Data Stream Mining Excerpts from Wei Fan et al.’s PAKDD Tutorial Notes





















30 Slides2.77 MB
Data Stream Mining Excerpts from Wei Fan et al.’s PAKDD Tutorial Notes
Tutorial: Data Stream Mining Challenges and Techniques Latifur Khan1, Wei Fan2 , Jiawei Han3, Jing Gao3, Mohammad M Masud1 Department of Computer Science, University of Texas at Dallas 2 IBM T.J. Watson Research , USA 3 Department of Computer Science, University of Illinois at Urbana Champaign 1
Outline of the tutorial IIntroduction Data Stream Classification Clustering Novel Class Detection Khan et al. May 24, 2011
Introduction Characteristics of Data streams are: Continuous flow of data Examples: Network traffic Sensor data Call center records
Challenges Infinite length Concept-drift Concept-evolution Feature Evolution
Infinite Length Impractical to store and use all historical data – Requires infinite storage – And running time
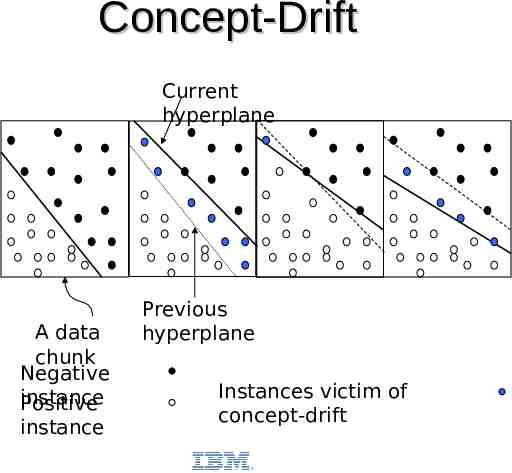
Concept-Drift Current hyperplane A data chunk Negative instance Positive instance Previous hyperplane Instances victim of concept-drift
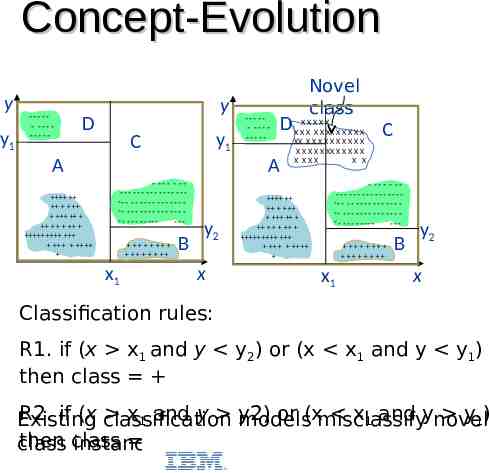
Concept-Evolution y y1 ----- -------- y D y1 C A ----- -------- A - --- - ------------------ - - - - - - - - - - - - - -- - - - - - - - - - - - - - - - - - - - - -- -- x1 B y2 x D Novel class XXXXX X X X X X XX X X X X X XX X X X X X X X X X X X X X X X XX X X X X X X XXX X X C - --- - ------------------ - - - - - - - - - - - - - -- - - - - - - - - - - - - - - - - - - - - -- -- x1 B y2 x Classification rules: R1. if (x x1 and y y2) or (x x1 and y y1) then class R2. if (x classification x1 and y y2) or (xmisclassify x1 and ynovel y1) Existing models then class class instances
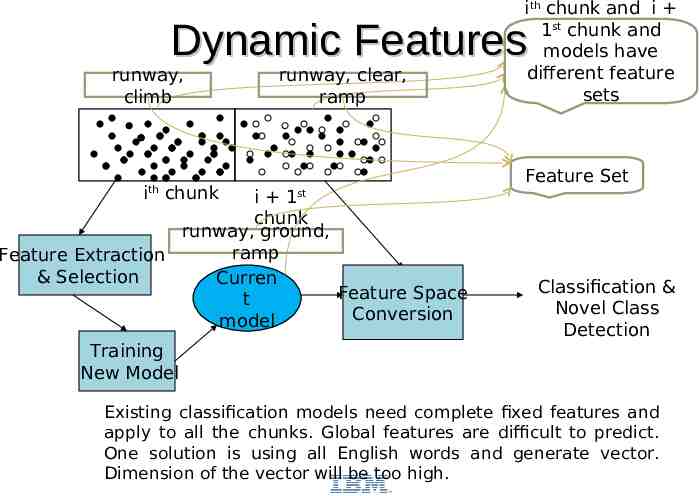
Dynamic Features Why new features evolving – Infinite data stream Normally, global feature set is unknown New features may appear – Concept drift As concept drifting, new features may appear – Concept evolution New type of class normally holds new set of features Different chunks may have different feature sets
