Sample Undergraduate Lecture: MIPS Instruction Set Architecture



















21 Slides259.00 KB
Sample Undergraduate Lecture: MIPS Instruction Set Architecture Jason D. Bakos Optics/Microelectronics Lab Department of Computer Science University of Pittsburgh
Outline Instruction Set Architecture MIPS ISA – Instruction set – Instruction encoding/representation – Example code Pipelining – Concepts – Hazards Pipeline enhancements: performance University of Pittsburgh MIPS Instruction Set Architecture 2
Instruction Set Architecture Instruction Set Architecture (ISA) – Usually defines a “family” of microprocessors Examples: Intel x86 (IA32), Sun Sparc, DEC Alpha, IBM/360, IBM PowerPC, M68K, DEC VAX – Formally, it defines the interface between a user and a microprocessor ISA includes: – Instruction set – Rules for using instructions Mnemonics, functionality, addressing modes – Instruction encoding ISA is a form of abstraction – Low-level details of microprocessor are “invisible” to user University of Pittsburgh MIPS Instruction Set Architecture 3
Instruction Set Architecture ISA abstraction is a misnomer Many processor implementation details are revealed through ISA Example: – Motorola 6800 / Intel 8085 (1970s) 1-address architecture: (A) (A) (addr) ADDA addr – Intel x86 (1980s) 2-address architecture: (A) (A) (B) ADD EAX, EBX – MIPS (1990s) 3-address architecture: ( 2) ( 3) ( 4) ADD 2, 3, 4 – Advancements in fabrication technology University of Pittsburgh MIPS Instruction Set Architecture 4
MIPS Architecture Design “philosophies” for ISAs: RISC vs. CISC Execution time – instructions per program * cycles per instruction * seconds per cycle MIPS is implementation of a RISC architecture MIPS R2000 ISA – Designed for use with high-level programming languages small set of instructions and addressing modes, easy for compilers – Minimize/balance amount of work (computation and data flow) per instruction allows for parallel execution – Load-store machine large register set, minimize main memory access – fixed instruction width (32-bits), small set of uniform instruction encodings minimize control complexity, allow for more registers University of Pittsburgh MIPS Instruction Set Architecture 5
MIPS Instructions MIPS instructions fall into 5 classes: – – – – Arithmetic/logical/shift/comparison Control instructions (branch and jump) Load/store Other (exception, register movement to/from GP registers, etc.) Three instruction encoding formats: – R-type (6-bit opcode, 5-bit rs, 5-bit rt, 5-bit rd, 5-bit shamt, 6-bit function code) – I-type (6-bit opcode, 5-bit rs, 5-bit rt, 16-bit immediate) – J-type (6-bit opcode, 26-bit pseudo-direct address) University of Pittsburgh MIPS Instruction Set Architecture 6
MIPS Addressing Modes MIPS addresses register operands using 5-bit field – Example: ADD 2, 3, 4 MIPS addresses branch targets as signed instruction offset – – – – relative to next instruction (“PC relative”) in units of instructions (words) held in 16-bit offset in I-type Example: BEQ 2, 3, 12 Immediate addressing – Operand is help as constant (literal) in instruction word – Example: ADDI 2, 3, 64 University of Pittsburgh MIPS Instruction Set Architecture 7
