Starting Data Science With Kaggle 6/25/2017 Nathaniel Shimoni Starting























30 Slides893.14 KB
Starting Data Science With Kaggle.com 6/25/2017 Nathaniel Shimoni Starting Data Science with Kaggle.com Nathaniel Shimoni 25/6/2017 1
Talk outline What is Kaggle? Why is Kaggle so great? The everyone wins approach Kaggle tiers & top kagglers Frequently used terms and the main rules The benefits of starting with Kaggle Common Kaggle data science process Kaggle disadvantages 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 2
What is kaggle? An online platform that runs data science competitions Declares itself to be the home of data science Has over 1M registered users & over 60k active users One of the most vibrant communities for data scientists A great place to meet other “data people” A great place to learn and test your data & modeling skills 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 3
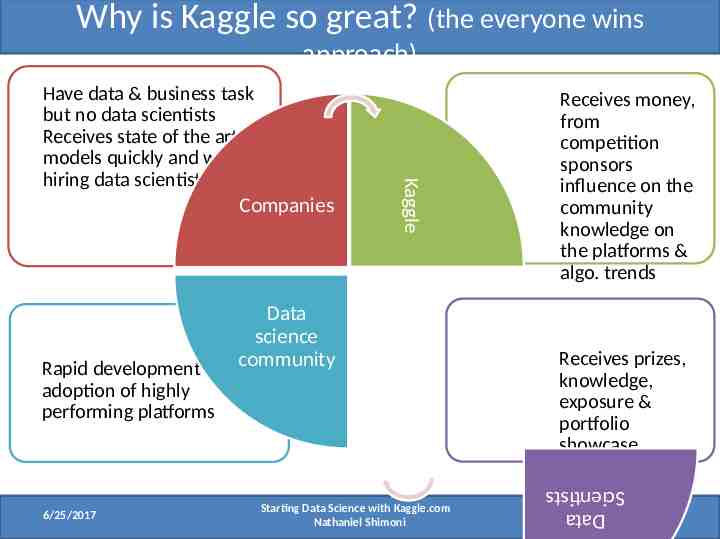
Why is Kaggle so great? (the everyone wins approach) Data science Rapid development & community adoption of highly performing platforms 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni Receives money, from competition sponsors influence on the community knowledge on the platforms & algo. trends Receives prizes, knowledge, exposure & portfolio showcase Data Scientists Kaggle Have data & business task but no data scientists Receives state of the art models quickly and without hiring data scientists Companies 4
My Kaggle profile 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 5
Kaggle tiers Novice – a new Kaggle user Contributor – participated in one or more competitions, ran a kernel, and is active in the forums Expert – 2 top 25% finishes Master - 2 top 10% finishes, & 1 top 10 (places) finish Grandmaster – 5 top 10 finishes & 1 solo top 10 finish 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 6
Top Kagglers 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 7
Frequently used terms Leaderboard (public & private) Training data Training Available once approved the rules Testing data Public LB Private LB Used for ranking submissions through the competition Used for final scoring (the only score that truly matters) Public LB can serve as additional validation frame, but can also be source of over fitting 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 8
Frequently used terms Leakage - the introduction of information about the target that is not a legitimate predictor (usually by a mistake within the data preparation process) Team merger – 2 or more participants competing together 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 9
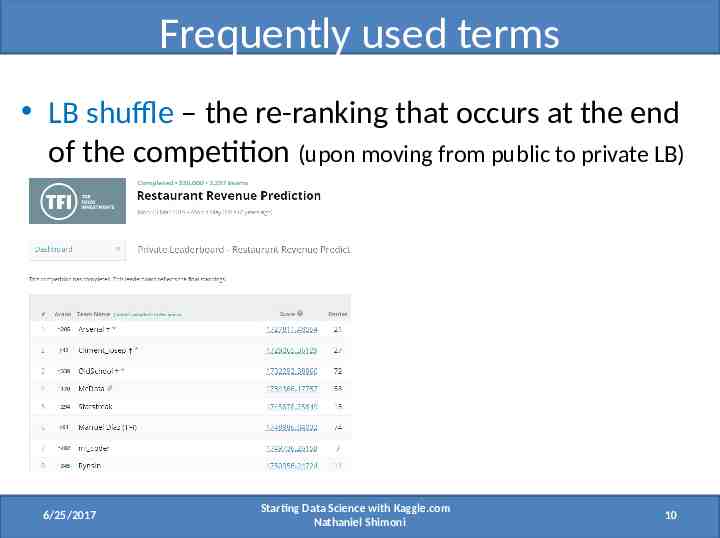
Frequently used terms LB shuffle – the re-ranking that occurs at the end of the competition (upon moving from public to private LB) 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 10
Main rules for Kaggle competitions One account per user No private sharing outside teams (public sharing is usually allowed and endorsed) Limited number of entries per day & per competition Winning solutions must be written in open source code Winners should hand well documented source code in order to be eligible of the price Usually select 2 solutions for final evaluation 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 11
