Data Modeling


























36 Slides693.76 KB
Data Modeling
Data Modeling Is just as important with relational data! There’s still a schema – just enforced at the application level Plan upfront for best performance & costs Feedback: “Small collections add up - ” Answer: Smart data modelling will help
2 Extremes M R O SQL Normalize everything NoSQL Embed as 1 piece
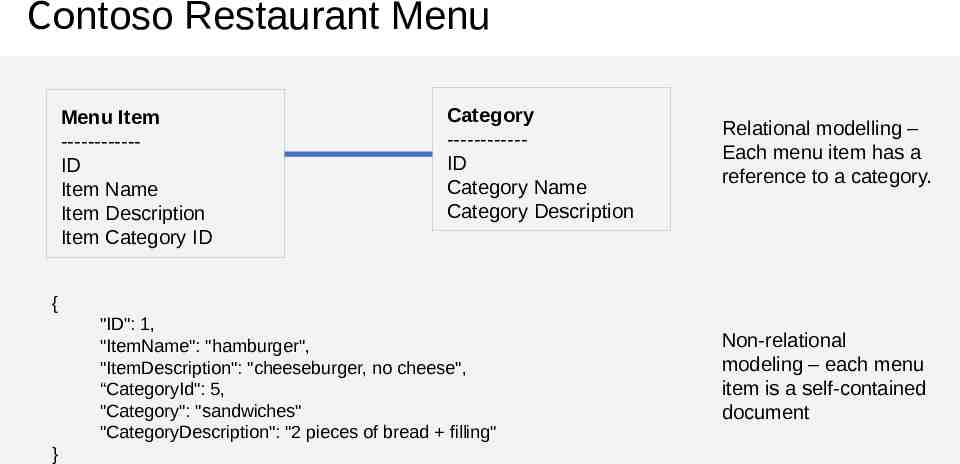
Contoso Restaurant Menu Menu Item -----------ID Item Name Item Description Item Category ID Category -----------ID Category Name Category Description Relational modelling – Each menu item has a reference to a category. { "ID": 1, "ItemName": "hamburger", "ItemDescription": "cheeseburger, no cheese", “CategoryId": 5, "Category": "sandwiches" "CategoryDescription": "2 pieces of bread filling" } Non-relational modeling – each menu item is a self-contained document
Number 1 question “Where are my joins?” “Where are my joins!?!?” Naïve way: Normalize, make 2 network calls, merge client side But! We can model our data in a way to get the same functionality of a join, without the tradeoff
Modeling Challenges #1: To de-normalize, or normalize? To embed, or to reference? #2: Put data types in same collection, or different?
Modeling challenge #1: To embed or reference? Embed { "menuID": 1, "menuName": "Lunch menu", "items": [ {"ID": 1, "ItemName": "hamburger", "ItemDescription":.} {"ID": 2, "ItemName": "cheeseburger", "ItemDescription":.} ] } Reference { "menuID": 1, "menuName": "Lunch menu", "items": [ {"ID": 1} {"ID": 2} ] } {"ID": 1, "ItemName": “hamburger", "ItemDescription":.} {"ID": 2, "ItemName": “cheeseburger", "ItemDescription":.}
When To Embed #1 { "ID": 1, "ItemName": "hamburger", "ItemDescription": "cheeseburger, no cheese", "Category": "sandwiches", "CategoryDescription": "2 pieces of bread filling", "Ingredients": [ {"ItemName": "bread", "calorieCount": 100, "Qty": "2 slices"}, {"ItemName": "lettuce", "calorieCount": 10, "Qty": "1 slice"} {"ItemName": "tomato","calorieCount": 10, "Qty": "1 slice"} {"ItemName": "patty", "calorieCount": 700, "Qty": "1"} } E.g. in Recipe, ingredients are always queried with the item