MIPS Addressing Modes (con’t) MIPS addresses jump targets as register content or 26-bit “pseudo-direct” address – Example: JR 31, J 128 MIPS addresses load/store locations – base register 16-bit signed offset (byte addressed) Example: LW 2, 128( 3) – 16-bit direct address (base register is 0) Example: LW 2, 4092( 0) – indirect (offset is 0) Example: LW 2, 0( 4) University of Pittsburgh MIPS Instruction Set Architecture 8
Example Instructions ADD 2, 3, 4 – R-type A/L/S/C instruction – Opcode is 0’s, rd 2, rs 3, rt 4, func 000010 – 000000 00011 00100 00010 00000 000010 JALR 3 – R-type jump instruction – Opcode is 0’s, rs 3, rt 0, rd 31 (by default), func 001001 – 000000 00011 00000 11111 00000 001001 ADDI 2, 3, 12 – I-type A/L/S/C instruction – Opcode is 001000, rs 3, rt 2, imm 12 – 001000 00011 00010 0000000000001100 University of Pittsburgh MIPS Instruction Set Architecture 9
Example Instructions BEQ 3, 4, 4 – I-type conditional branch instruction – Opcode is 000100, rs 00011, rt 00100, imm 4 (skips next 4 instructions) – 000100 00011 00100 0000000000000100 SW 2, 128( 3) – I-type memory address instruction – Opcode is 101011, rs 00011, rt 00010, imm 0000000010000000 – 101011 00011 00010 0000000010000000 J 128 – J-type pseudodirect jump instruction – Opcode is 000010, 26-bit pseudodirect address is 128/4 32 – 000010 00000000000000000000100000 University of Pittsburgh MIPS Instruction Set Architecture 10
Pseudoinstructions Some MIPS instructions don’t have direct hardware implementations – Ex: abs 2, 3 Resolved to: – – – – – bgez 3, pos sub 2, 0, 3 j out pos: add 2, 0, 3 out: – Ex: rol 2, 3, 4 Resolved to: – – – – – addi 1, 0, 32 sub 1, 1, 4 srlv 1, 3, 1 sllv 2, 3, 4 or 2, 2, 1 University of Pittsburgh MIPS Instruction Set Architecture 11
MIPS Code Example for (i 0;i n;i ) a[i] b[i] 10; loop: xor 2, 2, 2 lw 3,n sll 3, 3,2 li 4,a li 5,b add 6, 5, 2 lw 7,0( 6) addi 7, 7,10 add 6, 4, 2 sw 7,0( 6) addi 2, 2,4 blt 2, 3,loop University of Pittsburgh # # # # # # # # # # # # zero out index register (i) load iteration limit multiply by 4 (words) get address of a (assume 216) get address of b (assume 216) compute address of b[i] load b[i] compute b[i] b[i] 10 compute address of a[i] store into a[i] increment i loop if post-test succeeds MIPS Instruction Set Architecture 12
Pipeline Implementation Idea: – – – – – – – – Goal of MIPS: CPI 1 Some instructions take longer to execute than others Don’t want cycle time to depend on slowest instruction Want 100% hardware utilization Split execution of each instruction into several, balanced “stages” Each stage is a block of combinational logic Latency of each stage fits within 1 clock cycle Insert registers between each pipeline stage to hold intermediate results – Execute each of these steps in parallel for a sequence of instructions – “Assembly line” This is called pipelining University of Pittsburgh MIPS Instruction Set Architecture 13
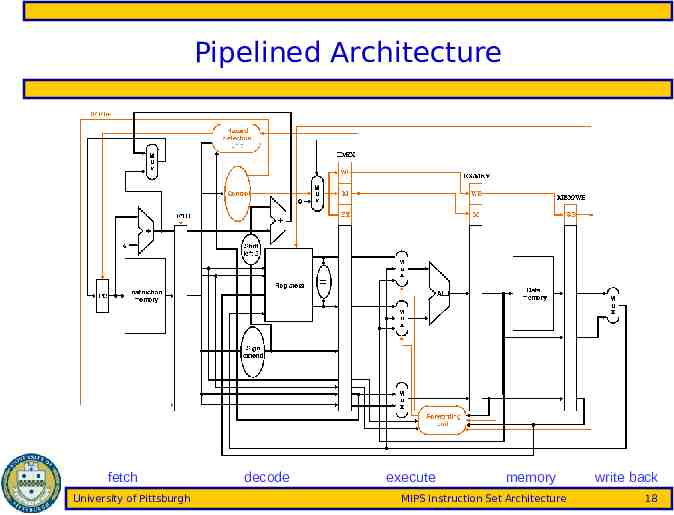
