpul pentru citirea discului Pot fi mult mai rapide pentru anumite tipuri de aplicatii Incarca doar coloanele necesare intr-o interogare Efectele cache sunt mai bune Compresie mai buna (valori similare ale atributelor intr-o coloana) Pot functiona mai lent pentru alte aplicatii: OLTP cu multe linii de inserat 48
Depozite pe linii, depozite pe coloane Depozit pe linii Depozit pe coloane ( ) Se adauga/modifica usor inregistrari ( ) Trebuie sa citeasca doar datele relevante (-) Pot citi date care nu sunt necesare (-) Scrierile de tupluri necesita accesari multiple depozitele orientate pe coloane sunt potrivite pentru depozite mari de date in care se realizeaza intensiv operatii de citire, sau in care aceste operatii sunt preponderente: DW, OLAP/DSS 49
Optimizarea executiei orientate pe coloane Optimizarile sunt diferite in cazul bazelor de date orientate pe coloane Compresie - entropia scazuta - rate de compresie ridicate Materializare intarziata Iterarea blocurilor Join invizibil 50
Tehnici de procesare paralela Massive Parallel Processing -MPP (grid computing sau computer cluster)– fiecare dintre procesoare e conectat la propria structura persistenta de stocare, datele fiind distribuite; pot fi adaugate un numar nelimitat de procesoare Symmetric Multi-Processing – SMP- mai multe procesoare identice se conecteaza la o singura memorie partajata, partajeaza sistemele de I/O si sunt controlate de o singura instanta de SO care le trateaza in mod egal
Exemple pe piata? Big Table Vertica SAP HANA
VERTICA un SGBD relational, distribuit, paralel unul dintre putinele SGBD-uri care este utilizat pe scara larga în sisteme critice de business peste 500 de implementari de productie ale Vertica, cel putin 3 dintre ele avand peste 1 petabyte dimensiune Vertica a fost conceput în mod explicit pentru sarcini analitice
Avantaje Vertica este conceput pentru a reduce operatiile de I/E pe disc - abordarea orientata pe coloane este scris nativ pentru suport grid computing interogarile sunt de 50-200 de ori mai rapide decât la bazele de date orientate pe linii. arhitectura MPP ofera o scalabilitate mai buna - poate fi realizata prin adaugarea de noi servere în arhitectura grid. utilizeaza mai multi algoritmi de compresie, în functie de tipul de date, cardinalitate si ordinea de sortare a fiecarei coloane (selectat automat prin esantionare) raport de compresie 8-13 ori fata de date originale
Modelul de date Vertica Dpdv logic – datele sunt privite ca tabele de coloane Dpdv fizic - datele sunt organizate in proiectii, subseturi de date sortate ale unei tabele; pot exista oricate proiectii cu diverse combinatii de coloane si ordini de sortare Cel putin o superproiectie care sa contina toate coloanele tabelei de referinta un sistem de stocare distribuita complet implementat, care atribuie tuplurile pe diferite noduri de calcul. Suporta INSERT, UPDATE, DELETE pentru actualizarea datelor si toate comenzile SQL de interogare a datelor
Tablete Tabelele de mari dimensiuni sunt sparte dupa linii in TABLETE Tabletele pastreaza intervale contigue de linii Clientii pot alege cheile liniilor pentru a obtine localizarea Scopul este de a segmenta in tablete de 100-200 MB Fiecare masina server gestioneaza de obicei in jur de 100 tablete Recuperare rapida: Fiecare din 100 masini preiau o tableta pentru masina care cade Echilibrarea fina a incarcarii Migrarea tabelelor de pe masini supraincarcate Masinile Master iau deciziile referitoare la echilibrarea incarcarii
SAP HANA Platforma pentru analize in timp real si aplicatii in timp real Baza de date pe coloane, in-memory Motor de calcul in-memory Componente software optimizate pentru hardware-ul de la Dell, Cisco, IBM, HP, Fujitsu si Intel , foloseste din plin memoriile flash Conceput în jurul unei arhitecturi multi-core (cel puţin 1.000 de nuclee) Implementeaza paralelizarea dinamica si partitionare dinamica, atât pentru OLAP cat si pentru volumul de lucru OLTP, prin algoritmi genetici
Avantaje Motorul SAP foloseste un depozit pe coloane in memorie pentru a obţine performanţa în operaţiunile de scanare, grupare si de agregare. scaneaza 2 milioane de înregistrari pe milisecunda pe nucleu si peste 10 milioane de agregari complexe calculate pe secunda pe nucleu. Din 2013 – SAP HANA in cloud






