CS 258 Parallel Computer Architecture Lecture 1 Introduction




































58 Slides5.21 MB
CS 258 Parallel Computer Architecture Lecture 1 Introduction to Parallel Architecture January 23, 2008 Prof John D. Kubiatowicz
Computer Architecture Is the attributes of a [computing] system as seen by the programmer, i.e., the conceptual structure and functional behavior, as distinct from the organization of the data flows and controls the logic design, and the physical implementation. Amdahl, Blaaw, and Brooks, 1964 SOFTWARE 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.2
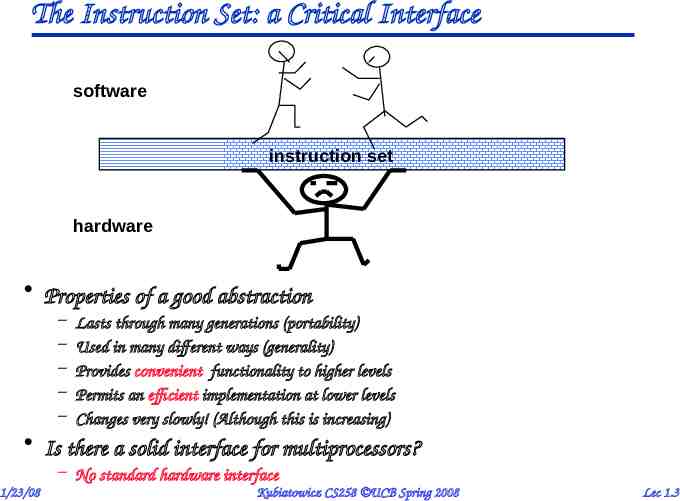
The Instruction Set: a Critical Interface software instruction set hardware Properties of a good abstraction – – – – – Lasts through many generations (portability) Used in many different ways (generality) Provides convenient functionality to higher levels Permits an efficient implementation at lower levels Changes very slowly! (Although this is increasing) Is there a solid interface for multiprocessors? – No standard hardware interface 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.3
What is Parallel Architecture? A parallel computer is a collection of processing elements that cooperate to solve large problems Some broad issues: – Models of computation: PRAM? BSP? Sequential Consistency? – Resource Allocation: » how large a collection? » how powerful are the elements? » how much memory? – Data access, Communication and Synchronization » how do the elements cooperate and communicate? » how are data transmitted between processors? » what are the abstractions and primitives for cooperation? – Performance and Scalability » how does it all translate into performance? » how does it scale? 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.4
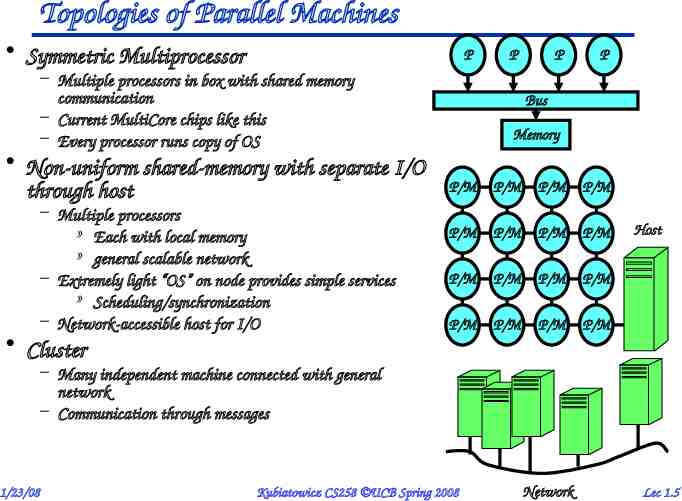
Topologies of Parallel Machines Symmetric Multiprocessor P – Multiple processors in box with shared memory communication – Current MultiCore chips like this – Every processor runs copy of OS Non-uniform shared-memory with separate I/O through host – Multiple processors » Each with local memory » general scalable network – Extremely light “OS” on node provides simple services » Scheduling/synchronization – Network-accessible host for I/O P P P Bus Memory P/M P/M P/M P/M P/M P/M P/M P/M P/M P/M P/M P/M P/M P/M P/M P/M Host Cluster – Many independent machine connected with general network – Communication through messages 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Network Lec 1.5
Conventional Wisdom (CW) in Computer Architecture 1. Old CW: Power is free, but transistors expensive New CW is the “Power wall”: Power is expensive, but transistors are “free” – Can put more transistors on a chip than have the power to turn on 2. Old CW: Only concern is dynamic power New CW: For desktops and servers, static power due to leakage is 40% of total power 3. Old CW: Monolithic uniprocessors are reliable internally, with errors occurring only at pins New CW: As chips drop below 65 nm feature sizes, they will have high soft and hard error rates 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.6
Conventional Wisdom (CW) in Computer Architecture 4. 6. Old CW: By building upon prior successes, continue raising level of abstraction and size of HW designs New CW: Wire delay, noise, cross coupling, reliability, clock jitter, design validation, stretch development time and cost of large designs at 65 nm Old CW: Researchers demonstrate new architectures by building chips New CW: Cost of 65 nm masks, cost of ECAD, and design time for GHz clocks Researchers no longer build believable chips Old CW: Performance improves latency & bandwidth New CW: BW improves (latency improvement)2 1/23/08 Kubiatowicz CS258 UCB Spring 2008 5. Lec 1.7