When To Embed #2 Child data is dependent/intrinsic to a parent { "id": "Order1", "customer": "Customer1", "orderDate": "2018-09-26", "itemsOrdered": [ {"ID": 1, "ItemName": "hamburger", "Price":9.50, "Qty": 1} {"ID": 2, "ItemName": "cheeseburger", "Price":9.50, "Qty": 499} ] } Items Ordered depends on Order
When To Embed #3 1:1 relationship { "id": "1", "name": "Alice", "email": "[email protected]", “phone": “555-5555" “loyaltyNumber": 13838359, "addresses": [ {"street": "1 Contoso Way", "city": "Seattle"}, {"street": "15 Fabrikam Lane", "city": "Orlando"} ] } All customers have email, phone, loyalty number for 1:1 relationship
When To Embed #4, #5 Similar rate of updates – does the data change at the same (slower) pace? - Minimize writes 1:few relationships { "id": "1", "name": "Alice", "email": "[email protected]", //Email, addresses don’t change too often "addresses": [ {"street": "1 Contoso Way", "city": "Seattle"}, {"street": "15 Fabrikam Lane", "city": "Orlando"} ] }
When To Embed - Summary Data from entities is queried together Child data is dependent on a parent 1:1 relationship Similar rate of updates – does the data change at the same pace 1:few – the set of values is bounded Usually embedding provides better read performance Follow-above to minimize trade-off for write perf
Modeling challenge #1: To embed or reference? Embed { "menuID": 1, "menuName": "Lunch menu", "items": [ {"ID": 1, "ItemName": "hamburger", "ItemDescription":.} {"ID": 2, "ItemName": "cheeseburger", "ItemDescription":.} ] } Reference { "menuID": 1, "menuName": "Lunch menu", "items": [ {"ID": 1} {"ID": 2} ] } {"ID": 1, "ItemName": “hamburger", "ItemDescription":.} {"ID": 2, "ItemName": “cheeseburger", "ItemDescription":.}
When To Reference #1 1 : many (unbounded relationship) Embedding doesn’t make sense: { - Too many writes to same "id": "1", "name": "Alice", document "email": "[email protected]", "Orders": [ - 2MB document limit { "id": "Order1", "orderDate": "2018-09-18", "itemsOrdered": [ {"ID": 1, "ItemName": "hamburger", "Price":9.50, "Qty": 1} {"ID": 2, "ItemName": "cheeseburger", "Price":9.50, "Qty": 499}] }, . { "id": "OrderNfinity", "orderDate": "2018-09-20", "itemsOrdered": [ {"ID": 1, "ItemName": "hamburger", "Price":9.50, "Qty": 1}] }] }
