A Queueing Theoretic Approach for Performance Evaluation of

















25 Slides799.17 KB
A Queueing Theoretic Approach for Performance Evaluation of Low-Power Multi-core Embedded Systems Arslan Munir, Ann Gordon-Ross , and Sanjay Ranka* Department of Electrical and Computer Engineering *Department of Computer and Information Science and Engineering University of Florida, Gainesville, Florida, USA Also affiliated with NSF Center for HighPerformance Reconfigurable Computing This work was supported by the Natural Sciences and Engineering Research Council of Canada (NSERC) and the National Science Foundation (NSF) (CNS-0953447 and CNS-0905308) 1 of 25
Introduction and Motivation Embedded Systems Applications The word embedded literally means “within”, so embedded systems are information processing systems within (embedded into) other systems Automotive Space Medical Consumer Electronics 2 of 25
Introduction and Motivation Multi-core embedded systems – Moore’s law supplying billion of transistors on-chip – Increased computing demands from embedded system with constrained energy and power A 3G mobile handset’s signal processing requires 35-40 GOPS Constraints: power dissipation budget of 1W Performance efficiency required: 25 mW/GOP or 25 pJ/operation – Multi-core embedded systems provide a promising solution to meet these performance and power constraints Multi-core embedded systems architecture – Processor cores – Caches: L1-I, L1-D, last-level caches (LLCs) – Memory controllers – Interconnection network LLC configuration (private, shared, hybrid) can significantly impact an architecture’s performance and power consumption Focus of our work L2 or L3 Challenge: General consensus on private L1-I and L1-D caches but no dominant architectural paradigm for private, shared, or hybrid LLCs 3 of 25
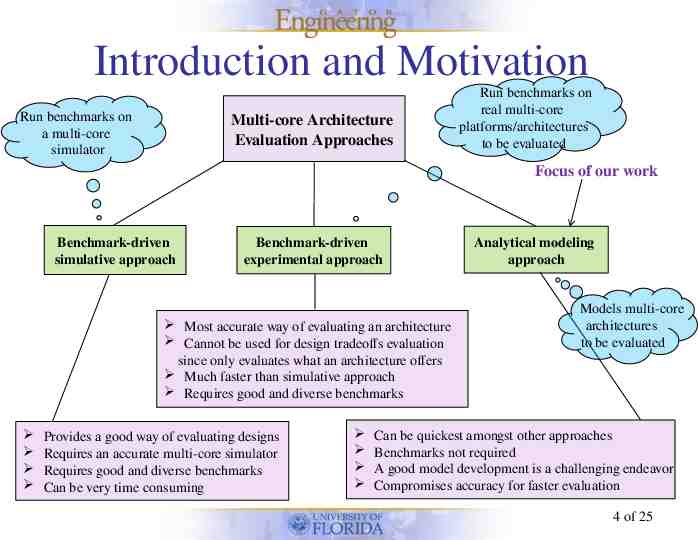
Introduction and Motivation Run benchmarks on a multi-core simulator Multi-core Architecture Evaluation Approaches Run benchmarks on real multi-core platforms/architectures to be evaluated Focus of our work Benchmark-driven simulative approach Benchmark-driven experimental approach Most accurate way of evaluating an architecture Cannot be used for design tradeoffs evaluation since only evaluates what an architecture offers Much faster than simulative approach Requires good and diverse benchmarks Provides a good way of evaluating designs Requires an accurate multi-core simulator Requires good and diverse benchmarks Can be very time consuming Analytical modeling approach Models multi-core architectures to be evaluated Can be quickest amongst other approaches Benchmarks not required A good model development is a challenging endeavor Compromises accuracy for faster evaluation 4 of 25
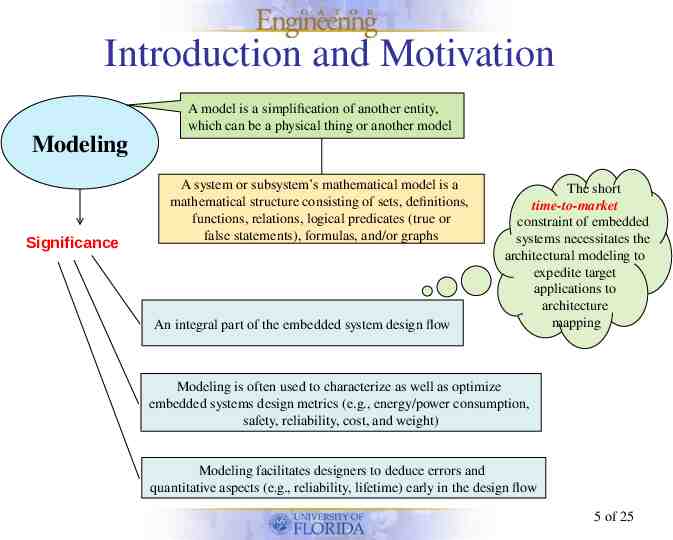
