Scheduling in Linux and Windows 2000 CS 431 Sanjay Kumar (01D07041)

































34 Slides445.00 KB
Scheduling in Linux and Windows 2000 CS 431 Sanjay Kumar (01D07041) Sanjay Kumar Ram (01D07042)
Linux kernel Linux process Scheduling policy Data Structures and Scheduling Algorithm in Uniprocessor System Scheduling algorithm for multiprocessor Scheduling in windows 2000
Linux Kernel Kernel subsystem overview
Linux Processes Three class of processes Interactive processes Batch processes Real-time processes Linux processes have the following states: Running Waiting Stopped Zombie
Scheduling Policy Linux kernel is non-preemptive but processes are preemptive The set of rules used to determine when and how selecting a new process to run is called scheduling policy Linux scheduling is based on the time-sharing technique -several processes are allowed to run "concurrently“ CPU time is roughly divided into "slices“ scheduling policy is also based on ranking processes according to their priority Static priority - assigned by the users to real-time processes and ranges from 1 to 99, and is never changed by the scheduler Dynamic priority - the sum of the base time quantum (the base priority of the process) and of the number of ticks of CPU time left to the process before its quantum expires in the current epoch
Scheduling Policy (contd.) Process Preemption How Long Must a Quantum Last? When the dynamic priority of the currently running process is lower than the process waiting in the runqueue A process may also be preempted when its time quantum expires Quantum duration too short - system overhead caused by task switching becomes excessively high Quantum duration too long - processes no longer appear to be executed concurrently, degrades the response time of interactive applications, and degrades the responsiveness of the system The rule of thumb adopted by Linux is: choose a duration as long as possible, while keeping good system response time
Data Structures and Scheduling Algorithm in Uniprocessor System The Linux scheduling algorithm works by dividing the CPU time into epochs Each process has a base time quantum In a single epoch, every process has a specified time quantum epoch ends when all runnable processes have exhausted their quantum the time-quantum value assigned by the scheduler to the process if it has exhausted its quantum in the previous epoch users can change the base time quantum of their processes by using the nice( ) and setpriority( ) system calls The INIT TASK macro sets the value of the base time quantum of process 0 (swapper) to DEF PRIORITY, which is approx. 200ms
Data Structures and Scheduling Algorithm in Uniprocessor System (contd.) The first entry in the process table is the special init process Task struct - represents the states of all tasks running in the systems schedule policy - SCHED OTHER, SCHED FIFO, SCHED RR field for process state – running, waiting, stopped, zombie a field that indicates the processes priority counter - a field which holds the number of clock ticks a doubly linked list (next task and prev task) - to keep track of all executing processes mm struct - contains a process's memory management information process ID and group ID are also stored fs struct - File specific process data fields that hold timing information
Data Structures and Scheduling Algorithm in Uniprocessor System (contd.) Each time the scheduler is run it does the following: Kernel work - scheduler runs the bottom half handlers and processes the scheduler task queue Current process current process must be processed before another process can be selected to run If the scheduling policy of the current processes is round robin then it is put onto the back of the run queue If the task is INTERRUPTIBLE and it has received a signal since the last time it was scheduled then its state becomes RUNNING If the current process has timed out, then its state becomes RUNNING If the current process is RUNNING then it will remain in that state Processes that were neither RUNNING nor INTERRUPTIBLE are removed from the run queue
Data Structures and Scheduling Algorithm in Uniprocessor System (contd.) Process Selection most deserving process is selected by the scheduler real time processes are given higher priority than ordinary processes when several processes have the same priority, the one nearest the front of the run queue is chosen when a new process is created the number of ticks left to the parent is split in two halves, one for the parent and one for the child priority and counter fields are used both to implement timesharing and to compute the process dynamic priority
Data Structures and Scheduling Algorithm in Uniprocessor System (contd.) schedule( ) Function implements the scheduler. finds a process in the runqueue list and then assigns the CPU to it Direct invocation 1. Inserts current in the proper wait queue 2. Changes the state of current either to TASK INTERRUPTIBLE or to TASK UNINTERRUPTIBLE 3. Invokes schedule( ) 4. Checks if the resource is available; if not, goes to step 2 5. Once the resource is available, removes current from the wait queue Lazy invocation When current has used up its quantum of CPU time; this is done by the update process times( ) function When a process is woken up and its priority is higher than that of the current process; performed by the reschedule idle( ) function, which is invoked by the wake up process( ) function When a sched setscheduler( ) or sched yield( ) system call is issued