Conventional Wisdom (CW) in Computer Architecture 7. Old CW: Multiplies slow, but loads and stores fast New CW is the “Memory wall”: Loads and stores are slow, but multiplies fast – 200 clocks to DRAM, but even FP multiplies only 4 clocks 8. Old CW: We can reveal more ILP via compilers and architecture innovation – Branch prediction, OOO execution, speculation, VLIW, 9. 1/23/08 New CW is the “ILP wall”: Diminishing returns on finding more ILP Old CW: 2X CPU Performance every 18 months New CW is Power Wall Memory Wall ILP Wall Brick Wall Kubiatowicz CS258 UCB Spring 2008 Lec 1.8
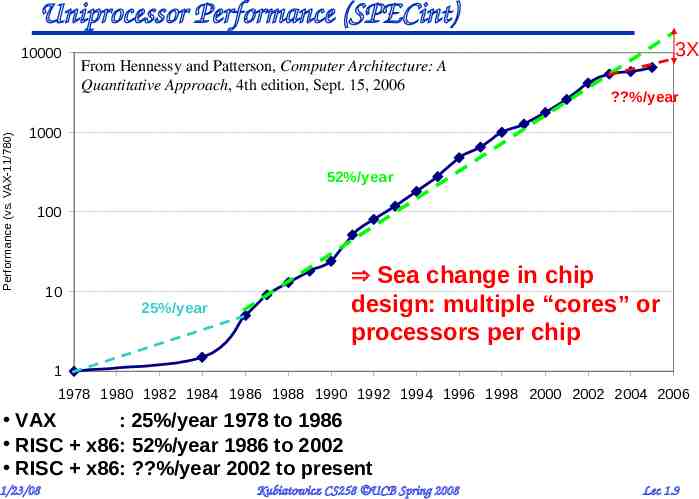
Uniprocessor Performance (SPECint) Performance (vs. VAX-11/780) 10000 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach, 4th edition, Sept. 15, 2006 3X ?%/year 1000 52%/year 100 10 25%/year Sea change in chip design: multiple “cores” or processors per chip 1 1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004 2006 VAX : 25%/year 1978 to 1986 RISC x86: 52%/year 1986 to 2002 RISC x86: ?%/year 2002 to present 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.9
Sea Change in Chip Design Intel 4004 (1971): 4-bit processor, 2312 transistors, 0.4 MHz, 10 micron PMOS, 11 mm2 chip RISC II (1983): 32-bit, 5 stage pipeline, 40,760 transistors, 3 MHz, 3 micron NMOS, 60 mm2 chip 125 mm2 chip, 0.065 micron CMOS 2312 RISC II FPU Icache Dcache – RISC II shrinks to 0.02 mm2 at 65 nm – Caches via DRAM or 1 transistor SRAM (www.t-ram.com) or 3D chip stacking – Proximity Communication via capacitive coupling at 1 TB/s ? Ivan Sutherland @ Sun / Berkeley) Processor is the new transistor? 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.10
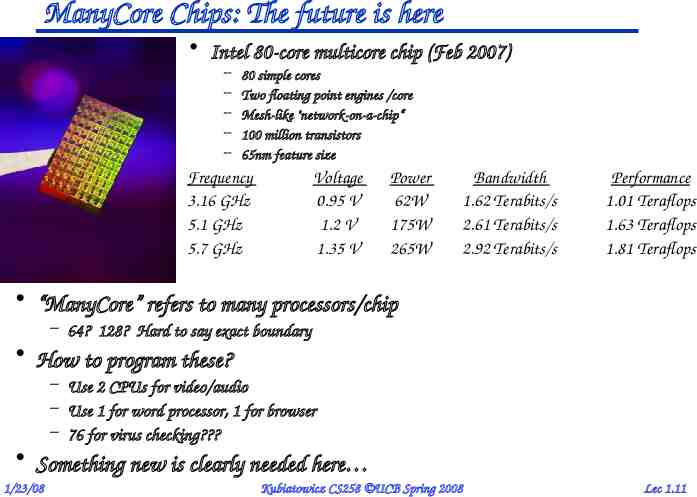
ManyCore Chips: The future is here Intel 80-core multicore chip (Feb 2007) – – – – – 80 simple cores Two floating point engines /core Mesh-like "network-on-a-chip“ 100 million transistors 65nm feature size Frequency 3.16 GHz 5.1 GHz 5.7 GHz Voltage 0.95 V 1.2 V 1.35 V Power 62W 175W 265W Bandwidth 1.62 Terabits/s 2.61 Terabits/s 2.92 Terabits/s Performance 1.01 Teraflops 1.63 Teraflops 1.81 Teraflops “ManyCore” refers to many processors/chip – 64? 128? Hard to say exact boundary How to program these? – Use 2 CPUs for video/audio – Use 1 for word processor, 1 for browser – 76 for virus checking? Something new is clearly needed here 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.11
Conventional Wisdom (CW) in Computer Architecture 10. Old CW: Increasing clock frequency is primary method of performance improvement New CW: Processors Parallelism is primary method of performance improvement 11. Old CW: Don’t bother parallelizing app, just wait and run on much faster sequential computer New CW: Very long wait for faster sequential CPU – – 2X uniprocessor performance takes 5 years? End of La-Z-Boy Programming Era 12. Old CW: Less than linear scaling failure New CW: Given the switch to parallel hardware, even sublinear speedups are beneficial 13 New Moore’s Law is 2X processors (“cores”) per chip every technology generation, but same clock rate – 1/23/08 “This shift toward increasing parallelism is not a triumphant stride forward based on breakthroughs ; instead, this is actually a retreat from even greater challenges that thwart efficient silicon implementation of traditional solutions.” The Parallel Computing Landscape: A Berkeley View, Dec 2006 Kubiatowicz CS258 UCB Spring 2008 Lec 1.12
Déjà vu all over again? Multiprocessors imminent in 1970s, ‘80s, ‘90s, “ today’s processors are nearing an impasse as technologies approach the speed of light.” David Mitchell, The Transputer: The Time Is Now (1989) Transputer was premature Custom multiprocessors strove to lead uniprocessors Procrastination rewarded: 2X seq. perf. / 1.5 years “We are dedicating all of our future product development to multicore designs. This is a sea change in computing” Paul Otellini, President, Intel (2004) Difference is all microprocessor companies switch to multiprocessors (AMD, Intel, IBM, Sun; all new Apples 2 CPUs) Procrastination penalized: 2X sequential perf. / 5 yrs Biggest programming challenge: 1 to 2 CPUs 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.13