Introduction and Motivation A model is a simplification of another entity, which can be a physical thing or another model Modeling Significance A system or subsystem’s mathematical model is a mathematical structure consisting of sets, definitions, functions, relations, logical predicates (true or false statements), formulas, and/or graphs An integral part of the embedded system design flow The short time-to-market constraint of embedded systems necessitates the architectural modeling to expedite target applications to architecture mapping Modeling is often used to characterize as well as optimize embedded systems design metrics (e.g., energy/power consumption, safety, reliability, cost, and weight) Modeling facilitates designers to deduce errors and quantitative aspects (e.g., reliability, lifetime) early in the design flow 5 of 25
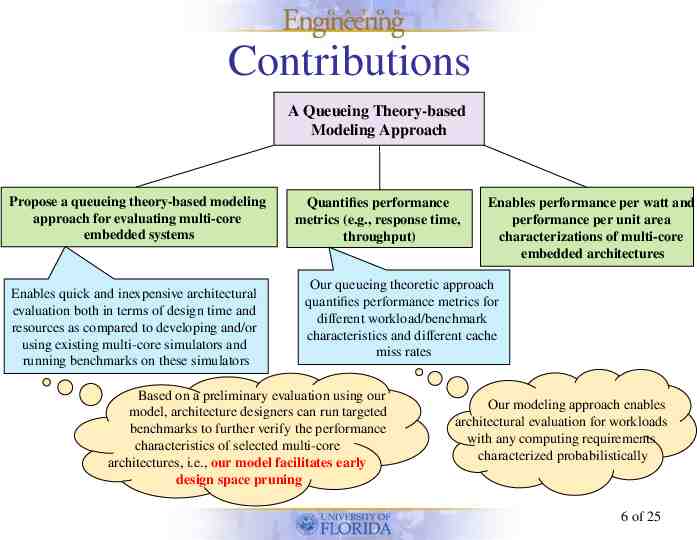
Contributions A Queueing Theory-based Modeling Approach Propose a queueing theory-based modeling approach for evaluating multi-core embedded systems Enables quick and inexpensive architectural evaluation both in terms of design time and resources as compared to developing and/or using existing multi-core simulators and running benchmarks on these simulators Quantifies performance metrics (e.g., response time, throughput) Enables performance per watt and performance per unit area characterizations of multi-core embedded architectures Our queueing theoretic approach quantifies performance metrics for different workload/benchmark characteristics and different cache miss rates Based on a preliminary evaluation using our model, architecture designers can run targeted benchmarks to further verify the performance characteristics of selected multi-core architectures, i.e., our model facilitates early design space pruning Our modeling approach enables architectural evaluation for workloads with any computing requirements characterized probabilistically 6 of 25
Related Work Queueing theory for performance analysis – Samari et al. [IEEE Trans. on Computers, 1980] used queueing theory for the analysis of distributed computer networks – Mainkar et al. [RELECTRONIC, 1991] used queueing theory-based models for performance evaluation of computer systems with a central processing unit (CPU) and disk drives – Our work differs from the previous work on queueing theory-based models for computer systems in that our work applies queuing theory for performance evaluation of multi-core embedded systems with different cache subsystems, which were not investigated before using queueing theory – Furthermore, our work introduces a novel way of representing workloads with different computing requirements probabilistically in a queueing theory-based model Evaluation and modeling of multi-core embedded architectures – Savage et al. [ACM IFMT, 2008] proposed a unified memory hierarchy model for multi-core architectures that captured varying degrees of cache sharing at different cache levels. The model, however, only worked for straight-line computations that could be represented by directed acyclic graphs (DAGs) 7 of 25