When To Reference #2 Data changes at different rates #2 { "id": "1", "name": "Alice", "email": "[email protected]", "stats":[ {"TotalNumberOrders": 100}, {"TotalAmountSpent": 550}] } Number of orders, amount spent will likely change faster than email Guidance: Store these aggregate data in own document, and reference it
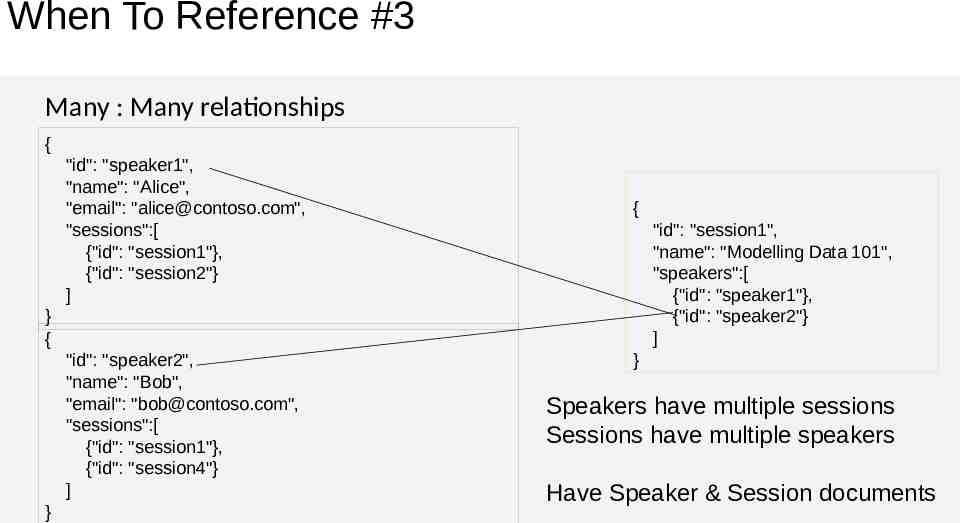
When To Reference #3 Many : Many relationships { "id": "speaker1", "name": "Alice", "email": "[email protected]", "sessions":[ {"id": "session1"}, {"id": "session2"} ] { "id": "session1", "name": "Modelling Data 101", "speakers":[ {"id": "speaker1"}, {"id": "speaker2"} ] } { "id": "speaker2", "name": "Bob", "email": "[email protected]", "sessions":[ {"id": "session1"}, {"id": "session4"} ] } } Speakers have multiple sessions Sessions have multiple speakers Have Speaker & Session documents
When To Reference #4 What is referenced, is heavily referenced by many others { "id": "speaker1", "name": "Alice", "email": "[email protected]", "sessions":[ {"id": "session1"}, {"id": "session2"} ] { "id": "session1", "name": "Modelling Data 101", "speakers":[ {"id": "speaker1"}, {"id": "speaker2"} ] } { "id": “attendee1", "name": “Eve", "email": “[email protected]", “bookmarkedSessions":[ {"id": "session1"}, {"id": "session4"} ] } } Here, session is referenced by speakers and attendees Allows you to update Session independently
When To Reference Summary 1 : many (unbounded relationship) many : many relationships Data changes at different rates What is referenced, is heavily referenced by many others Typically provides better write performance But may require more network calls for reads
But wait, you can do both! { "id": "speaker1", "name": "Alice", "email": "[email protected]", “address”: “1 Microsoft Way” “phone”: “555-5555” "sessions":[ {"id": "session1"}, {"id": "session2"} ] } Speaker { "id": “session1", "name": "Modelling Data 101", "speakers":[ {"id": "speaker1“, “name”: “Alice”, “email”: “[email protected]”}, {"id": "speaker2“, “name”: “Bob”} ] } Session Embed frequently used data, but use the reference to get less frequently used
Modelling Challenge #2: What entities go into a collection? Relational: One entity per table In Cosmos DB & NoSQL: Option 1: One entity per collection Option 2: Multiple entities per collection
