Carnegie Mellon Future of Computing II: What’s So Special About Big
















































49 Slides3.95 MB
Carnegie Mellon Future of Computing II: What’s So Special About Big Learning? 15-213 / 18-213 / 15-513: Introduction to Computer Systems 28th Lecture, December 5, 2017 Today’s Instructor: Phil Gibbons Bryant and O’Hallaron, Computer Systems: A Programmer’s Perspective, Third Edition 1
What’s So Special about Big Data? What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 2
Focus of this Talk: Big Learning Machine Learning over Big Data Examples: – Collaborative Filtering (via Matrix Factorization) Recommending movies – Topic Modeling (via LDA) Clusters documents into K topics – Multinomial Logistic Regression Classification for multiple discrete classes – Deep Learning neural networks: – Also: Iterative graph analytics, e.g. PageRank What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 3
Big Learning Frameworks & Systems Goal: Easy-to-use programming framework for Big Data Analytics that delivers good performance on large (and small) clusters A few popular examples (historical context): – Hadoop (2006-) – GraphLab / Dato (2009-) – Spark / Databricks (2009-) What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 4
Hadoop Hadoop Distributed File System (HDFS) Hadoop YARN resource scheduler Hadoop MapReduce Image from: developer.yahoo.com/hadoop/tutorial/module4.html Key Learning: Ease of use trumps performance Phillip B. Gibbons What’s So Special about Big Learning A Distributed Systems Perspective 5
GraphLab Graph Parallel: “Think like a vertex” Graph Based Data Representation Scheduler Update Functions User Computation Consistency Model Slide courtesy of Carlos Guestrin Key Learning: Graph Parallel is quite useful Phillip B. Gibbons What’s So Special about Big Learning A Distributed Systems Perspective 6
Triangle Counting* in Twitter Graph *How often are two of a user’s friends also friends? 40M Users 1.2B Edges Hadoop GraphLab Total: 34.8 Billion Triangles 1536 Machines 423 Minutes 64 Machines, 1024 Cores 1.5 Minutes Key Learning: Graph Parallel is'11]MUCH faster than Hadoop! Hadoop results from [Suri & Vassilvitskii
GraphLab & GraphChi How to handle high degree nodes: GAS approach Slide courtesy of Carlos Guestrin Can do fast BL on a machine w/SSD-resident data Phillip B. Gibbons What’s So Special about Big Learning A Distributed Systems Perspective 8
Spark: Key Idea Features: In-memory speed w/fault tolerance via lineage tracking Resilient Bulk Synchronous Distributed Datasets: A Fault-Tolerant Abstraction for In Memory Cluster Computing, [Zaharia et al, NSDI’12, best paper] A restricted form of shared memory, based on coarse-grained deterministic transformations rather than fine-grained updates to shared state: expressive, efficient and fault tolerant In-memory compute can be fast & fault-tolerant Phillip B. Gibbons What’s So Special about Big Learning A Distributed Systems Perspective 9
Spark’s Open Source Impact Spark Timeline Research breakthrough in 2009 First open source release in 2011 Into Apache Incubator in 2013 In all major Hadoop releases by 2014 Pipeline of research breakthroughs (publications in best conferences) fuel continued leadership & uptake Start-up (Databricks), Open Source Developers, and Industry partners (IBM, Intel) make code commercial-grade Fast path for Academics impact via Open Source: Pipeline of research breakthroughs into widespread commercial use in 2 years!