CS258: Information Instructor: Prof John D. Kubiatowicz Office: 673 Soda Hall Phone: 643-6817 Email: [email protected] Office Hours: Wed 1:00 - 2:00 or by appt. Class: Mon, Wed 2:30-4:00pm 310 Soda Hall Web page: http://www.cs/ kubitron/courses/cs258-S08/ Lectures available online Noon day of lecture Email: [email protected] Clip signup link on web page (as soon as it is up) 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.14
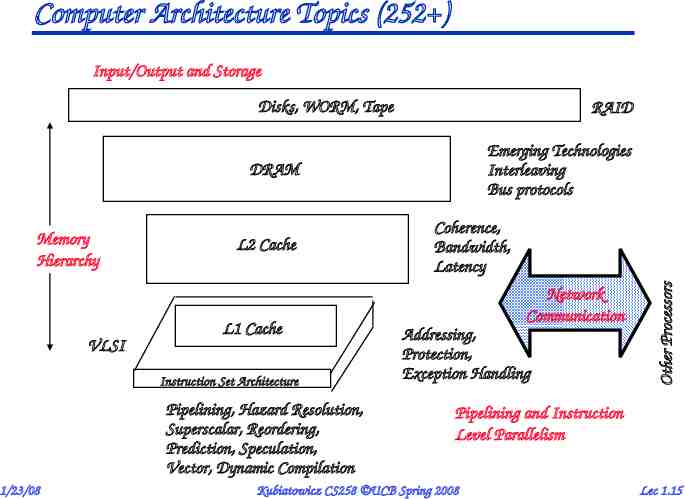
Computer Architecture Topics (252 ) Input/Output and Storage Disks, WORM, Tape RAID Emerging Technologies Interleaving Bus protocols DRAM VLSI L2 Cache L1 Cache Instruction Set Architecture Pipelining, Hazard Resolution, Superscalar, Reordering, Prediction, Speculation, Vector, Dynamic Compilation 1/23/08 Coherence, Bandwidth, Latency Network Communication Addressing, Protection, Exception Handling Other Processors Memory Hierarchy Pipelining and Instruction Level Parallelism Kubiatowicz CS258 UCB Spring 2008 Lec 1.15
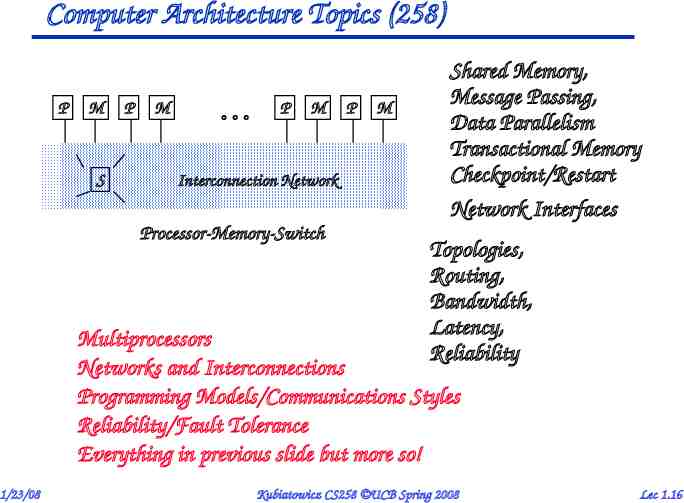
Computer Architecture Topics (258) P M S P M P M Interconnection Network Processor-Memory-Switch P M Shared Memory, Message Passing, Data Parallelism Transactional Memory Checkpoint/Restart Network Interfaces Topologies, Routing, Bandwidth, Latency, Reliability Multiprocessors Networks and Interconnections Programming Models/Communications Styles Reliability/Fault Tolerance Everything in previous slide but more so! 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.16
What will you get out of CS258? In-depth understanding of the design and engineering of modern parallel computers – technology forces – Programming models – fundamental architectural issues » naming, replication, communication, synchronization – basic design techniques » cache coherence, protocols, networks, pipelining, – methods of evaluation from moderate to very large scale across the hardware/software boundary Study of REAL parallel processors – Research papers, white papers Natural consequences? – Massive Parallelism Reconfigurable computing? – Message Passing Machines NOW Peer-to-peer systems? 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.17
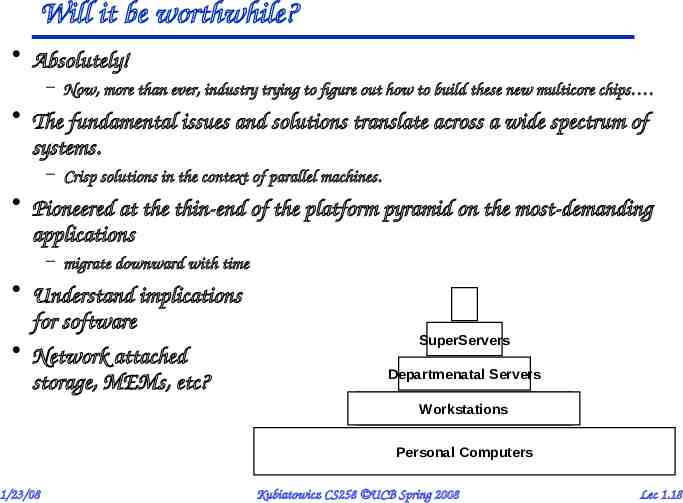
Will it be worthwhile? Absolutely! – Now, more than ever, industry trying to figure out how to build these new multicore chips . The fundamental issues and solutions translate across a wide spectrum of systems. – Crisp solutions in the context of parallel machines. Pioneered at the thin-end of the platform pyramid on the most-demanding applications – migrate downward with time Understand implications for software Network attached storage, MEMs, etc? SuperServers Departmenatal Servers Workstations Personal Computers 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.18
Why Study Parallel Architecture? Role of a computer architect: To design and engineer the various levels of a computer system to maximize performance and programmability within limits of technology and cost. Parallelism: Provides alternative to faster clock for performance Applies at all levels of system design Is a fascinating perspective from which to view architecture Is increasingly central in information processing How is instruction-level parallelism related to course-grained parallelism? 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.19