Related Work – Our queueing theoretic models can work for virtually any type of workload with any computing requirements – Fedorova et al. [Communications of the ACM, 2010] studied contention-aware task scheduling for multi-core architectures with shared resources (caches, memory controllers). The authores modeled the contention-aware task scheduler and investigated the scheduler’s impact on application performance for multi-core architectures – Our queuing theoretic models permit a wide range of scheduling disciplines based on workload requirements (e.g., first-come-first-served (FCFS), priority, round robin, etc.) Performance and energy evaluation for multi-core architectures – Kumar et al. [IEEE Computer, 2005] studied power, throughput, and response time metrics for heterogeneous chip multiprocessors (CMPs). The authors used a multi-core simulator for performance analysis, however, our queueing theoretic models can be used as a quick and inexpensive alternative for investigating performance aspects of heterogeneous CMPs 8 of 25
Related Work – Sabry et al. [IEEE/ACM GLSVLSI, 2010] investigated performance, energy, and area tradeoffs for private and shared L2 caches using a SystemC-based model. The model, however, required integration with other simulators such as MPARM to obtain performance results – Our queueing theoretic models do not require integration with other multi-core simulators to obtain performance results and serve as an independent comparative performance analysis approach for multi-core architecture evaluation – Benitez et al. [ACM EuroPar, 2007] proposed an adaptive L2 cache architecture that adapted to fit the code and data during runtime using partial cache array shut down. The proposed adaptive L2 cache resulted in energy savings. – Our work does not consider adaptive private caches but compares private, shared, and hybrid caches on an equal area basis to provide a fair comparison between different LLCs 9 of 25
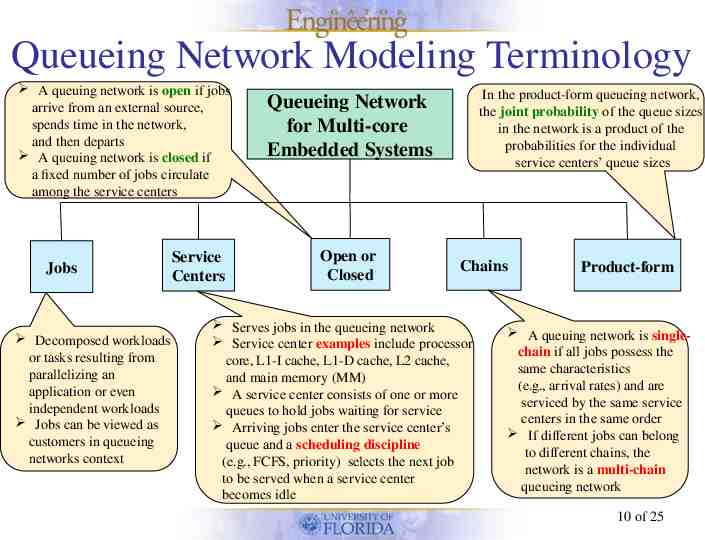
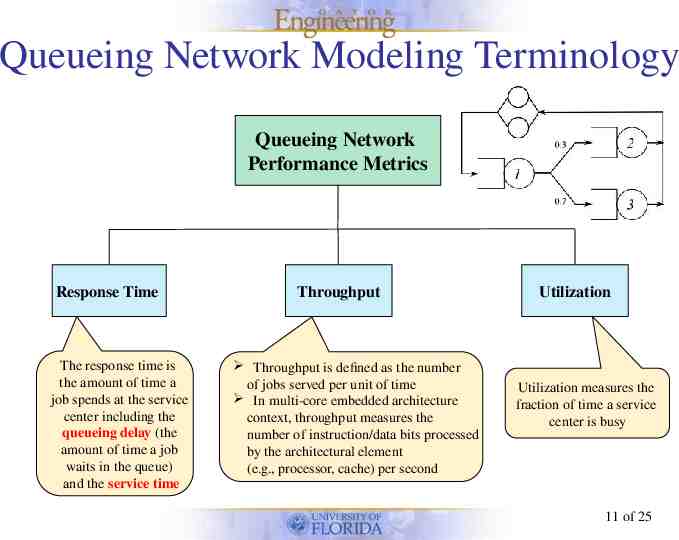
Queueing Network Modeling Terminology A queuing network is open if jobs arrive from an external source, spends time in the network, and then departs A queuing network is closed if a fixed number of jobs circulate among the service centers Jobs Decomposed workloads or tasks resulting from parallelizing an application or even independent workloads Jobs can be viewed as customers in queueing networks context Service Centers In the product-form queueing network, the joint probability of the queue sizes in the network is a product of the probabilities for the individual service centers’ queue sizes Queueing Network for Multi-core Embedded Systems Open or Closed Chains Serves jobs in the queueing network Service center examples include processor core, L1-I cache, L1-D cache, L2 cache, and main memory (MM) A service center consists of one or more queues to hold jobs