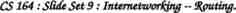Data Mining and Knowledge Discovery in Databases






























36 Slides485.00 KB
Data Mining and Knowledge Discovery in Databases
Outline What is Data Mining and KDD? Characteristics Applications Methods Packages & Close Relatives
What is Data Mining & KDD? “The process of identifying hidden patterns and relationships within data” or “Data mining helps end users extract useful business information from large databases”
What’s the Appeal? Hidden nuggets of valuable information buried deep within a mountain of otherwise unremarkable data Pervasive data Seek competitive advantage
The Challenge 5102018890521200153945819900000000141988122944882199608162100000010100010000000 1100003111110000000001003130200000000000000202001000000000000000000000000000043 4388888888424243424333012202022200001010010000000441000000001100000000000000000 1000001000000000000000000000000000000000000000000000000019981027510201896060120 0212694096800000015901998090337981199809173100100000100010000000110000320002000 0001000000012399000000000000200222200313100312000000000000000042438888888888424 3424233212121222200000010110000002441000000000100200000000000000000000100000000 0000000000000000000000000000000000000000019981230510201897020320001862692920000 0047091998021356971199802273100000100100010000000001101100000020000100000000021 0110001000000000001000000000000100011000000011100338888222233113233433300000011 0000011101001100102000100000000100000000100000000000000000000000000000000000000 0000000000000000000000000019981221510201899093020052008986730000019410199901127 5981199901263100100010100010000000001111101111122010100000111230010010000001021 0002200000000002000000000000011133438888434242424342423300000011110000010110010 0002441000000000100200000001001010000000100000000000000000000000000000000000000 0000000000019990525510201899122720093540515830000014484199705271797119970610310 0000010110010000000100000311120120000100100101200011110010000110100120000000000 0100000000001010132438888888888224242433100000001002100001110010011230100000010 0000200010000000000110000100000000100000100000000000000001000000000000000001998 1117510201899122720093540515830000014484199705271797219980616310000001011001000 0000110100311111121000100000202210012220220020221222201000000000000000001010011 0032434343213242214242423300210021000011110110000011223100110000010000001000000 0000110000100000000100000100000000000000000000000000000000001998122351020190001
Process: Knowledge Discovery In Databases database database cleaning & integration data warehouse modify data selection modify data selection collect and transform data mining modify methods, parameters data mining engines, models discovered patterns user interface and expert knowledge domain evaluation & presentation
Context Where you stand on Data Mining depends on where you sit: Business User Researcher Computer Scientist