ith chunk and i 1st chunk and models have different feature sets Dynamic Features runway, climb i chunk th runway, clear, ramp i 1st chunk runway, ground, ramp Feature Extraction & Selection Curren Feature Space t Conversion model Feature Set Classification & Novel Class Detection Training New Model Existing classification models need complete fixed features and apply to all the chunks. Global features are difficult to predict. One solution is using all English words and generate vector. Dimension of the vector will be too high.
Outline of the tutorial Introduction IData Stream Classification Clustering Novel Class Detection Khan et al. May 24, 2011
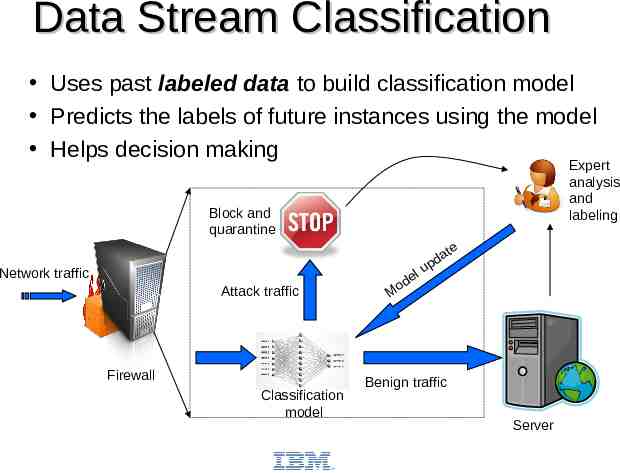
Data Stream Classification Uses past labeled data to build classification model Predicts the labels of future instances using the model Helps decision making Expert analysis and labeling Block and quarantine Network traffic Attack traffic Firewall Classification model d Mo e a pd u l te Benign traffic Server
Data Stream Classification (cont.) What are the applications? – Security Monitoring – Network monitoring and traffic engineering. – Business : credit card transaction flows. – Telecommunication calling records. – Web logs and web page click streams. – Financial market: stock exchange. Khan et al. May 24, 2011
DataStream Classification (cont.) I Single Model Incremental Classification Ensemble – model based classification – Supervised – Semi-supervised – Active learning Khan et al. May 24, 2011
Single Model Incremental Classification Introduction Problems in mining Data Stream Decision Tree Very Fast Decision Tree (VFDT) CVFDT Khan et al. May 24, 2011
Problems in Mining Data Streams Traditional data mining techniques usually require entire data set to be present. Random access (or multiple access) to the data. Impractical to store the whole data. Simple calculation per data due to time and space constraints. Khan et al. May 24, 2011
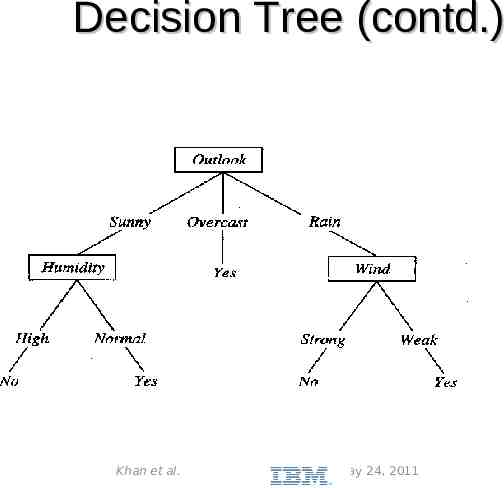