waiting for service Arriving jobs enter the service center’s queue and a scheduling discipline (e.g., FCFS, priority) selects the next job to be served when a service center becomes idle Product-form A queuing network is singlechain if all jobs possess the same characteristics (e.g., arrival rates) and are serviced by the same service centers in the same order If different jobs can belong to different chains, the network is a multi-chain queueing network 10 of 25
Queueing Network Modeling Terminology Queueing Network Performance Metrics Response Time The response time is the amount of time a job spends at the service center including the queueing delay (the amount of time a job waits in the queue) and the service time Throughput Throughput is defined as the number of jobs served per unit of time In multi-core embedded architecture context, throughput measures the number of instruction/data bits processed by the architectural element (e.g., processor, cache) per second Utilization Utilization measures the fraction of time a service center is busy 11 of 25
Multi-core Embedded Architectures Studied Table: Multi-core embedded architectures with varying processor cores and cache configurations (P denotes a processor core, L1ID denotes L1-I and L1-D caches, M denotes main memory, and the integer constants preceding P, L1ID, L2, and M denote the number of these architectural components in the embedded architecture). Architecture 2P-2L1ID-2L2-1M 2P-2L1ID-1L2-1M 4P-4L1ID-4L2-1M 4P-4L1ID-1L2-1M 4P-4L1ID-2L2-1M Description Multi-core embedded architecture with 2 processor cores, private L1 I/D caches, private L2 caches, and a shared MM Multi-core embedded architecture with 2 processor cores, private L1 I/D caches, a shared L2 caches, and a shared MM Multi-core embedded architecture with 4 processor cores, private L1 I/D caches, private L2 caches, and a shared MM Multi-core embedded architecture with 4 processor cores, private L1 I/D caches, a shared L2 cache, and a shared MM Multi-core embedded architecture with 4 processor cores, private L1 I/D caches, 2 shared L2 caches, and a shared MM 12 of 25
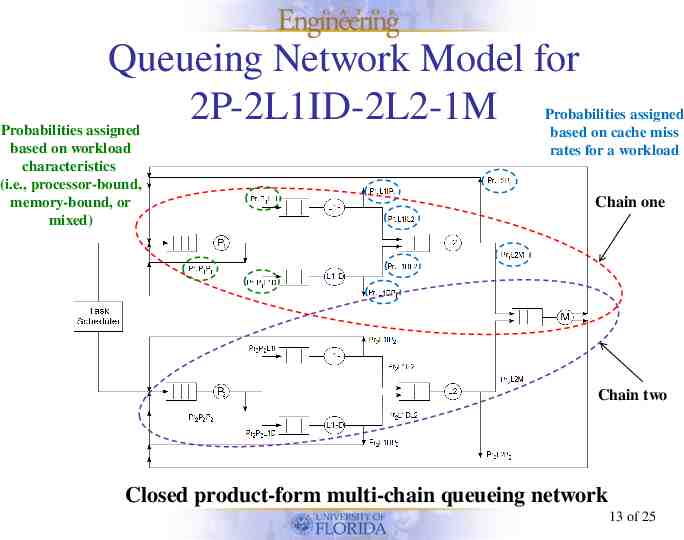
Queueing Network Model for 2P-2L1ID-2L2-1M Probabilities assigned based on workload characteristics (i.e., processor-bound, memory-bound, or mixed) Probabilities assigned based on cache miss rates for a workload Chain one Chain two Closed product-form multi-chain queueing network 13 of 25
Queueing Network Model for 2P-2L1ID-2L2-1M For a memory-bound workload – Processor-to-processor probability, Ppp 0.1 – Processor-to-memory probability, Ppm 0.9 – For cache Miss Rates L1-I 0.25, L1-D 0.5, L2 0.3 – QueueingPr1P1P1 network model probabilities for 2P-2L1ID-2L2-1M Pr1P1P1 0.1 Pr1P1L1I 0.45 Pr1P1L1D 0.45 Pr1L1IP1 0.75 Pr1L1DP1 0.5 Pr1L1IL2 0.25 Pr1L1DL2 0.5 Pr1L2P1 0.7 Pr1L2M 0.3 Pr1MP1 1 14 of 25