Is Parallel Computing Inevitable? This was certainly not clear just a few years ago YES! Today, however: Industry is desperate for solutions! Application demands: Our insatiable need for computing cycles Technology Trends: Easier to build Architecture Trends: Better abstractions Current trends: – Today’s microprocessors are multiprocessors and/or have multiprocessor support – Servers and workstations becoming MP: Sun, SGI, DEC, COMPAQ!. 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.20
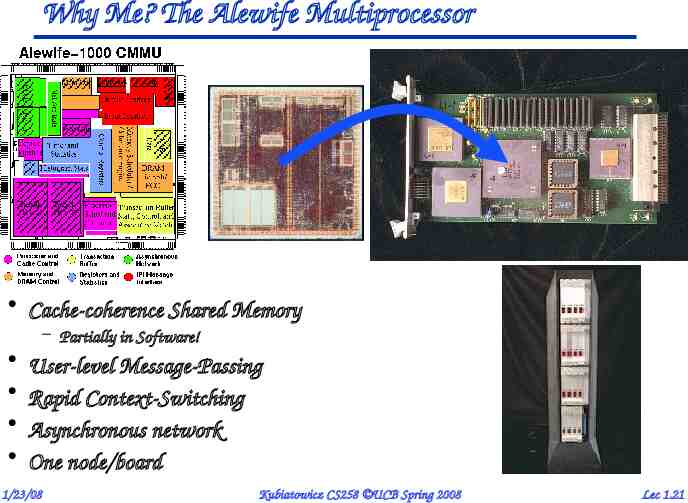
Why Me? The Alewife Multiprocessor Cache-coherence Shared Memory – Partially in Software! User-level Message-Passing Rapid Context-Switching Asynchronous network One node/board 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.21
Lecture style 1-Minute Review 20-Minute Lecture/Discussion 5- Minute Administrative Matters 25-Minute Lecture/Discussion 5-Minute Break (water, stretch) 25-Minute Lecture/Discussion Instructor will come to class early & stay after to answer questions Attention 20 min. 1/23/08 Break Time “In Conclusion, .” Kubiatowicz CS258 UCB Spring 2008 Lec 1.22
Course Methodology Study existing designs through research papers – – – – We will read about a number of real multiprocessors We will discuss network router designs We will discuss cache coherence protocols Etc High-level goal: – Understand past solutions so that – We can make proposals for ManyCore designs This is a critical point in parallel architecture design – Industry is really looking for suggestions – Perhaps you can make them listen to your ideas? 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.23
Research Paper Reading As graduate students, you are now researchers. Most information of importance to you will be in research papers. Ability to rapidly scan and understand research papers is key to your success. So: you will read lots of papers in this course! – Quick 1 paragraph summaries will be due in class – Students will take turns discussing papers Papers will be scanned and on web page. 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.24
TextBook: Two leaders in field Text: Parallel Computer Architecture: A Hardware/Software Approach, By: David Culler & Jaswinder Singh Covers a range of topics We will not necessarily cover them in order. 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.25
How will grading work? No TA This Term! Rough Breakdown: 20% Paper Summaries/Presentations 30% One Midterm 40% Research Project (work in pairs) – – – – – – meet 3 times with me to see progress give oral presentation give poster session written report like conference paper 6 weeks work full time for 2 people Opportunity to do “research in the small” to help make transition from good student to research colleague 10% Class Participation 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.26
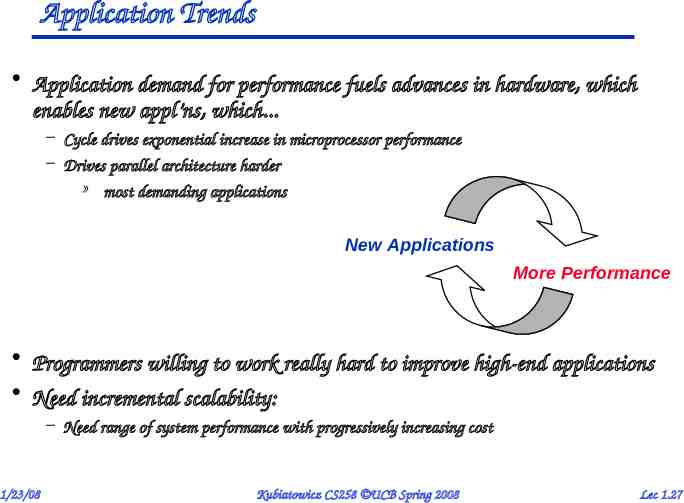
Application Trends Application demand for performance fuels advances in hardware, which enables new appl’ns, which. – Cycle drives exponential increase in microprocessor performance – Drives parallel architecture harder » most demanding applications New Applications More Performance Programmers willing to work really hard to improve high-end applications Need incremental scalability: – Need range of system performance with progressively increasing cost 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.27
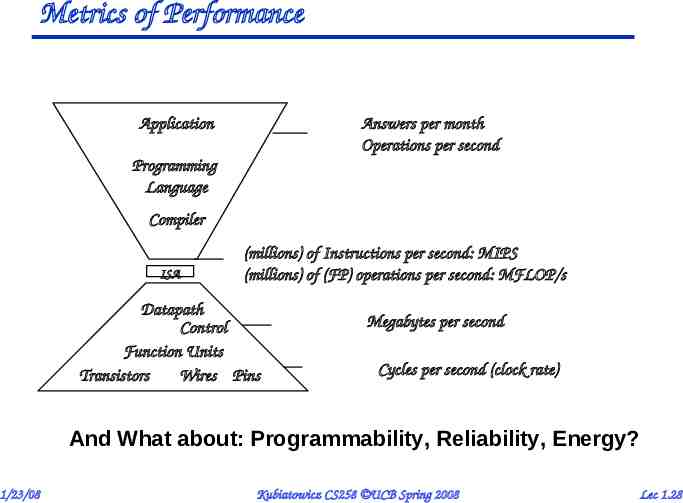
Metrics of Performance Application Answers per month Operations per second Programming Language Compiler ISA (millions) of Instructions per second: MIPS (millions) of (FP) operations per second: MFLOP/s Datapath Control Function Units Transistors Wires Pins Megabytes per second Cycles per second (clock rate) And What about: Programmability, Reliability, Energy? 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.28