Data Structures and Scheduling Algorithm in Uniprocessor System (contd.) Actions performed by schedule( ) Before actually scheduling a process, the schedule( ) function starts by running the functions left by other kernel control paths in various queues The function then executes all active unmasked bottom halves Scheduling value of current is saved in the prev local variable and the need resched field of prev is set to 0 a check is made to determine whether prev is a Round Robin real-time process. If so, schedule( ) assigns a new quantum to prev and puts it at the bottom of the runqueue list if state is TASK INTERRUPTIBLE, the function wakes up the process schedule( ) repeatedly invokes the goodness( ) function on the runnable processes to determine the best candidate when counter field becomes zero, schedule( ) assigns to all existing processes a fresh quantum, whose duration is the sum of the priority value plus half the counter value
Data Structures and Scheduling Algorithm in Uniprocessor System (contd.) goodness( ) function identify the best candidate among all processes in the runqueue list. It receives as input parameters prev (the descriptor pointer of the previously running process) and p (the descriptor pointer of the process to evaluate) The integer value c returned by goodness( ) measures the "goodness" of p and has the following meanings: c -1000, p must never be selected; this value is returned when the runqueue list contains only init task c 0, p has exhausted its quantum. Unless p is the first process in the runqueue list and all runnable processes have also exhausted their quantum, it will not be selected for execution. 0 c 1000, p is a conventional process that has not exhausted its quantum; a higher value of c denotes a higher level of goodness. c 1000, p is a real-time process; a higher value of c denotes a higher level of goodness.
Scheduling algorithm for multiprocessor The Linux scheduler is defined in kernel/sched.c. The new scheduler have been designed to accomplish specific goals: Implement fully O(1) scheduling, Every algorithm in the new scheduler completes in constant-time, regardless of the number of running processes or any other input. Implement perfect SMP scalability, Each processor has its own locking and individual runqueue. Implement improved SMP affinity, Naturally attempt to group tasks to a specific CPU and continue to run them there. Only migrate tasks from one CPU to another to resolve imbalances in runqueue sizes.
Scheduling algorithm for multiprocessor (contd.) Provide good interactive performance, Even during considerable system load, the system should react and schedule interactive tasks immediately. Provide fairness, No process should find itself starved of timeslice for any reasonable amount of time. Likewise, no process should receive an unfairly high amount of timeslice. Optimize for the common case of only 1-2 runnable processes, yet scale well to multiple processors each with many processes Runqueues It is the basic data structure in the scheduler. It is defined in kernel/sched.c as struct runqueue. It is the list of runnable processes on a given processor; there is one runqueue per processor. Each runnable process is on exactly one runqueue. It additionally contains per-processor scheduling information.
Scheduling algorithm for multiprocessor (contd.) A group of macros is used to obtain specific runqueues. cpu rq(processor) returns a pointer to the runqueue associated with the given processor. this rq() returns the runqueue of the current processor. task rq(task) returns a pointer to the runqueue on which the given task is queued. this rq lock() locks the current runqueue rq unlock(struct runqueue *rq) unlocks the given runqueue. double rq lock() and double rq unlock(), to avoid deadlock
Scheduling algorithm for multiprocessor (contd.) The Priority Arrays Each runqueue contains two priority arrays, the active and the expired array. Each priority array contains one queue of runnable processors per priority level. Priority arrays are the data structure that provide O(1) scheduling. It also contain a priority bitmap used to efficiently discover the highest priority runnable task in the system. Each priority array contains a bitmap field that has at least one bit for every priority on the system.
Scheduling algorithm for multiprocessor (contd.) Finding the highest priority task on the system is therefore only a matter of finding the first set bit in the bitmap. Each priority array also contains an array called queue of struct list head queues, one queue for each priority. The Linux O(1) scheduler algorithm.
Scheduling algorithm for multiprocessor (contd.) Recalculating Timeslices The new Linux scheduler alleviates the need for a recalculate loop. Instead, it maintains two priority arrays for each processor: 1. active array, contains all the tasks in the associated runqueue that have timeslice left. 2. expired array , contains all the tasks in the associated runqueue that have exhausted their timeslice. When each task's timeslice reaches zero, its timeslice is recalculated before it is moved to the expired array.
Scheduling algorithm for multiprocessor (contd.) Recalculating all the timeslices is then as simple as just switching the active and expired arrays. Because the arrays are accessed only via pointer, switching them is as fast as swapping two pointers. This swap is a key feature of the new O(1) scheduler. Instead of recalculating each process's priority and timeslice all the time, the O(1) scheduler performs a simple two-step array swap.