System-wide Performance Metrics Our queueing theoretic models determine performance metrics at component-level of architectural elements (e.g., processor cores, L1-I, L1-D, etc.) Our queuing theoretic models enable calculation of system-wide performance metrics – E.g., system-wide response time for a multi-core architecture can be given as: where – Np total number of processor cores in the multi-core embedded architecture – trx response time for architectural element x : x {Pi, L1-I, L1-D, L2, M} – PriX1X2 Probability of requests going from architectural element X1 to architectural element X2 for chain i where X1 {Pi, L1-I, L1-D, L2} and X2 {Pi, L1-I, L1-D, L2, M} 15 of 25
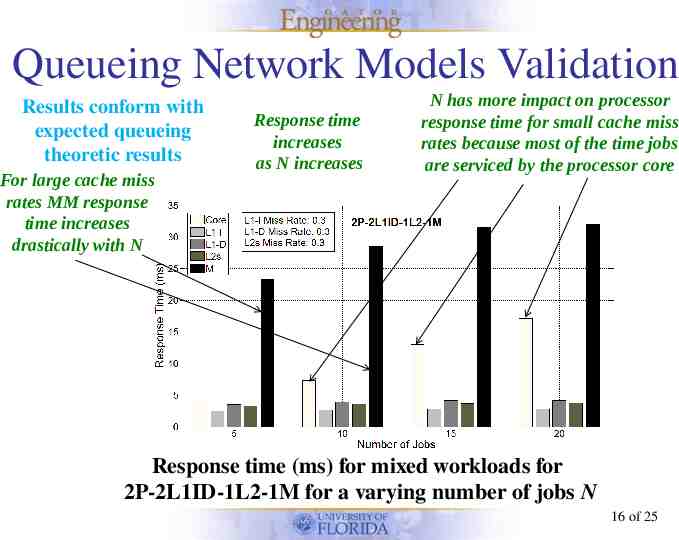
Queueing Network Models Validation Results conform with expected queueing theoretic results For large cache miss rates MM response time increases drastically with N Response time increases as N increases N has more impact on processor response time for small cache miss rates because most of the time jobs are serviced by the processor core Response time (ms) for mixed workloads for 2P-2L1ID-1L2-1M for a varying number of jobs N 16 of 25
Queueing Network Models Validation Execution time obtained from SESC and our queueing theoretic models for SPLASH2 benchmarks for multi-core architectures (QT denotes our queueing theoretic model) Results from SESC and our queueing theoretic models provide similar insights – The multi-core architectures with shared LLCs provide better performance than the architectures with private and hybrid LLCs for these benchmarks – Architectures with hybrid LLCs exhibit superior performance than the architectures with private LLCs Our queueing theoretic models provide relative performance measures for different architectures and benchmarks by simulating a minimum number of instructions representative of a benchmark, which explains the difference in execution time obtained from SESC and our queueing theoretic models for these benchmarks 17 of 25
Queueing Network Models Validation Execution time comparison of SPLASH-2 benchmarks on SESC versus our queueing theoretic models. Tyx-core denotes the execution time for simulating an x-core architecture using Y where Y {SESC, QT} (QT denotes our queueing theoretic model) Results verify that our queueing theoretic modeling approach provides a quick architectural evaluation as compared to running benchmarks on a multi-core simulator Our queueing theoretic modeling approach can provide architectural evaluation results 482,995x faster as compared to executing benchmarks on SESC 18 of 25
Experimental Setup We implement our queueing network models using SHARPE modeling tool Architectural Elements – Processor core: ARM7TDMI 32-bit processor core – Main memory (MM): 32 MB – Cache parameters: Cache Parameter Cache size Associativity Block/line size L1-I 8 KB Direct-mapped 64 B L1-D 8 KB 2-way 16 B L2 64 KB 2-way 64 B To provide a fair comparison between architectures, we ensure that the total L2 cache size for shared L2 cache architectures and private L2 cache architectures remain the same 19 of 25