Why start with Kaggle? Project based learning – learn by doing Solve real world challenges Great supporting community Benchmark solutions & shared code samples Clear business objective and modeling task Develop work portfolio and rank yourself against other competitors (and get recognition) Compete against state of the art solutions Learn (a lot!!!) when competition ends 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 12
Why start with Kaggle? Ability to team-up with others: learn from better Kagglers learn how to collaborate effectively merge different solutions to achieve a score boost meet new exciting people Answer the questions of others – you only truly learn something when you teach it to someone else Ability to apply new ideas at work with little effort Varied areas of activity (verticals) 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 13
Why start with Kaggle? The ability to follow many experts where each of them specializes in a particular area (sample from my list) Ensemble learning Mathias Müller Feature extraction Darius Barušauskas Super fast draft modeling ZFTurbo - unknown 6/25/2017 Validation Gert Jacobusse Inspiration – no minimal age for data science Mikel Bober-Irizar Starting Data Science with Kaggle.com Nathaniel Shimoni 14
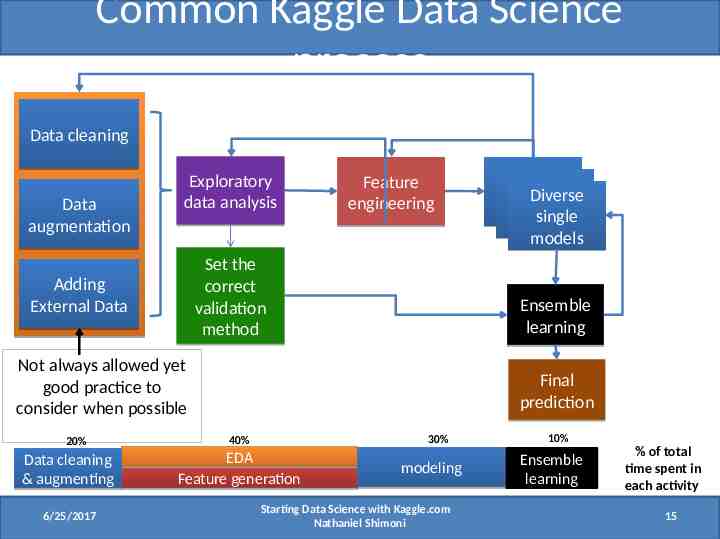
Common Kaggle Data Science process Data cleaning Data augmentation Exploratory data analysis Feature engineering Set the correct validation method Adding External Data Ensemble learning Not always allowed yet good practice to consider when possible 20% Data cleaning & augmenting 6/25/2017 Single Single Diverse models models single models Final prediction 30% 40% EDA Feature generation modeling Starting Data Science with Kaggle.com Nathaniel Shimoni 10% Ensemble learning % of total time spent in each activity 15
Data cleaning Impute missing values (mean, median, most common value, use separate prediction task) Remove zero variance features Remove duplicated features Outlier removal – caution can be harmful, at cleaning stage we’ll remove irrelevant values (e.g. negative price) Na’s encoding / imputing 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 16
Data augmentation & external data External data sources: open street map weather measurement data online calendars API’s Scraping (using ScraPy / beautiful soup) 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 17
Feature engineering Rescaling/ standardization of existing features Performing data transformations: Tf-Idf, log1p, min-max scaling, binning of numeric features Turn categorical features to numeric (label encoding / one hot encoding) Create count features Parsing textual features to get more generalizable features Hashing trick Extracting date/time features i.e DayOfWeek, month, year, dayOfMonth, isHoliday etc. 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 18
Feature selection Remove near-zero-variance features Use feature importance and eliminate least important features Recursive Feature Elimination 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 19