Decision Trees Decision tree is a classification model. Its basic structure is a general tree structure – Internal node: test on example’s attribute value – Leaf node: class labels Key idea: – 1) pick an attribute to test at root – 2) divide the training data into subsets Di for each value the attribute can take on – 3) build the tree for each Di and splice it in under the appropriate branch at the root Khan et al. May 24, 2011
Decision Tree (contd.) Khan et al. May 24, 2011
Decision Tree (contd.) Algorithm to build decision tree Khan et al. May 24, 2011
Decision Tree (contd.) Limitations – Classic decision tree learners assume all training data can be simultaneously stored in main memory. – Disk-based decision tree learners repeatedly read training data from disk sequentially Goal – Design decision tree learners that read each example at most once, and use a small constant time to process it. Khan et al. May 24, 2011
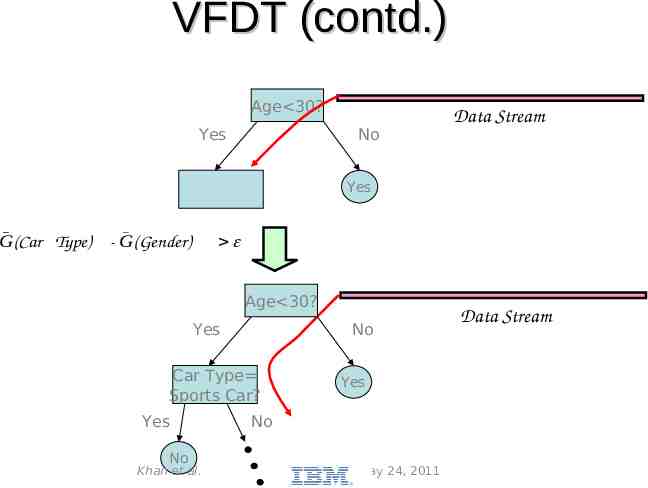
VFDT In order to find the best attribute at a node, it may be sufficient to consider only a small subset of the training examples that pass through that node. – Given a stream of examples, use the first ones to choose the root attribute. – Once the root attribute is chosen, the successive examples are passed down to the corresponding leaves, and used to choose the attribute there, and so on recursively. Use Hoeffding bound to decide how many examples are enough at each node Khan et al. May 24, 2011
VFDT (contd.) Calculate the information gain for the attributes and determines the best two attributes – Pre-pruning: consider a “null” attribute that consists of not splitting the node Gnode, G ( X a )check G ( X b )for the condition At each If condition satisfied, create child nodes based on the test at the node If not, stream in more examples and perform calculations till condition satisfied Khan et al. May 24, 2011
VFDT (contd.) Age 30? Yes No Data Stream Yes G(Car Type) - G(Gender) Age 30? Yes No Car Type Sports Car? Yes No Khan et al. Yes No May 24, 2011 Data Stream