Option 2: Multiple entities per collection “Feels” weird, but it can greatly improve performance! Makes sense when there are similar access patterns - If you need “join-like” capabilities, & data is not already embedded Approach: Introduce “type” property
Approach- Introduce Type Property Ability to query across multiple entity types with a single network request. For example, we have two types of documents: person and cat { { "id": "Ralph", "type": "Cat", "familyId": "Liu", "fur": { "length": "short", "color": "brown" } "id": "Andrew", "type": "Person", "familyId": "Liu", "worksOn": "Azure Cosmos DB" } }
Approach- Introduce Type Property Ability to query across multiple entity types with a single network request. For example, we have two types of documents: person and cat { { "id": "Ralph", "type": “Cat", "familyId": "Liu", "fur": { "length": "short", "color": "brown" } "id": "Andrew", "type": "Person", "familyId": "Liu", "worksOn": "Azure Cosmos DB" } } We can query both types of documents without needing a JOIN simply by running a query without a filter on type: SELECT * FROM c WHERE c.familyId "Liu"
Handle any data with no schema or indexing required Azure Cosmos DB’s schema-less service automatically indexes all your data, regardless of the data model, to delivery blazing fast queries. Automatic index management Synchronous auto-indexing GEEK No schemas or secondary indices needed Works across every data model Item Color Microwave safe Liquid capacity CPU Memory Storage Geek mug Graphite Yes 16ox ? ? ? Coffee Bean mug Tan No 12oz ? ? ? Surface book Gray ? ? 3.4 GHz Intel Skylake Core i76600U 16GB 1 TB SSD
Indexing Policies Custom Indexing Policies { "automatic": true, "indexingMode": "Consistent", "includedPaths": [{ "path": "/*", "indexes": [{ "kind": “Range", "dataType": "String", "precision": -1 }, { "kind": "Range", "dataType": "Number", "precision": -1 }, { "kind": "Spatial", "dataType": "Point" }] }], "excludedPaths": [{ "path": "/nonIndexedContent/*" }] Though all Azure Cosmos DB data is indexed by default, you can specify a custom indexing policy for your collections. Custom indexing policies allow you to design and customize the shape of your index while maintaining schema flexibility. Define trade-offs between storage, write and query performance, and query consistency Include or exclude documents and paths to and from the index Configure various index types }