Big Learning Frameworks & Systems Goal: Easy-to-use programming framework for Big Data Analytics that delivers good performance on large (and small) clusters A few popular examples (historical context): – Hadoop (2006-) – GraphLab / Dato (2009-) – Spark / Databricks (2009-) Our Idea: Discover & take advantage of distinctive properties (“what’s so special”) of Big Learning training algorithms What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 11
What’s So Special about Big Learning? A Mathematical Perspective Formulated as an optimization problem – Use training data to learn model parameters that minimize/maximize an objective function No closed-form solution, instead algorithms iterate until convergence – E.g., Stochastic Gradient Descent Image from charlesfranzen.com What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 12
Recall: Training DNNs Model Size 20 18 16 14 12 10 8 6 4 2 0 0 5 10 15 20 Training Data 20 18 16 14 12 10 8 6 4 2 0 350 300 250 150 50 0 0 5 Iterative numerical algorithm Regular data organization – 13 – 200 100 Characteristics Training Effort 400 10 15 20 0 5 10 15 Project Adam Training 2B connections 15M images 62 machines 10 days 20
What’s So Special about Big Learning? A Distributed Systems Perspective The Bad News Lots of Computation / Memory – Many iterations over Big Data – Big Models Need to distribute computation widely Lots of Communication / Synchronization – Not readily “partitionable” Model Training is SLOW – hours to days to weeks, even on many machines why good distributed systems research is What’s So Special about Big Learning A Distributed Systems Perspective needed! Phillip B. Gibbons 14
Big Models, Widely Distributed [Li et al, OSDI’14] What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 15
Lots of Communication / Synchronization e.g. in BSP Execution (Hadoop, Spark) P1 P2 P3 P4 P5 Exchange ALL updates at END of each iteration Frequent, bursty communication Compute Communicate Compute Communicate Compute Communicate Synchronize ALL threads each iteration Straggler problem: stuck waiting for slowest What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 16
What’s So Special about Big Learning? A Distributed Systems Perspective The Good News 1. Commutative/Associative parameter updates 2. Tolerance for lazy consistency of parameters 3. Repeated parameter data access pattern 4. Intra-iteration progress measure 5. Parameter update importance hints 6. Layer-by-layer pattern of deep learning 7. Most parameter updates are insignificant can exploit to run orders of magnitude faster! What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 17
Parameter Servers for Distributed ML Provides all workers with convenient access to global model parameters – “Distributed shared memory” programming style Worker 1 Worker 2 Parameter Table (sharded across machines) Worker 3 Worker 4 UpdateVar(i) { Single old y[i] Machine delta f(old) Parallel y[i] delta } UpdateVar(i) { Distributed old PS.read(y,i) delta f(old) with PS PS.inc(y,i,delta) } ower & Li, OSDI’10], [Ahmed et al, WSDM’12], [NIPS’13], [Li et al, OSDI’14], Petuum, MXNet, TensorFlow, etc What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 18
Problem: Cost of Bulk Synchrony 1 Thread 1 Thread 2 1 Thread 3 1 Thread 4 1 2 3 2 3 2 2 3 3 Time Exchange ALL updates at END of each iteration Synchronize ALL threads each iteration Bulk Synchrony Frequent, bursty communication & stuck waiting for stragglers But: Fully asynchronous No algorithm convergence guarantees What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 19
Stale Synchronous Parallel (SSP) Staleness Bound S 3 Thread 1 waits until Thread 2 has reached iter 4 Thread 1 Thread 2 Thread 1 will always see these updates Thread 3 Thread 1 may not see these updates Thread 4 0 1 2 3 4 5 6 7 8 9 Iteration Fastest/slowest threads not allowed to drift S iterations apart Allow threads to usually run at own pace Protocol: check cache first; if too old, get latest version from network Choice of S: Staleness “sweet spot” Exploits: 1. commutative/associative updates & 2. tolerance for lazy consistency (bounded staleness) What’s So Special about Big Learning A Distributed Systems Perspective [NIPS’13] [ATC’14] Phillip B. Gibbons 20
Staleness Sweet Spot Topic Modeling Nytimes dataset 400k documents 100 topics LDA w/Gibbs sampling 8 machines x 64 cores 40Gbps Infiniband What’s So Special about Big Learning A Distributed Systems Perspective [ATC’14] Phillip B. Gibbons 21