VFDT (contd.) VFDT, assume training data is a sample drawn from stationary distribution. Most large databases or data streams violate this assumption – Concept Drift: data is generated by a timechanging concept function, e.g. Seasonal effects Economic cycles Goal: – Mining continuously changing data streams – Scale well Khan et al. May 24, 2011
VFDT (contd.) Common Approach: when a new example arrives, reapply a traditional learner to a sliding window of w most recent examples – Sensitive to window size If w is small relative to the concept shift rate, assure the availability of a model reflecting the current concept Too small w may lead to insufficient examples to learn the concept – If examples arrive at a rapid rate or the concept changes quickly, the computational cost of reapplying a learner may be prohibitively high. Khan et al. May 24, 2011
CVFDT CVFDT (Concept-adapting Very Fast Decision Tree learner) – Extend VFDT – Maintain VFDT’s speed and accuracy – Detect and respond to changes in the example-generating process Khan et al. May 24, 2011
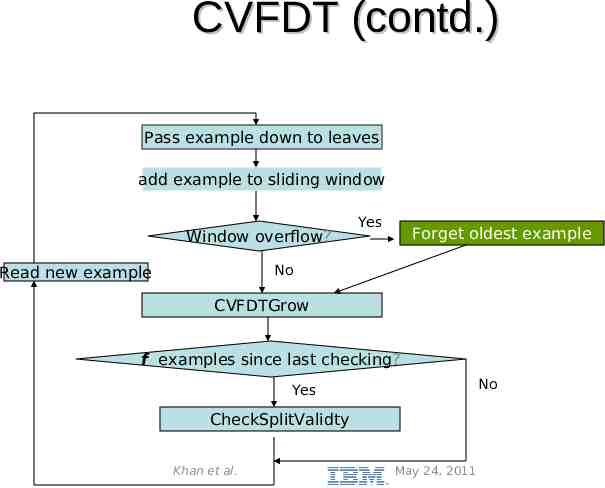
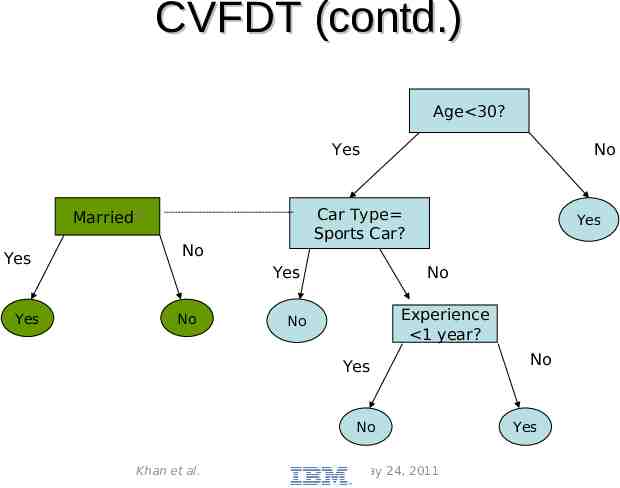
CVFDT(contd.) With a time-changing concept, the current splitting attribute of some nodes may not be the best any more. An outdated sub tree may still be better than the best single leaf, particularly if it is near the root. – Grow an alternative sub tree with the new best attribute at its root, when the old attribute seems out-of-date. Periodically use a bunch of samples to evaluate qualities of trees. – Replace the old sub tree when the alternate one becomes more accurate. Khan et al. May 24, 2011
CVFDT (contd.) Pass example down to leaves add example to sliding window Window overflow? Yes Forget oldest example No Read new example CVFDTGrow f examples since last checking? No Yes CheckSplitValidty Khan et al. May 24, 2011
CVFDT (contd.) Age 30? Yes Car Type Sports Car? Married? Yes Yes No Yes No No Yes No Experience 1 year? No Yes No Khan et al. May 24, 2011 No Yes
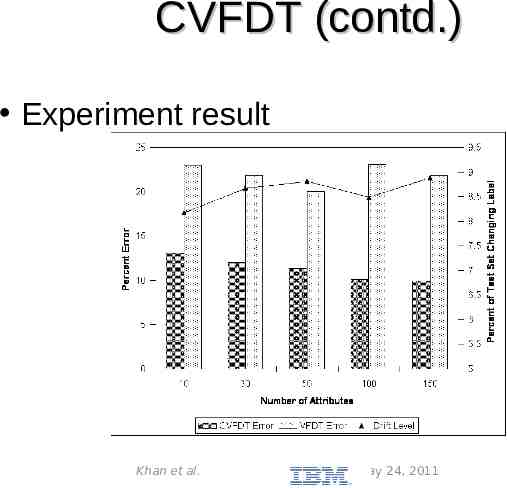
CVFDT (contd.) Experiment result Khan et al. May 24, 2011