MIPS ISA MIPS pipeline stages – Fetch (F) read next instruction from memory, increment address counter assume 1 cycle to access memory – Decode (D) read register operands, resolve instruction in control signals, compute branch target – Execute (E) execute arithmetic/resolve branches – Memory (M) perform load/store accesses to memory, take branches assume 1 cycle to access memory – Write back (W) write arithmetic results to register file University of Pittsburgh MIPS Instruction Set Architecture 14
Hazards Hazards are data flow problems that arise as a result of pipelining – Limits the amount of parallelism, sometimes induces “penalties” that prevent one instruction per clock cycle – Structural hazards Two operations require a single piece of hardware Structural hazards can be overcome by adding additional hardware – Control hazards Conditional control instructions are not resolved until late in the pipeline, requiring subsequent instruction fetches to be predicted – Flushed if prediction does not hold (make sure no state change) Branch delay slot hazards can use dynamic prediction/speculation, branch – Data hazards Instruction from one pipeline stage is “dependant” of data computed in another pipeline stage University of Pittsburgh MIPS Instruction Set Architecture 15
Hazards Data hazards – Register values “read” in decode, written during write-back RAW hazard occurs when dependent inst. separated by less than 2 slots Examples: – – – – ADD 2, X, X ADD X, 2, X 2, 3 (D) (E) (D) ADD 2, X, X (M) ADD 2, 3, 4 (W) ADD X, 2, X (D) ADD X, – In most cases, data generated in same stage as data is required (EX) Data forwarding – – – – ADD 2, X, X pipe) ADD X, 2, X 2, 3 (E) University of Pittsburgh (M) ADD 2, X, X (W) (E) ADD 2, 3, 4 (out-of- ADD X, 2, X (E) MIPS Instruction Set Architecture ADD X, 16
“Load” Hazards Stalls required when data is not produced in same stage as it is needed for a subsequent instruction – Example: LW 2, 0( X) ADD X, 2 (M) (E) When this occurs, insert a “bubble” into EX state, stall F and D LW 2, 0( X) (W) NOOP (M) ADD X, 2 (E) – Forward from W to E University of Pittsburgh MIPS Instruction Set Architecture 17
Pipelined Architecture fetch University of Pittsburgh decode execute memory MIPS Instruction Set Architecture write back 18
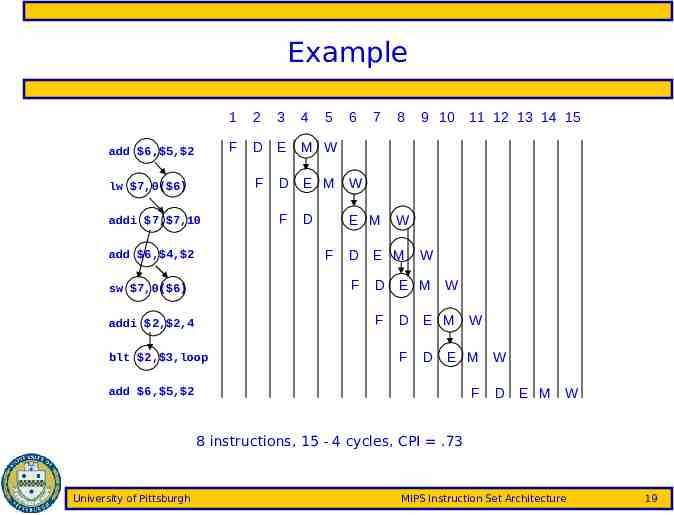
Example add 6, 5, 2 1 2 F D E F lw 7,0( 6) addi 7, 7,10 3 4 5 7 8 D E M W F E M W D D E M F sw 7,0( 6) blt 2, 3,loop 11 12 13 14 15 W D E M F addi 2, 2,4 9 10 M W F add 6, 4, 2 6 W D E M F W D E M F add 6, 5, 2 W D E M W 8 instructions, 15 - 4 cycles, CPI .73 University of Pittsburgh MIPS Instruction Set Architecture 19
Pipeline Enhancements Assume we add branch predictor – Branch predictor success rate 85% – Penalty for bad prediction 3 cycles – Profiler tells us that 10% of instructions executed are branches – Branch speedup (cycles before enhancement) / (cycles after enhancement) 3 / [.15(3) .85(1)] 2.3 – Amdahl’s Law: 1 Speedup 1 Fractionenhanced Fractionenhanced Speedupenhanced – Speedup 1 / (.90 .10/2.3) 1.06 – 6% improvement University of Pittsburgh MIPS Instruction Set Architecture 20
Summary Instruction Set Architecture – ISA is revealing (fabrication technology, architectural implementation) – MIPS ISA Pipelining – Pipeline concepts – Hazards – Example University of Pittsburgh MIPS Instruction Set Architecture 21