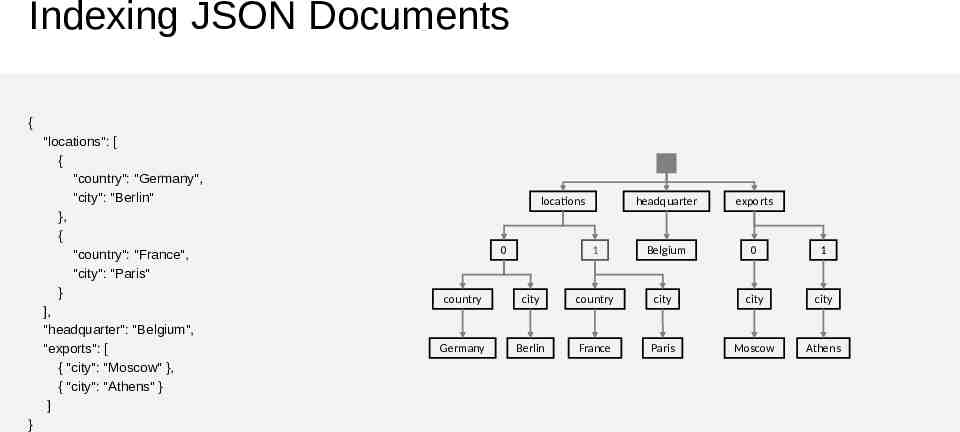
Indexing JSON Documents { "locations": [ { "country": "Germany", "city": "Berlin" }, { "country": "France", "city": "Paris" } ], "headquarter": "Belgium", "exports": [ { "city": "Moscow" }, { "city": "Athens" } ] } locations 0 1 headquarter exports Belgium 0 1 country city country city city city Germany Berlin France Paris Moscow Athens
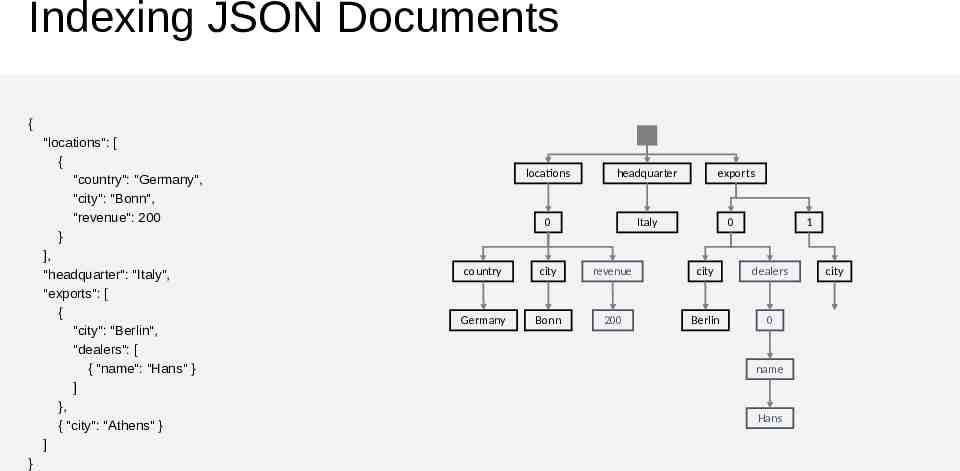
Indexing JSON Documents { "locations": [ { "country": "Germany", "city": "Bonn", "revenue": 200 } ], "headquarter": "Italy", "exports": [ { "city": "Berlin", "dealers": [ { "name": "Hans" } ] }, { "city": "Athens" } ] } locations headquarter 0 Italy exports 0 1 country city revenue city dealers Germany Bonn 200 Berlin 0 name Hans city
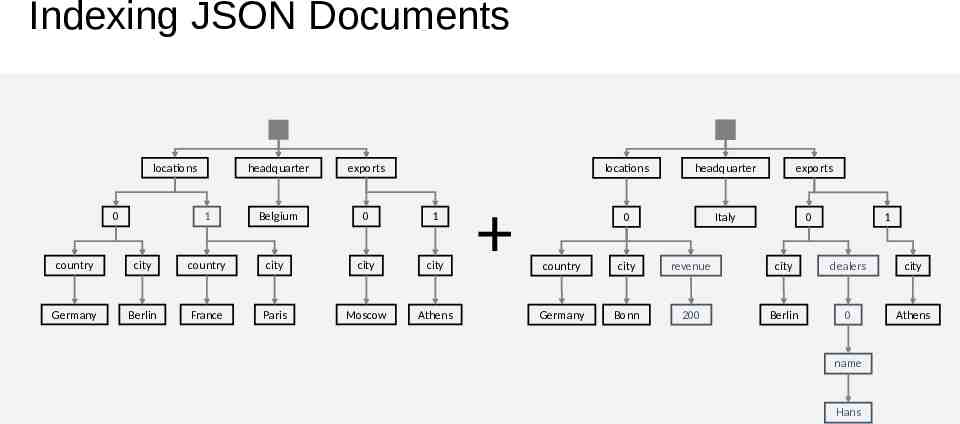
Indexing JSON Documents locations 0 1 headquarter exports Belgium 0 1 country city country city city city Germany Berlin France Paris Moscow Athens locations headquarter 0 Italy exports 0 1 country city revenue city dealers city Germany Bonn 200 Berlin 0 Athens name Hans
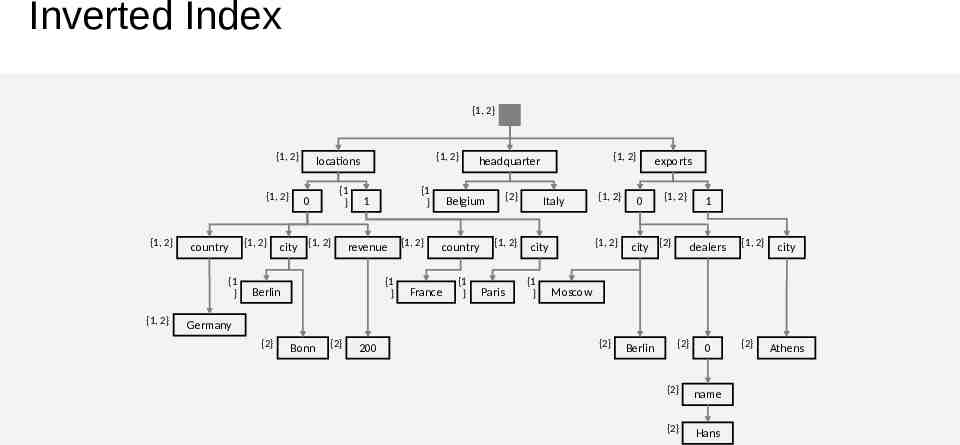
Inverted Index {1, 2} {1, 2} {1, 2} {1, 2} {1, 2} country {1 } {1, 2} {1, 2} locations {1 } 0 city {1, 2} {1 } 1 revenue {1 } Berlin {1, 2} {2} Belgium country France {1 } {1, 2} headquarter {1, 2} Paris Italy {1, 2} city {1 } {1, 2} exports 0 {1, 2} city {2} 1 dealers {1, 2} city Moscow Germany {2} Bonn {2} 200 {2} Berlin {2} 0 {2} name {2} Hans {2} Athens
{ "indexingMode": "consistent", "automatic": true, "includedPaths": [ { "path": "/age/?", "indexes": [ { "kind": "Range", "dataType": "Number", "precision": -1 }, ] }, { "path": "/gender/?", "indexes": [ { "kind": "Range", "dataType": "String", "precision": -1 }, ] } ], "excludedPaths": [ { "path": "/*" } ] Indexing Policy { "indexingMode": "none", "automatic": false, "includedPaths": [], "excludedPaths": [] } No indexing } Index some properties