Speedup Time (1 processor) Speedup (p processors) Time (p processors) Common mistake: – Compare parallel program on 1 processor to parallel program on p processors Wrong!: – Should compare uniprocessor program on 1 processor to parallel program on p processors Why? Keeps you honest – It is easy to parallelize overhead. 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.29
Amdahl's Law Speedup due to enhancement E: ExTime w/o E Speedup(E) Performance w/ ------------ExTime w/ E E ------------------Performance w/o E Suppose that enhancement E accelerates a fraction F of the task by a factor S, and the remainder of the task is unaffected 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.30
Amdahl’s Law for parallel programs? ExTime Speedup par ExTime ser 1 Fraction par Fractionp 1 1 Fraction parallel Fraction par ExTime par ExTime overhead ExTime p, overhead stuff p, stuff par p Best you could ever hope to do: Speedup maximum 1 1 - Fraction par Worse: Overhead may kill your performance! 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.31
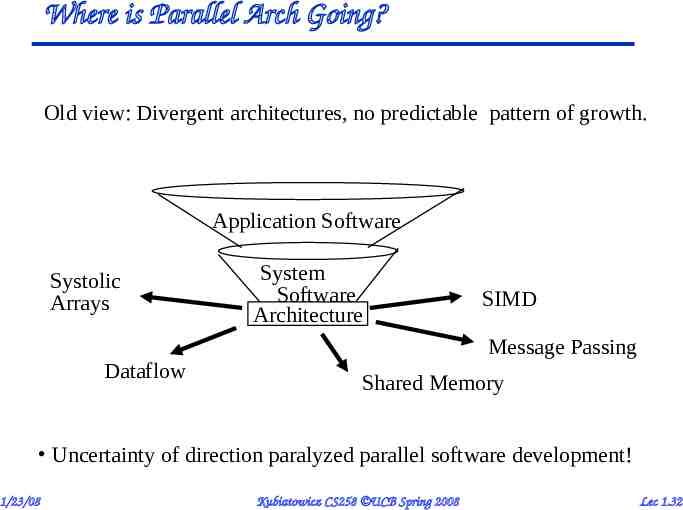
Where is Parallel Arch Going? Old view: Divergent architectures, no predictable pattern of growth. Application Software Systolic Arrays Dataflow System Software Architecture SIMD Message Passing Shared Memory Uncertainty of direction paralyzed parallel software development! 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.32
Today Extension of “computer architecture” to support communication and cooperation – Instruction Set Architecture plus Communication Architecture Defines – Critical abstractions, boundaries, and primitives (interfaces) – Organizational structures that implement interfaces (hw or sw) Compilers, libraries and OS are important bridges today Still – not enough standardization! – Nothing close to the stable x86 instruction set! 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.33
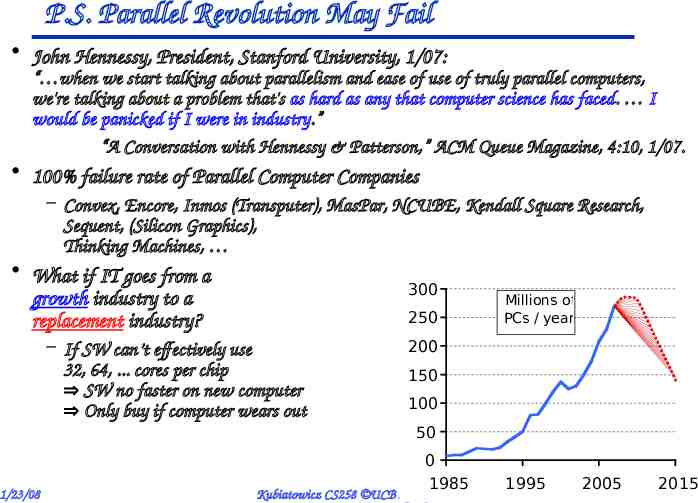
P.S. Parallel Revolution May Fail John Hennessy, President, Stanford University, 1/07: “ when we start talking about parallelism and ease of use of truly parallel computers, we're talking about a problem that's as hard as any that computer science has faced. I would be panicked if I were in industry.” “A Conversation with Hennessy & Patterson,” ACM Queue Magazine, 4:10, 1/07. 100% failure rate of Parallel Computer Companies – Convex, Encore, Inmos (Transputer), MasPar, NCUBE, Kendall Square Research, Sequent, (Silicon Graphics), Thinking Machines, What if IT goes from a growth industry to a replacement industry? 300 250 – If SW can’t effectively use 32, 64, . cores per chip SW no faster on new computer Only buy if computer wears out Millions of PCs / year 200 150 100 50 1/23/08 0 1985 Kubiatowicz CS258 UCB Spring 2008 1995 2005 2015 Lec 1.34
Can programmers handle parallelism? Historically: Humans not as good at parallel programming as they would like to think! – Need good model to think of machine – Architects pushed on instruction-level parallelism really hard, because it is “transparent” Can compiler extract parallelism? – Sometimes How do programmers manage parallelism? – Language to express parallelism? – How to schedule varying number of processors? Is communication Explicit (message-passing) or Implicit (shared memory)? – Are there any ordering constraints on communication? 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.35
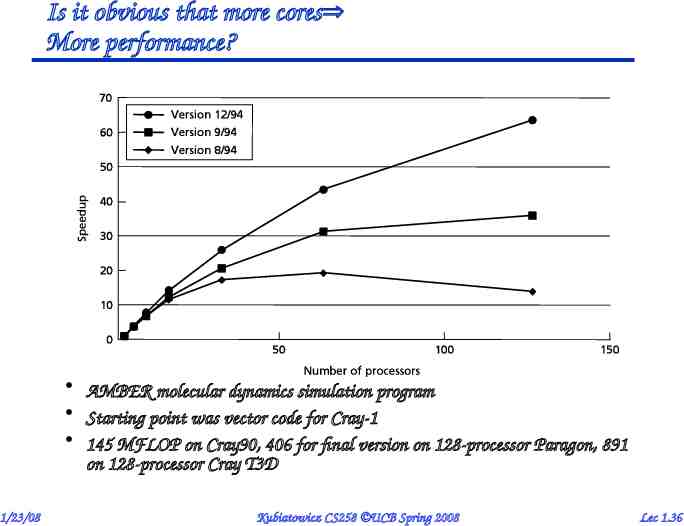
Is it obvious that more cores More performance? AMBER molecular dynamics simulation program Starting point was vector code for Cray-1 145 MFLOP on Cray90, 406 for final version on 128-processor Paragon, 891 on 128-processor Cray T3D 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.36