What’s So Special about Big Learning? A Distributed Systems Perspective The Good News 1. Commutative/Associative parameter updates 2. Tolerance for lazy consistency of parameters 3. Repeated parameter data access pattern 4. Intra-iteration progress measure 5. Parameter update importance hints 6. Layer-by-layer pattern of deep learning 7. Most parameter updates are insignificant can exploit to run orders of magnitude faster! What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 22
Repeated Data Access in PageRank Input data: a set of links, stored locally in workers Parameter data: ranks of pages, stored in PS Page0 k-0 -1 k Lin Page1 Worker-0 Link-3 Link-2 Lin Page2 Init ranks to random value loop foreach link from i to j { read Rank(i) update Rank(j) } while not converged Worker-1 What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 23
Repeated Data Access in PageRank Input data: a set of links, stored locally in workers Parameter data: ranks of pages, stored in PS Worker-0 Page0 k-0 -1 k Lin Page1 Worker-0 Link-3 Link-2 Lin Page2 loop # Link-0 read page[2].rank update page[0].rank # Link-1 read page[1].rank update page[2].rank clock() while not converged Worker-1 Repeated access sequence depends only on about input dataDistributed (notSystems on parameter values) What’s So Special Big Learning A Perspective Phillip B. Gibbons 24
Exploiting Repeated Data Access Collect access sequence in “virtual iteration” Enables many optimizations: 1. Parameter data placement across machines Machine-0 Machine-1 ML Worker ML Worker PS shard PS shard What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 25
Exploiting Repeated Data Access Collect access sequence in “virtual iteration” Enables many optimizations: 1. Parameter data placement across machines 2. Prefetching 3. Static cache policies 4. More efficient marshalling-free data structures 5. NUMA-aware memory placement Benefits are resilient to moderate deviation in an iteration’s actual access pattern What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 26
IterStore: Exploiting Iterativeness 4 iterations [SoCC’14] Collaborative Filtering (Matrix Factorization) NetFlix data set 8 machines x 64 cores 40 Gbps Infiniband 99 iterations 4-5x faster than baseline 11x faster than GraphLab What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 27
What’s So Special about Big Learning? A Distributed Systems Perspective The Good News 1. Commutative/Associative parameter updates 2. Tolerance for lazy consistency of parameters 3. Repeated parameter data access pattern 4. Intra-iteration progress measure 5. Parameter update importance hints 6. Layer-by-layer pattern of deep learning 7. Most parameter updates are insignificant can exploit to run orders of magnitude faster! What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 28
Addressing the Straggler Problem Many sources of transient straggler effects – Resource contention – System processes (e.g., garbage collection) – Slow mini-batch at a worker Causes significant slowdowns for Big Learning FlexRR: SSP Low-overhead work migration (RR) to mitigate transient straggler effects – Simple: Tailored to Big Learning’s special properties E.g., cloning (used in MapReduce) would break the algorithm (violates idempotency)! – Staleness provides slack to do the migration What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 29
Rapid-Reassignment (RR) Protocol Multicast to preset possible helpees (has copy of tail of helpee’s input data) Intra-iteration progress measure: percentage of input data processed Ok Ignore (I don’t need help) Fast I’m this far Slow I’m this fa r Do assignment #1 (red work I’m behind (I need help) Started Work ing Do assignment #2 en work) (g Care nc e l Can process input data in any order Assignment is percentage What’s So Special about Big Learning A Distributed Systems Perspective range Phillip B. Gibbons 30
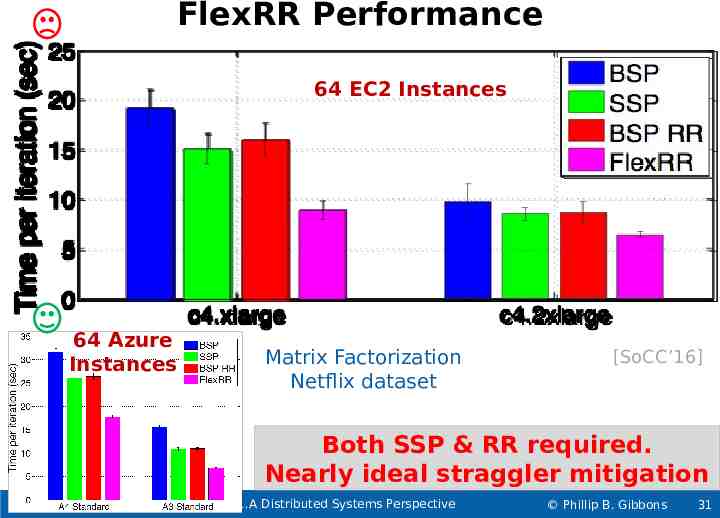
FlexRR Performance 64 EC2 Instances 64 Azure Instances Matrix Factorization Netflix dataset [SoCC’16] Both SSP & RR required. Nearly ideal straggler mitigation What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 31
