Building an open source data lake at scale in the cloud Adrian























24 Slides3.87 MB
Building an open source data lake at scale in the cloud Adrian Woodhead, Principal Engineer 1
Agenda Background Data Lake foundation: data metadata High Availability and Disaster Recovery Data federation Event-based data processing Expedia Group Proprietary and Confidential 2 2
3
Data Lake journey “traditional” RDBMS Data Warehouse Introduced on-premise Hadoop Hive cluster RDBMS SQL replaced by SQL from Hive Slow at busy times Painful upgrade path (software and hardware) Migration to “Cloud” as primary data lake Expedia Group Proprietary and Confidential 4
C l ou d D a t a L a ke Fou n d a t i on 1 2 Expedia Group Proprietary and Confidential 5
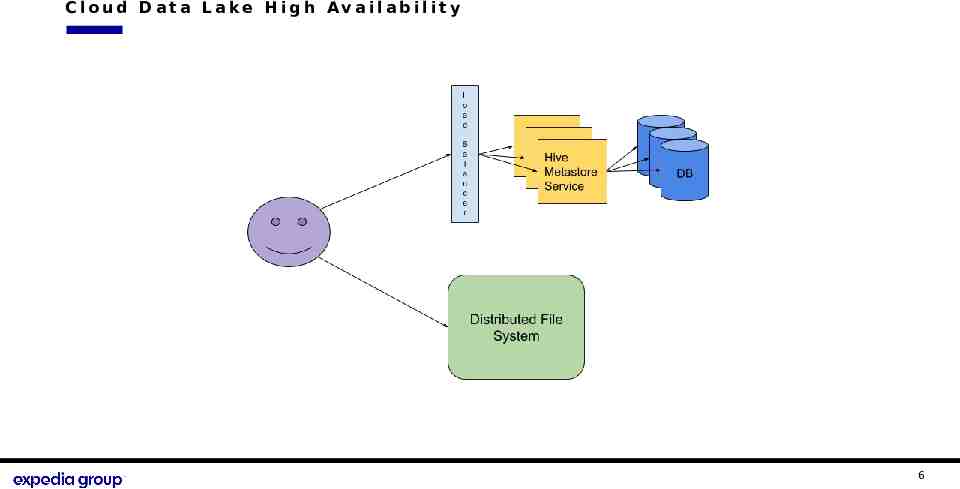
C loud Data Lake High Av aila bilit y 1 2 Expedia Group Proprietary and Confidential 6
Cloud Data Lake Redundancy 1 2 Expedia Group Proprietary and Confidential 7
Redundancy by replication Data and Metadata Co-ordinated Data consistency during replication 1 No partial reads Completeness more important than latency 2 Expedia Group Proprietary and Confidential 8 8
Circus Train – Hive dataset replicator https://github.com/HotelsDotCom/circus-train/ Metadata only available after data Supports HDFS, S3, GCS etc. Standard “distcp” and optimised copiers 1 Plugin architecture – Notifications, Copiers, Metadata transformations Selective data replication – custom filters, “Hive Diff” 2 https://github.com/HotelsDotCom/shunting-yard Event-driven Circus Train Expedia Group Proprietary and Confidential 9 9
Data Lake Silos 1 2 Expedia Group Proprietary and Confidential 10
Data Lake Silo Solutions Move back to a single data lake Scalability issues Increased “blast radius” Replicate shared data sets between data lakes 1 Cost of maintaining replication jobs Increased file storage costs Increased network transfer costs 2 Expedia Group Proprietary and Confidential 11 11
Federated Cloud Data Lake https://github.com/HotelsDotCom/waggle-dance/ Waggle Dance – a Hive Thrift metastore proxy Configure it with “downstream” Hive metastores 1 Configure S3 bucket access permissions Set “hive.metastore.uris” to Waggle Dance server Use as you would Hive metastore in any client app 2 Expedia Group Proprietary and Confidential 12 12
Waggl e Dance Ove rview 1 2 Expedia Group Proprietary and Confidential 13
Mu l t i - Re g i on Fe d e r a t e d C l ou d Da t a La ke US EAST 1 Replicate US WEST 2 Replicate Federate Expedia Group Proprietary and Confidential US WEST 2 US EAST 1 14
Federated Cloud Data Lake Best Practices Expose read-only endpoints to “external” users Separate critical path infrastructure Federate data for access within a region Replicate data1 for access in a different region 2 Expedia Group Proprietary and Confidential 15 15
Federated Cloud Data Lake Alternative Presto – distributed SQL query engine for big data Federate Hive, MySQL, PostgreSQL and many others 1 https://github.com/prestodb/presto OR https://github.com/prestosql/presto 2 ? Expedia Group Proprietary and Confidential 16 16
Apiary - Cloud Data Lake Components https://github.com/ExpediaGroup/apiary Various components for a federated cloud data lake Docker images for all services 1 Terraform deployment scripts Ranger for authorization Various optional extensions 2 Expedia Group Proprietary and Confidential 17 17
Apiary – Metadata Events https://github.com/ExpediaGroup/apiary-extensions/tree/ master/apiary-metastore-events Events for tables/partitions CRUD operations Hive MetaStoreEventListener implementations 1 Kafka AWS SNS Enable downstream data processing use cases 2 ETL, Governance, Lineage etc Expedia Group Proprietary and Confidential 18 18
Problem – rewriting data at scale Changes to existing data Read isolation for long running queries Always create new folders for updates 1 Repoint Hive data locations How to expire “orphaned data”? 2 Expedia Group Proprietary and Confidential 19 19
Beekeeper – orphaned data cleanup https://github.com/ExpediaGroup/beekeeper/ Hive table parameter: beekeeper.remove.unreferenced.data true Apiary event listener 1 Detects data re-writes Schedules old data for deletion in future 2 Periodically performs the data deletions Expedia Group Proprietary and Confidential 20 20
Consistent CRUD alternatives http://hive.apache.org/ - Hive 3.1.x with ACID https://iceberg.incubator.apache.org/ - Iceberg https://delta.io/ - Delta Lake 1 https://hudi.apache.org/ - Hudi 2 Expedia Group Proprietary and Confidential 21 21
Don’t forget to test https://github.com/klarna/HiveRunner/ - Hive SQL unit tests https://github.com/HotelsDotCom/mutant-swarm/ - Code coverage for HiveRunner 1 https://github.com/HotelsDotCom/beeju - Unit tests for Thrift Hive metastore service and HiveServer2 2 Expedia Group Proprietary and Confidential 22 22
Where to next? Hybrid cloud best of both worlds but increased complexity Multi-cloud best of breed but increased complexity Docker Kubernetes Reduce vendor lock-in Massive scale without too much effort Minimal changes for on-prem/EKS/GKE/AKS etc Expedia Group Proprietary and Confidential 23
Open Source Data Lake Components Hive Replication https://github.com/HotelsDotCom/circus-train https://github.com/ExpediaGroup/shunting-yard Hive Federation https://github.com/HotelsDotCom/waggle-dance Hive Cleanup https://github.com/ExpediaGroup/beekeeper Cloud Data Lake https://github.com/ExpediaGroup/apiary Expedia Group Proprietary and Confidential 24