Granularity: Is communication fine or coarse grained? – Small messages vs big messages Is parallelism fine or coarse grained – Small tasks (frequent synchronization) vs big tasks If hardware handles fine-grained parallelism, then easier to get incremental scalability Fine-grained communication and parallelism harder than coarse-grained: – Harder to build with low overhead – Custom communication architectures often needed Ultimate course grained communication: – GIMPS (Great Internet Mercenne Prime Search) – Communication once a month 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.37
Current Commercial Computing targets Relies on parallelism for high end – Computational power determines scale of business that can be handled Databases, online-transaction processing, decision support, data mining, data warehousing . Google, Yahoo, . TPC benchmarks (TPC-C order entry, TPC-D decision support) – – – – 1/23/08 Explicit scaling criteria provided Size of enterprise scales with size of system Problem size not fixed as p increases. Throughput is performance measure (transactions per minute or tpm) Kubiatowicz CS258 UCB Spring 2008 Lec 1.38
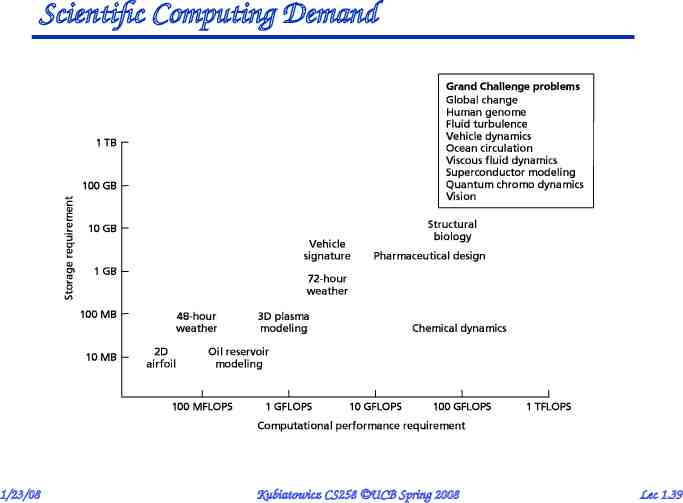
Scientific Computing Demand 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.39
Engineering Computing Demand Large parallel machines a mainstay in many industries – – – – – – Petroleum (reservoir analysis) Automotive (crash simulation, drag analysis, combustion efficiency), Aeronautics (airflow analysis, engine efficiency, structural mechanics, electromagnetism), Computer-aided design Pharmaceuticals (molecular modeling) Visualization » in all of the above » entertainment (films like Toy Story) » architecture (walk-throughs and rendering) – Financial modeling (yield and derivative analysis) – etc. 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.40
Can anyone afford high-end MPPs? ASCI (Accellerated Strategic Computing Initiative) ASCI White: Built by IBM – – – – 1/23/08 12.3 TeraOps, 8192 processors (RS/6000) 6TB of RAM, 160TB Disk 2 basketball courts in size Program it? Message passing Kubiatowicz CS258 UCB Spring 2008 Lec 1.41
Need New class of applications Handheld devices with ManyCore processors! – Great Potential, right? Human Interface applications very important: “The Laptop/handheld is the Computer” – ’07: HP number laptops desktops – 1B Cell phones/yr, increasing in function – Obtellini demoed “Universal Communicator” (Combination cell phone, PC, and Video Device) – Apple iPhone User wants Increasing Performance, Weeks or Months of Battery Power 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.42
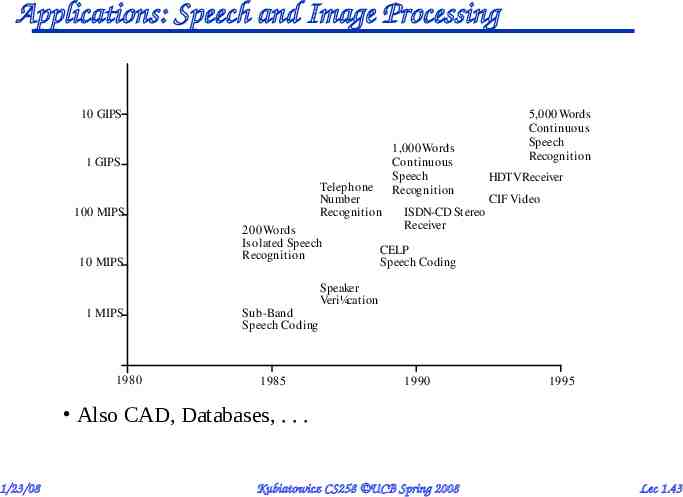
Applications: Speech and Image Processing 10 GIPS 1 GIPS Telephone Number Recognition 100 MIPS 10 MIPS 1 MIPS 1980 200 Words Isolated Speech Recognition Sub-Band Speech Coding 1985 1,000 Words Continuous Speech Recognition 5,000 Words Continuous Speech Recognition HDTV Receiver CIF Video ISDN-CD Stereo Receiver CELP Speech Coding Speaker Veri¼cation 1990 1995 Also CAD, Databases, . . . 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.43
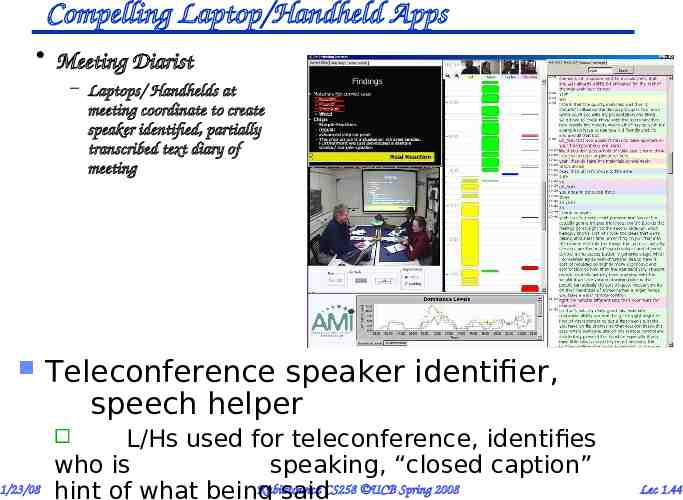
Compelling Laptop/Handheld Apps Meeting Diarist – Laptops/ Handhelds at meeting coordinate to create speaker identified, partially transcribed text diary of meeting Teleconference speaker identifier, speech helper L/Hs used for teleconference, identifies who is speaking, “closed caption” Kubiatowicz hint of what being saidCS258 UCB Spring 2008 1/23/08 Lec 1.44
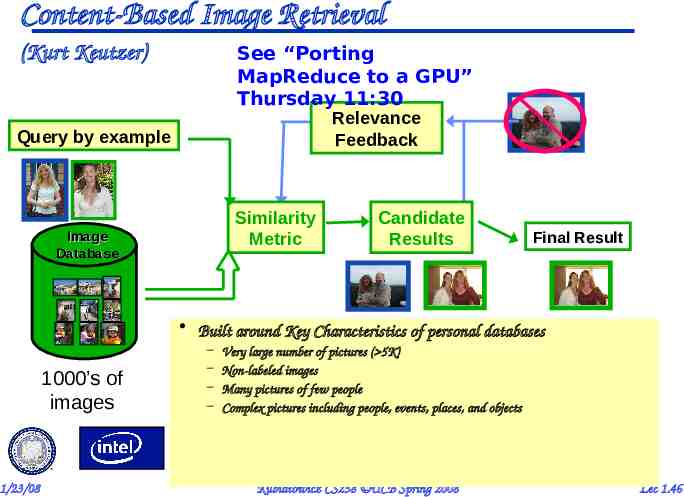
Compelling Laptop/Handheld Apps Health Coach – Since laptop/handheld always with you, Record images of all meals, weigh plate before and after, analyze calories consumed so far » “What if I order a pizza for my next meal? A salad?” – Since laptop/handheld always with you, record amount of exercise so far, show how body would look if maintain this exercise and diet pattern next 3 months » “What would I look like if I regularly ran less? Further?” Face Recognizer/Name Whisperer – Laptop/handheld scans faces, matches image database, whispers name in ear (relies on Content Based Image Retrieval) 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.45