Data Mining Might Mean Statistics Visualization Artificial intelligence Machine learning Database technology Neural networks Pattern recognition Knowledge-based systems Knowledge acquisition Information retrieval High performance computing And so on.
What’s needed? Suitable data Computing power Data mining software Skilled operator who knows both the nature of the data and the software tools Reason, theory, or hunch
Typical Applications of Data Mining & KDD Marketing Market Basket Analysis Customer Relationship Management New Product Development
Typical Applications of Data Mining & KDD Financial Services Credit Approval Fraud Detection Marketing
Typical Applications of Data Mining & KDD Health Care Epidemiological Analysis - incidence and prevalence of disease in large populations and detection of the source and cause of epidemics of infectious disease Knowledge for funding Policy, programs
Two Basic Approaches Supervised A dependent or target variable Unsupervised “Pure Data Mining” Fewer assumptions Typically used for clustering techniques
Automation The ability to aim a tool at some data and push a button Some methods of KDD/Data mining are more suitable for automation than others
Seven Basic Methods: 1. 2. 3. 4. 5. 6. 7. Decision Trees (Artificial) Neural Networks Cluster/Nearest Neighbour Genetic Algorithms/Evolutionary Computing Bayesian Networks Statistics Hybrids
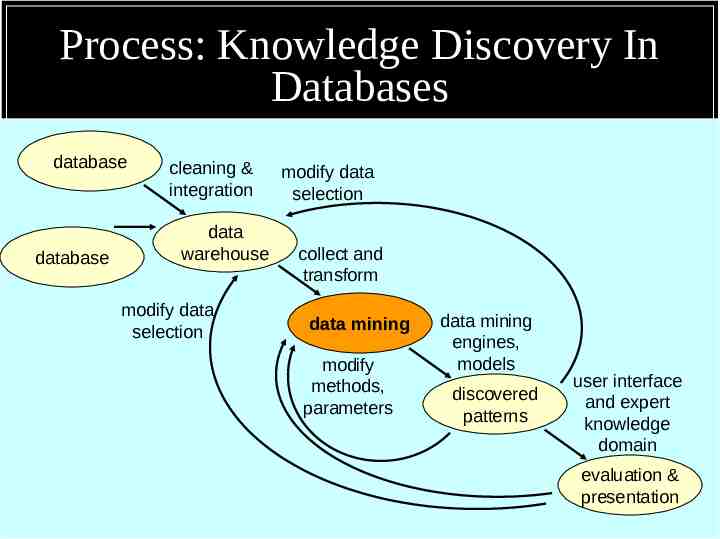
Decision Trees Graphical representations of relationships with data Excel at Classification & Prediction Models
Sample of a Decision Tree gender male female age good health? 65 married? 65 yes no urban? yes no - yes pet owner? yes no - pet owner? no yes no - -
Decision Trees Strengths Easily understood and interpreted Represent complexity in a compact form Handle non-linear data well Relatively well suited to automation. Weaknesses Large trees with large numbers of variables become difficult to understand Missing data must be appropriately managed in construction and use of the models
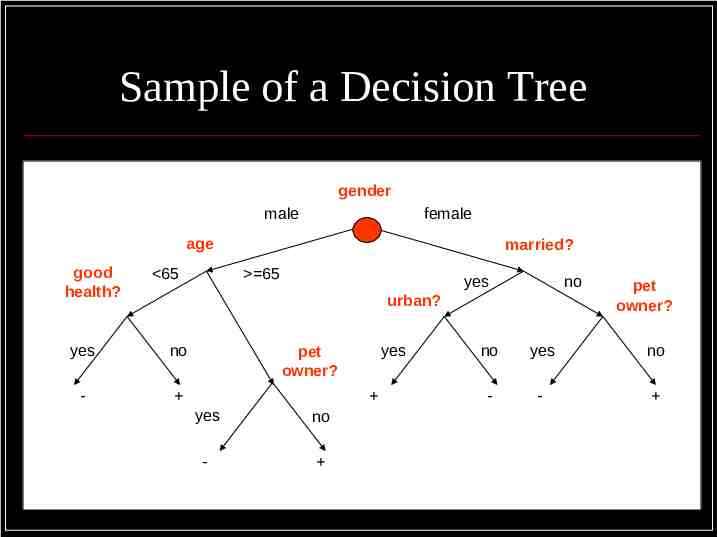
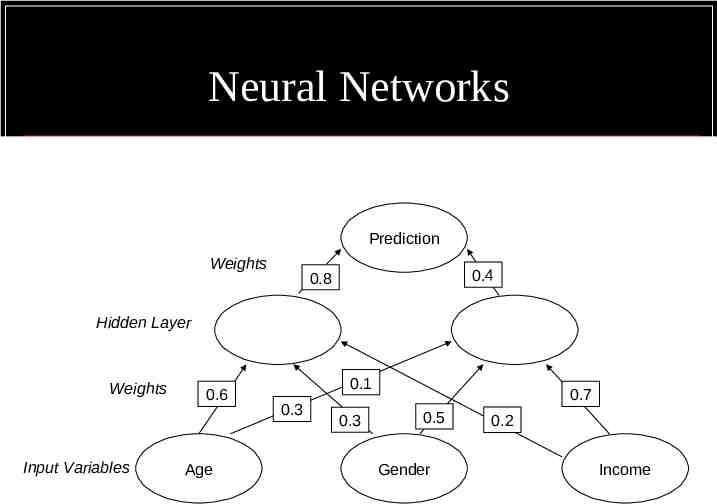
Neural Networks Derived from Artificial Intelligence Research Modelled on the Human Neuron
Neural Networks Prediction Weights 0.4 0.8 Hidden Layer Weights Input Variables 0.6 Age 0.1 0.3 0.3 0.7 0.5 Gender 0.2 Income
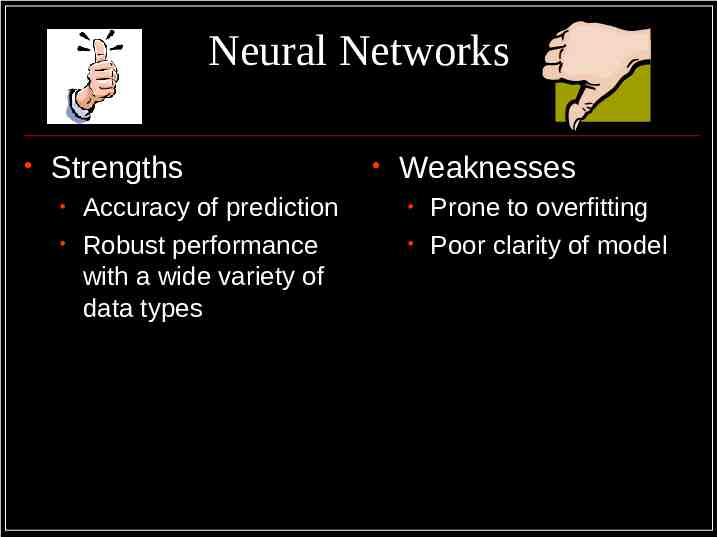
Neural Networks Strengths Accuracy of prediction Robust performance with a wide variety of data types Weaknesses Prone to overfitting Poor clarity of model
Clustering/Nearest Neighbour Aim to assign “like” records to a group Groups assigned according to some target variable or criteria Nearest neighbour used for prediction
Clustering/Nearest Neighbour Applications: Text processing: search engines Image processing: radiology/image processing Fraud detection: outliers