Scheduling algorithm for multiprocessor (contd.) Sleeping and waking up
Scheduling algorithm for multiprocessor (contd.) The load balancer
Scheduling in windows 2000 Windows 2000 scheduler: Concern is with threads not processes i.e. threads are scheduled, not processes Threads have priorities 0 through 31 31 16 “real-time” levels 16 15 15 variable levels 1 0 i Used by zero page thread Used by idle thread(s)
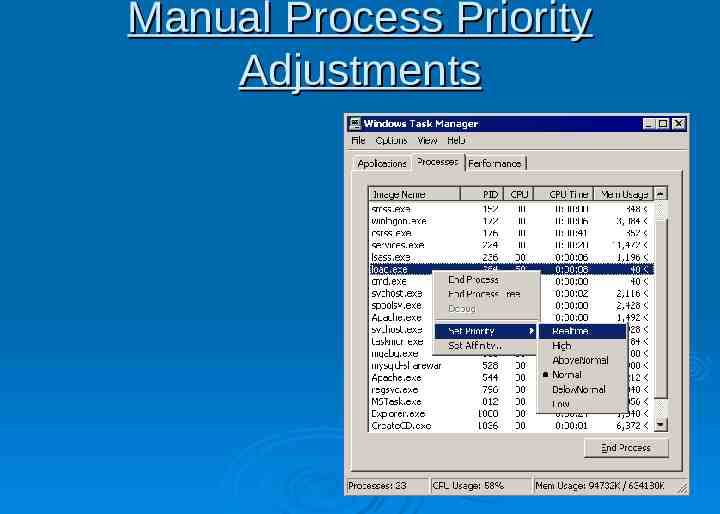
Manual Process Priority Adjustments
Thread Scheduling Strictly priority driven 32 queues (FIFO lists) of ready threads One queue for each priority level Queues are common to all CPUs When thread becomes ready, it: either runs immediately, or is inserted at the tail end of the Ready queue for its current priority On a uniprocessor, highest priority Ready thread always runs Time-sliced, round-robin within a priority level
Thread Scheduling Multiprocessor Issues On a multiprocessor, highest-priority n threads will always run (subject to Affinity, explained later) No attempt is made to share processors “fairly” among processes, only among threads Tries to keep threads on the same CPU
Scheduling Scenarios Preemption A thread becomes ready at a higher priority than the running thread Lower-priority thread is preempted Preempted thread goes to the tail of its Ready queue
Scheduling Scenarios (contd.) Voluntary switch When the running thread gives up the CPU Waiting on a dispatcher object Termination Explicit lowering of priority Schedule the thread at the head of the next non-empty Ready queue Running thread experiences quantum end Priority is decremented unless at thread base priority Thread goes to tail of Ready queue for its new priority May continue running if no equal or higher-priority threads are Ready – i.e. it “gets” the new quantum
Priority Adjustments Threads in “dynamic” classes can have priority adjustments applied to them (Boost or Decay) Idle, Below Normal, Normal, Above Normal and High Carried out upon wait completion Used to avoid CPU starvation No automatic adjustments in “real-time” class Priority 16 and above Scheduling is therefore “predictable” with respect to the “real-time” threads Note though that this does not mean that there are absolute latency guarantees
Priority Boosting Priority boost takes place after a wait Occurs when a wait (usually I/O) is resolved Slow devices / long waits big boost Fast devices / short waits small boost Boost is applied to thread’s base priority Does not go over priority 15 Keeps I/O devices busy
CPU Starvation Balance Set Manager looks for “starved” threads Special boost applied BSM is a thread running at priority 16, waking up once per second Looks at threads that have been Ready for 4 seconds or more Boosts up to 10 Ready threads per pass Priority 15 Quantum is doubled Does not apply in real-time range
Multiprocessor Support By default, threads can run on any available processor Soft affinity (introduced in NT 4.0) Every thread has an “ideal processor” When thread becomes ready: if “ideal” is idle, it runs there else, if previous processor is idle, it runs there else, may look at next thread, to run on its ideal processor
Multiprocessor Support (contd.) Hard affinity Restricts thread to a subset of the available CPUs Can lead to: threads getting less CPU time that they normally would
References http://iamexwiwww.unibe.ch/studenten/schlpbch/linuxSch eduling/LinuxScheduling.html http://oopweb.com/OS/Documents/tlk/VolumeFrames.ht ml http://www.samspublishing.com/articles/article.asp?p 10 1760&rl 1 http://www.oreilly.com/catalog/linuxkernel/chapter/ch10.h tml G. M. Candea and M. B. Jones, “ Vassal: Loadable Scheduler Support for Multi-Policy Scheduling,” Proceedings of the 2nd USENIX Windows NT Symposium Seattle, Washington, August 3–4, 1998