Experimental Setup Service rates for architectural elements – Processor core 15 MIPS @ 16.8 MHz Cycle time 59.524 ns Service rate 480 Mbps (for 32-bit instructions) – L1-I Access latency 2 cycles Line size 64 B Transfer time for 64 B 64/4 16 cycles (for 32-bit/4 B bus) Total L1-I time access time transfer time 2 16 18 cycles Service rate (64 x 8) / (18 x 59.524 ns) 477.86 Mbps – L1-D Service rate 358.4 Mbps – L2 Service rate 330.83 Mbps – MM Service rate 74.15 Mbps 20 of 25
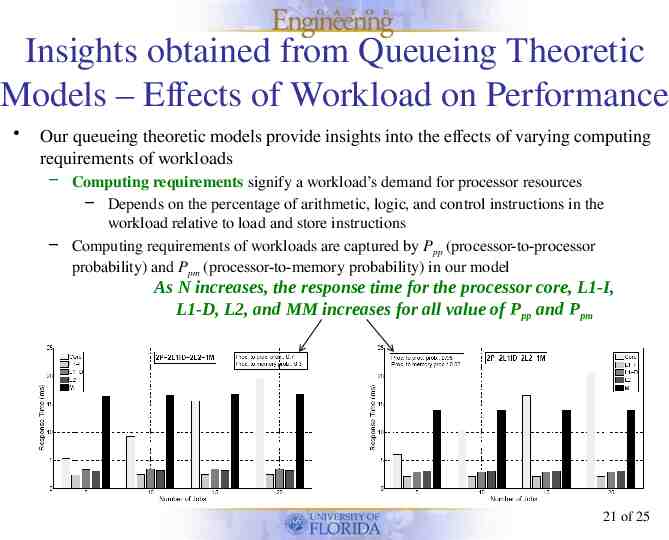
Insights obtained from Queueing Theoretic Models ‒ Effects of Workload on Performance Our queueing theoretic models provide insights into the effects of varying computing requirements of workloads – Computing requirements signify a workload’s demand for processor resources – Depends on the percentage of arithmetic, logic, and control instructions in the workload relative to load and store instructions – Computing requirements of workloads are captured by Ppp (processor-to-processor probability) and Ppm (processor-to-memory probability) in our model As N increases, the response time for the processor core, L1-I, L1-D, L2, and MM increases for all value of Ppp and Ppm 21 of 25
Insights obtained from Queueing Theoretic Models ‒ Effects of Workload on Performance As Ppp increases, the response time of the processor core increases whereas the response time of L1-I, L1-D, L2, and MM decreases slightly because of the processor-bound nature of the workload – E.g., processor response time increases by 19.8% as Ppp increases from 0.7 to 0.95 when N 5 – The response time of L1-I, L1-D, L2, and MM decreases by 10.8%, 14.2%, 2.2%, and 15.2%, respectively, as Ppp increases from 0.7 to 0.95 when N 5 2P-2L1ID-1L2-1M provides a 25% improvement in L2 response time and 12.3% improvement in MM response time over 2P-2L1ID-2L2-1M when Ppp 0.7 and N 5 4P-4L1ID-2L2-1M provides 22% improvement in L2 response time and 13% improvement in MM response time over 4P-4L1ID-4L2-1M when Ppp 0.7 and N 5 4P-4L1ID-1L2-1M provides 7.4% improvement in L2 response time with 5.2% degradation in MM response time over 4P-4L1ID-2L2-1M when Ppp 0.7 and N 5 Results reveal that shared LLCs provide more improvement in L2 response time as compared to hybrid and private LLCs Hybrid LLCs can provide better MM response time than shared LLCs and are more scalable than shared LLCs 22 of 25
Insights Obtained from Queueing Theoretic Models ‒ Performance per Watt Our queueing theoretic models enables performance per watt calculations for different multi-core embedded architectures The peak performance per watt for LLCs for two core architectures is attained when L1-1, L1-D, and L2 cache miss rates are equal to 0.3, Ppm 0.9, and N 20 – LLC’s peak performance per watt for 2P-2L1ID-2L2-1M 11.8 MFLOPS/W – LLC’s peak performance per watt for 2P-2L1ID-1L2-1M 