What’s So Special about Big Learning? A Distributed Systems Perspective The Good News 1. Commutative/Associative parameter updates 2. Tolerance for lazy consistency of parameters 3. Repeated parameter data access pattern 4. Intra-iteration progress measure 5. Parameter update importance hints 6. Layer-by-layer pattern of deep learning 7. Most parameter updates are insignificant can exploit to run orders of magnitude faster! What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 33
Bosen: Managed Communication Combine SSP’s lazy transmission of parameter updates with: – early transmission of larger parameter changes (Idea: larger change likely to be an important update) – up to bandwidth limit & staleness limit LDA Topic Modeling Nytimes dataset 16x8 cores [SoCC’15] What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 34
What’s So Special about Big Learning? A Distributed Systems Perspective The Good News 1. Commutative/Associative parameter updates 2. Tolerance for lazy consistency of parameters 3. Repeated parameter data access pattern 4. Intra-iteration progress measure 5. Parameter update importance hints 6. Layer-by-layer pattern of deep learning 7. Most parameter updates are insignificant can exploit to run orders of magnitude faster! What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 35
Recall: Data Analysis with Deep Neural Networks Task: Compute classification of set of input signals Training Use many training samples of form input / desired output Compute weights that minimize classification error Operation – 36 – Propagate signals from input to output
Distributed Deep Learning Parameter server for GPUs Eagle Vulture read, update Osprey Accipiter Partitioned training data Distributed ML workers What’s So Special about Big Learning A Distributed Systems Perspective Shared model parameters Phillip B. Gibbons 37
Layer-by-Layer Pattern of DNN Class probabilities For each iteration (mini-batch) – A forward pass – Then a backward pass Pairs of layers used at a time Training images What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 38
GeePS: Parameter Server for GPUs Careful management of GPU & CPU memory – Use GPU memory as cache to hold pairs of layers – Stage remaining data in larger CPU memory ImageNet22K Adam model [EuroSys’16] GeePS is 13x faster than Caffe (1 GPU) on 16 machines, 2.6x faster than IterStore (CPU parameter server) What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 39
What’s So Special about Big Learning? A Distributed Systems Perspective The Good News 1. Commutative/Associative parameter updates 2. Tolerance for lazy consistency of parameters 3. Repeated parameter data access pattern 4. Intra-iteration progress measure 5. Parameter update importance hints 6. Layer-by-layer pattern of deep learning 7. Most parameter updates are insignificant can exploit to run orders of magnitude faster! What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 40
Geo-Distributed Machine Learning Data sources are everywhere (geo-distributed) – Too expensive (or not permitted) to ship all data to single data center What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 41
Gaia System Overview Key idea: Decouple the synchronization model within the data center from the synchronization model between data centers Data Center 2 Data Center 1 Worker Parameter Machine Server Worker Parameter Machine Server Worker Machine Local Sync Remote Sync Parameter Server Parameter Server Eliminate insignificant updates over WANs Approximately Correct Model Copy Approximately Correct Model Copy [NSDI’17] 42
Performance – 11 EC2 Data Centers Normalized Exec. Time Baseline 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0.26 0.27 Matrix Factorization Gaia 0.27 LAN 0.21 Topic Modeling 6.0X 0.12 Image Classification Gaia achieves 3.7-6.0X speedup over Baseline Gaia is within 1.40X of LAN speeds Also: Gaia is 2.6-8.5X cheaper than Baseline Baseline: IterStore for CPUs, GeePS for GPUs What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 43
What’s So Special about Big Learning? A Distributed Systems Perspective The Good News 1. Commutative/Associative parameter updates 2. Tolerance for lazy consistency of parameters 3. Repeated parameter data access pattern 4. Intra-iteration progress measure 5. Parameter update importance hints 6. Layer-by-layer pattern of deep learning 7. Most parameter updates are insignificant can exploit to run orders of magnitude faster! What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 44