Content-Based Image Retrieval See “Porting MapReduce to a GPU” Thursday 11:30 (Kurt Keutzer) Relevance Feedback Query by example Similarity Metric Image Database Candidate Results Final Result Built around Key Characteristics of personal databases 1000’s of images 1/23/08 – – – – Very large number of pictures ( 5K) Non-labeled images Many pictures of few people Complex pictures including people, events, places, and objects Kubiatowicz CS258 UCB Spring 2008 Lec 1.46
What About .? Many other applications might make sense If Only . – Parallel programming is already really hard – Who is going to write these apps? Domain Expert is not necessarily qualified to write complex parallel programs! 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.47
Need a Fresh Approach to Parallelism Berkeley researchers from many backgrounds meeting since Feb. 2005 to discuss parallelism – Krste Asanovic, Ras Bodik, Jim Demmel, Kurt Keutzer, John Kubiatowicz, Edward Lee, George Necula, Dave Patterson, Koushik Sen, John Shalf, John Wawrzynek, Kathy Yelick, – Circuit design, computer architecture, massively parallel computing, computer-aided design, embedded hardware and software, programming languages, compilers, scientific programming, and numerical analysis Tried to learn from successes in high performance computing (LBNL) and parallel embedded (BWRC) Led to “Berkeley View” Tech. Report and new Parallel Computing Laboratory (“Par Lab”) Goal: Productive, Efficient, Correct Programming of 100 cores & scale as double cores every 2 years (!) 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.48
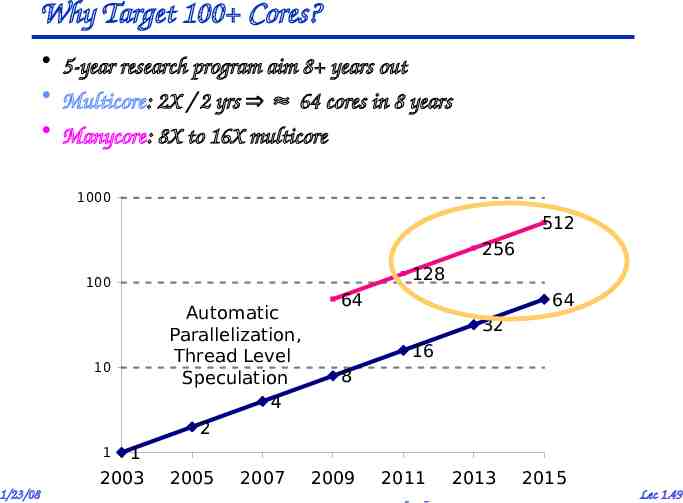
Why Target 100 Cores? 5-year research program aim 8 years out Multicore: 2X / 2 yrs 64 cores in 8 years Manycore: 8X to 16X multicore 1000 512 256 128 100 10 1 2003 Automatic Parallelization, Thread Level Speculation 4 2 64 64 32 16 8 1 1/23/08 2005 2007 2009 2011 2013 Kubiatowicz CS258 UCB Spring 2008 2015 Lec 1.49
4 Themes of View 2.0/ Par Lab 1. Applications 2. Compelling apps drive top-down research agenda Identify Common Computational Patterns 3. Breaking through disciplinary boundaries Developing Parallel Software with Productivity, Efficiency, and Correctness 4. 2 Layers Coordination & Composition Language Autotuning OS and Architecture 1/23/08 Composable primitives, not packaged solutions Deconstruction, Fast barrier synchronization, Partitions Kubiatowicz CS258 UCB Spring 2008 Lec 1.50
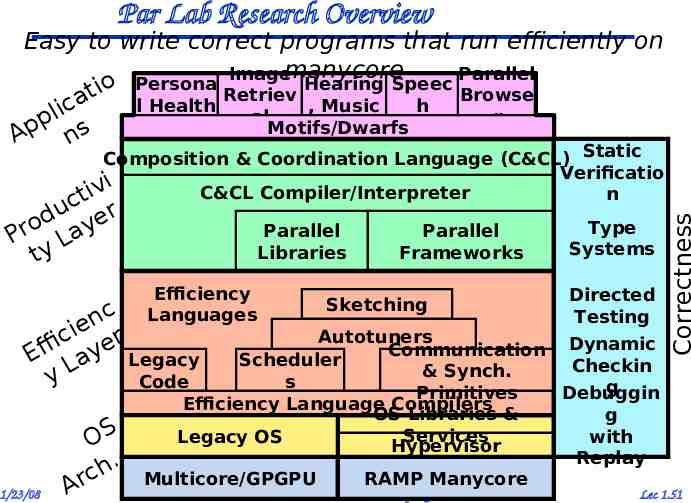
Par Lab Research Overview Easy to write correct programs that run efficiently on Imagemanycore Parallel Persona Hearing Speec o ti Retriev Browse a l Health , Music h c i l al r p Motifs/Dwarfs p A ns Static u c er d o Pr Lay ty Parallel Libraries Efficiency Languages c n ie r c Effi Laye Legacy y Code 1/23/08 OS . h c Ar Parallel Frameworks Sketching Type Systems Directed Testing Autotuners Communication Dynamic Scheduler Checkin & Synch. s g Primitives Debuggin Efficiency Language Compilers OS Libraries & g Services with Legacy OS Hypervisor Replay Multicore/GPGPU RAMP Manycore Kubiatowicz CS258 UCB Spring 2008 Correctness Composition & Coordination Language (C&CL) Verificatio i C&CL Compiler/Interpreter n tiv Lec 1.51
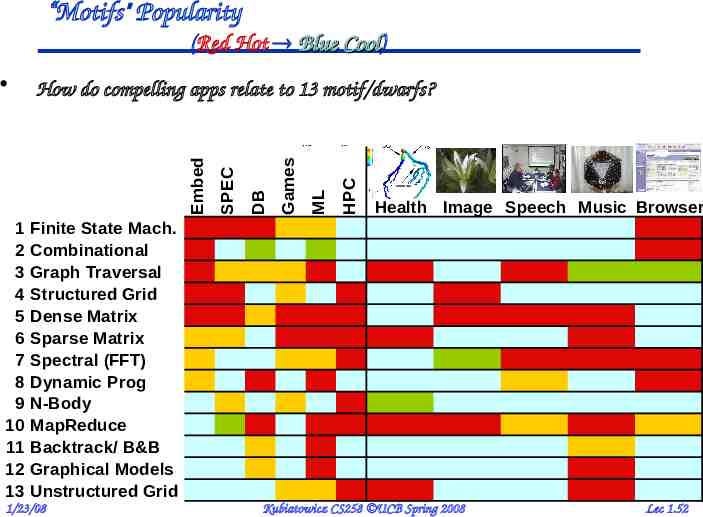
“Motifs" Popularity (Red Hot Blue Cool) Cool 1 2 3 4 5 6 7 8 9 10 11 12 13 HPC ML Games DB SPEC How do compelling apps relate to 13 motif/dwarfs? Embed Health Image Speech Music Browser Finite State Mach. Combinational Graph Traversal Structured Grid Dense Matrix Sparse Matrix Spectral (FFT) Dynamic Prog N-Body MapReduce Backtrack/ B&B Graphical Models Unstructured Grid 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.52