14.3 MFLOPS/W The peak performance per watt for LLCs for four core architectures is attained when L1-1, L1-D, and L2 cache miss rates are equal to 0.2, Ppm 0.9, and N 20 – LLC’s peak performance per watt for 4P-4L1ID-4L2-1M 7.6 MFLOPS/W – LLC’s peak performance per watt for 4P-4L1ID-2L2-1M 9.2 MFLOPS/W – LLC’s peak performance per watt for 4P-4L1ID-1L2-1M 13.8 MFLOPS/W The comparison of peak performance per watt results for LLCs for two core and four core architectures indicate that architectures with different number of cores and private or shared caches deliver peak performance per watt for different types of workloads with different cache miss rate characteristics 23 of 25
Insights Obtained from Queueing Theoretic Models ‒ Performance per Unit Area Our queueing theoretic models enables performance per unit area calculations for different multi-core embedded architectures The peak performance per unit area for LLCs for two core architectures is attained when L1-1, L1-D, and L2 cache miss rates are equal to 0.3, Ppm 0.9, and N 20 – LLC’s peak performance per unit area for 2P-2L1ID-2L2-1M 6.27 MFLOPS/mm 2 – LLC’s peak performance per unit area for 2P-2L1ID-1L2-1M 7.14 MFLOPS/mm 2 The peak performance per unit area for LLCs for four core architectures is attained when L1-1, L1-D, and L2 cache miss rates are equal to 0.2, Ppm 0.9, and N 20 – LLC’s peak performance per watt for 4P-4L1ID-4L2-1M 4.04 MFLOPS/mm 2 – LLC’s peak performance per watt for 4P-4L1ID-2L2-1M 4.6 MFLOPS/mm 2 – LLC’s peak performance per watt for 4P-4L1ID-1L2-1M 5.2 MFLOPS/mm 2 The comparison of peak performance per unit area results reveal that architectures with shared LLCs provide the highest LLC performance per unit area followed by architectures with hybrid LLCs and private LLCs 24 of 25
Conclusions We developed closed product-form queueing network models for performance evaluation of multi-core embedded architectures The performance evaluation results indicate that the architectures with shared LLCs provide better LLCs performance and performance per watt than the architectures with private LLCs Results revealed that architectures with shared LLCs are more likely to cause main memory response time bottleneck for large cache miss rates as compared to private LLCs Main memory response time bottleneck created by shared LLCs can be mitigated by using hybrid LLCs (i.e., sharing LLCs by a fewer number of cores) though hybrid LLCs consume more power than shared LLCs and deliver comparatively less MFLOPS/W The performance per watt and performance per unit area results revealed that the multi-core embedded architectures with shared LLCs become more area and power efficient as the number of processor cores in the architecture increases The simulation results for the SPLASH-2 benchmarks executing on the SESC simulator verified the architectural evaluation insights obtained from our queueing theoretic models 25 of 25