Clustering/ Nearest Neighbour Strengths Easily understood and interpreted Easily implemented in basic situations Weaknesses complex data not well suited to automation (much preprocessing required)
Genetic Algorithms/ Evolutionary Computing Grounded in Darwin – applied using mathematics Require a way to represent a solution to a problem a way to test the “fitness” of the solution Solutions are mathematically “mutated” Fittest solutions survive Convergence
Genetic Algorithms/ Evolutionary Computing Strengths Suited to novel problems that are poorly understood Suitable where data is dirty or missing May be useful where other methods cannot be applied Weaknesses Not easily automated Require creativity in their application
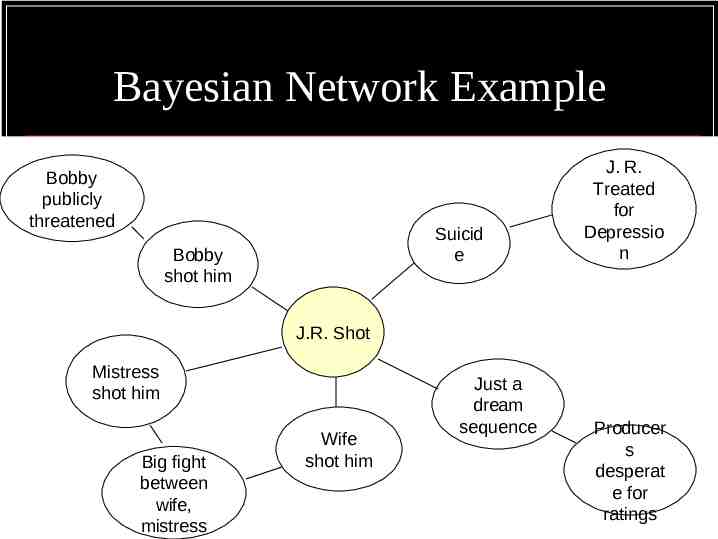
Bayesian Networks Based on Bayes’ rule: P(a b) P(b a) * P(a) / P(b) Can construct networks of linked events, each with prior probabilities
Bayesian Network Example Bobby publicly threatened Suicid e Bobby shot him J. R. Treated for Depressio n J.R. Shot Mistress shot him Big fight between wife, mistress Wife shot him Just a dream sequence Producer s desperat e for ratings
Bayesian Networks Strengths Clarity of the resulting models Good precision in predicting Easily adapt to new probabilities Weaknesses Time consuming to construct and maintain Poor at predicting rare events
Statistics With an outcome or dependent variable: Correlations ANOVA Regression Used by themselves or to confirm findings of another method
Statistics Strengths “Gold Standard” – valid and trusted in scientific circles Weaknesses Limits findings to those techniques that are applied and their associated limitations (normality, linearity, and so on)
Hybrids Techniques used in combination Example: use of a genetic algorithm to identify target variables for inclusion in a neural network model
Recap Data Mining is the core activity or method within a process of Knowledge Discovery in Databases Done in order to find useful information in large amounts of data not possible using “conventional” approaches Variety of methods Knowledge of data domain, methods, as well as creativity
Data Mining Packages Major vendors of database/data management products (IBM, SPSS, Oracle PeopleSoft, SAS, and so on) Added as a component of turnkey packages May incorporate several methods (SAS Enterprise Miner) Single method (TreeAge Software Inc.: a dedicated decision tree product)
How to implement? Do it yourself (you know the data domain) Put a team together (domain and method specialists) Hire a consultant (who knows both your domain and the tools) Vertical markets in data mining
Close Relatives of Data Mining On-Line Analytical Processing (OLAP) Pivot tables in spreadsheets General statistical packages Intelligent Data Analysis – comprises the use of data mining methods in the analysis of “small” datasets