Developing Parallel Software 2 types of programmers 2 layers Efficiency Layer (10% of today’s programmers) – Expert programmers build Frameworks & Libraries, Hypervisors, – “Bare metal” efficiency possible at Efficiency Layer Productivity Layer (90% of today’s programmers) – Domain experts / Naïve programmers productively build parallel apps using frameworks & libraries – Frameworks & libraries composed to form app frameworks Effective composition techniques allows the efficiency programmers to be highly leveraged Create language for Composition and Coordination (C&C) 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.53
Architectural Trends Greatest trend in VLSI generation is increase in parallelism – Up to 1985: bit level parallelism: 4-bit - 8 bit - 16-bit » slows after 32 bit » adoption of 64-bit now under way, 128-bit far (not performance issue) » great inflection point when 32-bit micro and cache fit on a chip – Mid 80s to mid 90s: instruction level parallelism » pipelining and simple instruction sets, compiler advances (RISC) » on-chip caches and functional units superscalar execution » greater sophistication: out of order execution, speculation, prediction to deal with control transfer and latency problems – Next step: ManyCore. – Also: Thread level parallelism? Bit-level parallelism? 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.54
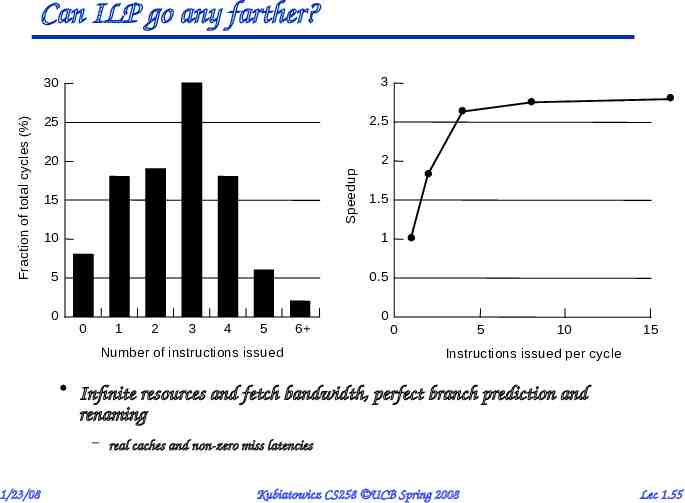
Can ILP go any farther? 3 25 2.5 20 2 Speedup Fraction of total cycles (%) 30 15 1.5 10 1 5 0.5 0 0 0 1 2 3 4 5 6 Number of instructions issued 0 5 10 15 Instructions issued per cycle Infinite resources and fetch bandwidth, perfect branch prediction and renaming – real caches and non-zero miss latencies 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.55
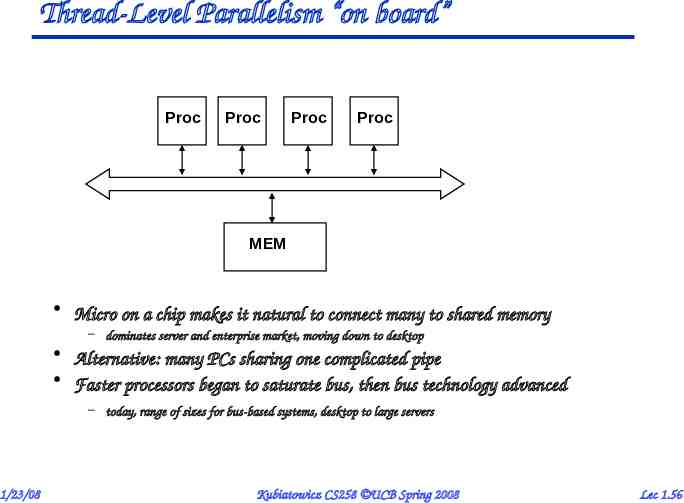
Thread-Level Parallelism “on board” Proc Proc Proc Proc MEM Micro on a chip makes it natural to connect many to shared memory – dominates server and enterprise market, moving down to desktop Alternative: many PCs sharing one complicated pipe Faster processors began to saturate bus, then bus technology advanced – today, range of sizes for bus-based systems, desktop to large servers 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.56
What about Storage Trends? Divergence between memory capacity and speed even more pronounced – Capacity increased by 1000x from 1980-95, speed only 2x – Gigabit DRAM by c. 2000, but gap with processor speed much greater Larger memories are slower, while processors get faster – Need to transfer more data in parallel – Need deeper cache hierarchies – How to organize caches? Parallelism increases effective size of each level of hierarchy, without increasing access time Parallelism and locality within memory systems too – New designs fetch many bits within memory chip; follow with fast pipelined transfer across narrower interface – Buffer caches most recently accessed data – Processor in memory? Disks too: Parallel disks plus caching 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.57
Summary: Why Parallel Architecture? Desperate situation for Hardware Manufacturers! – Economics, technology, architecture, application demand – Perhaps you can help this situation! Increasingly central and mainstream Parallelism exploited at many levels – Instruction-level parallelism – Multiprocessor servers – Large-scale multiprocessors (“MPPs”) Focus of this class: multiprocessor level of parallelism Same story from memory system perspective – Increase bandwidth, reduce average latency with many local memories Spectrum of parallel architectures make sense – Different cost, performance and scalability 1/23/08 Kubiatowicz CS258 UCB Spring 2008 Lec 1.58