Range Indexes These are created by default for each property and are needed for: Equality queries: SELECT * FROM container c WHERE c.property 'value’ Range queries: SELECT * FROM container c WHERE c.property 'value' (works for , , , , ! ) ORDER BY queries: SELECT * FROM container c ORDER BY c.property JOIN queries: SELECT child FROM container c JOIN child IN c.properties WHERE child 'value'
Spatial Indexes These must be added and are needed for geospatial queries: Geospatial distance queries: SELECT * FROM container c WHERE ST DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) 40 Geospatial within queries: SELECT * FROM container c WHERE ST WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] } })
Composite Indexes These must be added and are needed for queries that ORDER BY two or more properties. ORDER BY queries on multiple properties: SELECT * FROM container c ORDER BY c.firstName, c.lastName
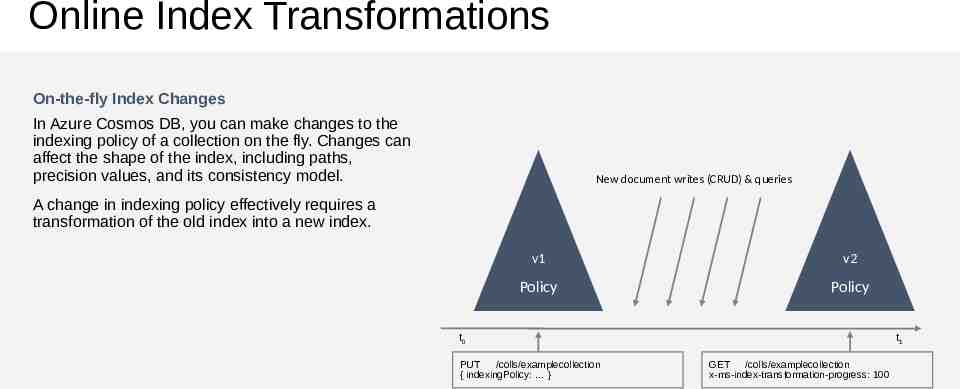
Online Index Transformations On-the-fly Index Changes In Azure Cosmos DB, you can make changes to the indexing policy of a collection on the fly. Changes can affect the shape of the index, including paths, precision values, and its consistency model. New document writes (CRUD) & queries A change in indexing policy effectively requires a transformation of the old index into a new index. v1 v2 Policy Policy t0 PUT /colls/examplecollection { indexingPolicy: } t1 GET /colls/examplecollection x-ms-index-transformation-progress: 100
Index Tuning Metrics Analysis The SQL APIs provide information about performance metrics, such as the index storage used and the throughput cost (request units) for every operation. You can use this information to compare various indexing policies, and for performance tuning. Update Index Policy View Headers Query Collection When running a HEAD or GET request against a collection resource, the x-ms-request-quota and the x-ms-request-usage headers provide the storage quota and usage of the collection. You can use this information to compare various indexing policies, and for performance tuning. Index Collection
Best Practices Understand query patterns – which properties are being used? Understand impact on write cost – index update RU cost scales with # properties