Proteus: Playing the Spot Market Spot Instances are often 85%-90% cheaper, but can be taken away at short notice Different machine types have uncorrelated spikes [EuroSys’17] Proteus uses agile tiers of reliability aggressive bidding for cheap (free) compute What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 45
What’s So Special about Big Learning? A Distributed Systems Perspective The Good News 1. Commutative/Associative parameter updates 2. Tolerance for lazy consistency of parameters 3. Repeated parameter data access pattern 4. Intra-iteration progress measure 5. Parameter update importance hints 6. Layer-by-layer pattern of deep learning 7. Most parameter updates are insignificant can exploit to run orders of magnitude faster! What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 46
Thanks to Collaborators & Sponsors CMU Faculty: Greg Ganger, Garth Gibson, Eric Xing CMU/ex-CMU Students: James Cipar, Henggang Cui, Wei Dai, Jesse Haber-Kucharsky, Aaron Harlap, Qirong Ho, Kevin Hsieh, Jin Kyu Kim, Dimitris Konomis, Abhimanu Kumar, Seunghak Lee, Aurick Qiao, Alexey Tumanov, Nandita Vijaykumar, Jinliang Wei, Lianghong Xu, Hao Zhang (Bold first author) Sponsors: – PDL Consortium: Avago, Citadel, EMC, Facebook, Google, Hewlett-Packard Labs, Hitachi, Intel, Microsoft Research, MongoDB, NetApp, Oracle, Samsung, Seagate, Symantec, Two Sigma, Western Digital – Intel (via ISTC for Cloud Computing & ISTC for Visual Cloud Systems) – National Science Foundation (Many of these slides adapted from slides by the students) What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 47
References (in order of first appearance) [Zaharia et al, NSDI’12] M. Zaharia, M. Chowdhury, T. Das, A. Dave, J. Ma, M. McCauly, M. J. Franklin, S. Shenker, and I. Stoica. Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In -Memory Cluster Computing. Usenix NSDI, 2012. [Li et al, OSDI’14] M. Li, D. G. Anderson, J. W. Park, A. J. Smola, A. Ahmed, V. Josifovski, J. Long, E. J. Shekita, and B.-Y. Su. Scaling distributed machine learning with the parameter server. Usenix OSDI, 2014. [Power & Li, OSDI’10] R. Power and J. Li. Piccolo: Building Fast, Distributed Programs with Partitioned Tables. Usenix OSDI, 2010. [Ahmed et al, WSDM’12] A. Ahmed, M. Aly, J. Gonzalez, S. M. Narayanamurthy, and A. J. Smola. Scalable inference in latent variable models. ACM WSDM, 2012. [NIPS’13] Q. Ho, J. Cipar, H. Cui, S. Lee, J. K. Kim, P. B. Gibbons, G. Gibson, G. Ganger, and E. Xing. More effective distributed ML via a state synchronous parallel parameter server. NIPS, 2013. [Petuum] petuum.org [MXNet] T. Chen, M. Li, Y. Li, M. Lin, N. Wang, M. Wang, T. Xiao, B. Xu, C. Zhang, and Z. Zhang. MXNet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv:1512.01274, 2015. [TensorFlow] tensorflow.org [ATC’14] H. Cui, J. Cipar, Q. Ho, J. K. Kim, S. Lee, A. Kumar, J. Wei, W. Dai, G. R. Ganger, P. B. Gibbons, G. A. Gibson, and E. P. Xing. Exploiting Bounded Staleness to Speed Up Big Data Analytics. Usenix ATC, 2014. [SoCC’14] H. Cui, A. Tumanov, J. Wei, L. Xu, W. Dai, J. Haber-Kucharsky, Q. Ho, G. R. Ganger, P. B. Gibbons, G. A. Gibson, and E. P. Xing. Exploiting iterative-ness for parallel ML computations. ACM SoCC, 2014. [SoCC’16] A. Harlap, H. Cui, W. Dai, J. Wei, G. R. Ganger, P. B. Gibbons, G. A. Gibson, and E. P. Xing. Addressing the straggler problem for iterative convergent parallel ML. ACM SoCC, 2016. What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 48
References (cont.) [SoCC’15] J. Wei, W. Dai, A. Qiao, Q. Ho, H. Cui, G. R. Ganger, P. B. Gibbons, G. A. Gibson, and E. P. Xing. Managed Communication and Consistency for Fast Data-Parallel Iterative Analytics. ACM SoCC, 2015. [EuroSys’16] H. Cui, H. Zhang, G. R. Ganger, P. B. Gibbons, E. P. Xing. GeePS: Scalable deep learning on distributed GPUs with a GPUspecialized parameter server. EuroSys, 2016. [NSDI’17] K. Hsieh, A. Harlap, N. Vijaykumar, D. Konomis, G. R. Ganger, P. B. Gibbons, and O. Mutlu. Gaia: Geo-Distributed Machine Learning Approaching LAN Speeds. NSDI, 2017. [EuroSys’17] A. Harlap, A. Tumanov, A. Chung, G. R. Ganger, and P. B. Gibbons. Proteus: agile ML elasticity through tiered reliability in dynamic resource markets. ACM EuroSys, 2017. What’s So Special about Big Learning A Distributed Systems Perspective Phillip B. Gibbons 49
Carnegie Mellon Thanks for a Great Semester! Good Luck on the Final! Bryant and O’Hallaron, Computer Systems: A Programmer’s Perspective, Third Edition 50