Hyper parameter optimization Grid search CV (exhaustive, rarely better than alternatives) Random search CV Hyper-opt Bayesian optimization * Hyper parameter adjustment will usually yield better results but not as much as other activities 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 20
Validation Train test split Shuffle split Kfold is the most commonly used Time based separation Group Kfold Leave one group out 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 21
Ensemble learning Simple/weighted average of previous best models Bagging of same type of models (i.e different rng, different hyper-param) Majority vote Using out of fold predictions as meta features a.k.a stacking 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 22
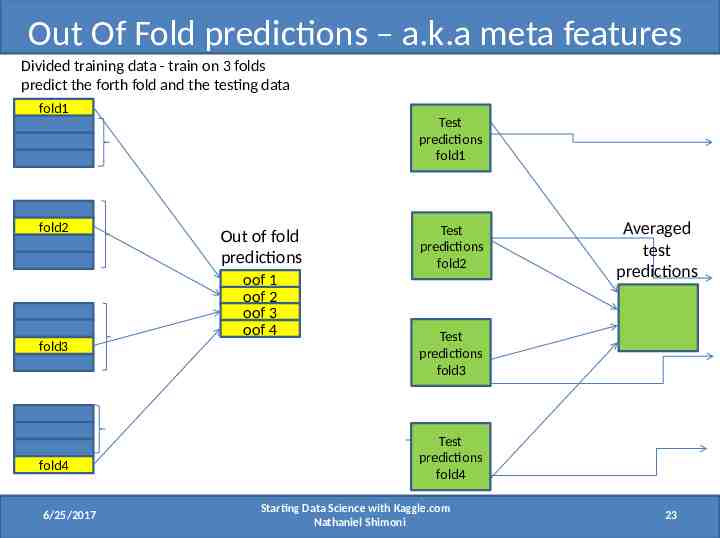
Out Of Fold predictions – a.k.a meta features Divided training data - train on 3 folds predict the forth fold and the testing data fold1 fold2 Test predictions fold1 Out of fold predictions oof 1 oof 2 oof 3 oof 4 fold3 fold4 6/25/2017 Test predictions fold2 Averaged test predictions Test predictions fold3 Test predictions fold4 Starting Data Science with Kaggle.com Nathaniel Shimoni 23
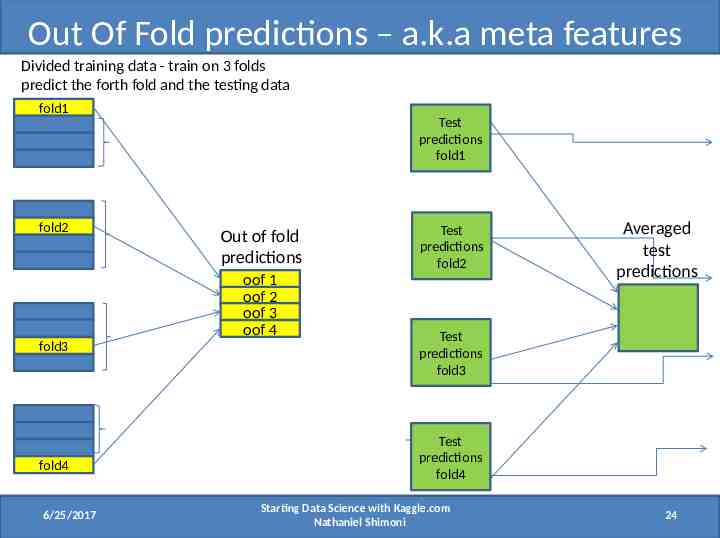
Out Of Fold predictions – a.k.a meta features Divided training data - train on 3 folds predict the forth fold and the testing data fold1 fold2 Test predictions fold1 Out of fold predictions oof 1 oof 2 oof 3 oof 4 fold3 fold4 6/25/2017 Test predictions fold2 Averaged test predictions Test predictions fold3 Test predictions fold4 Starting Data Science with Kaggle.com Nathaniel Shimoni 24
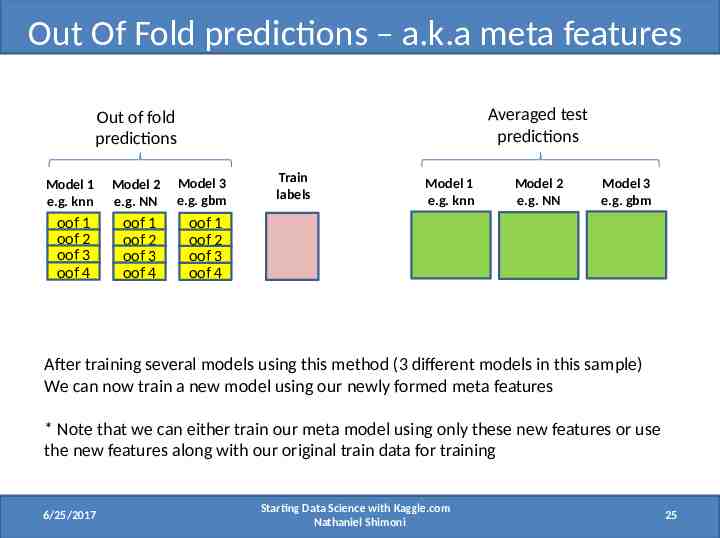
Out Of Fold predictions – a.k.a meta features Averaged test predictions Out of fold predictions Model 1 e.g. knn Model 2 e.g. NN Model 3 e.g. gbm oof 1 oof 2 oof 3 oof 4 oof 1 oof 2 oof 3 oof 4 oof 1 oof 2 oof 3 oof 4 Train labels Model 1 e.g. knn Model 2 e.g. NN Model 3 e.g. gbm After training several models using this method (3 different models in this sample) We can now train a new model using our newly formed meta features * Note that we can either train our meta model using only these new features or use the new features along with our original train data for training 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 25
Disadvantages of Kaggle Large focus on modeling relatively to the rest of the steps in the process Small weight to runtime and scalability Little reasoning for selecting a specific eval metric Competing for the last few percent points isn’t always valuable “Click and submit” phenomena 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 26
Additional reading resources MOOC’s: Machine learning – Stanford Coursera Data science track – Johns Hopkins Coursera Udacity deep learning course Documentation: Scikit learn documentation Keras documentation R caret package documentation 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 27
Links to sources This presentation draws heavily from the following sources: Mark Peng’s presentation “Tips for participating Kaggle challenges” Darius Barušauskas’s presentation “Tips and tricks to win Kaggle data science competitions” Kaggle discussion forums and blog 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 28
Questions? 6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 29
6/25/2017 Starting Data Science with Kaggle.com Nathaniel Shimoni 30