MapReduce Types , Formats , and Features 1



















22 Slides657.82 KB
MapReduce Types , Formats , and Features 1
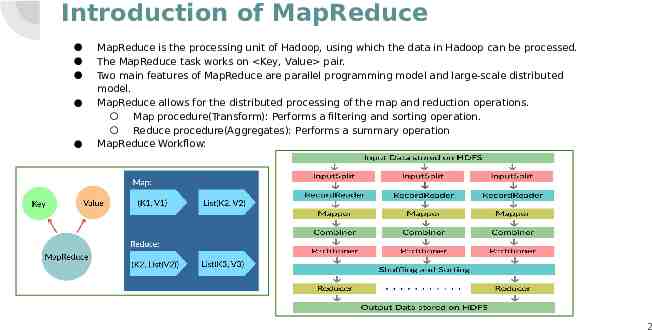
Introduction of MapReduce MapReduce is the processing unit of Hadoop, using which the data in Hadoop can be processed. The MapReduce task works on Key, Value pair. Two main features of MapReduce are parallel programming model and large-scale distributed model. MapReduce allows for the distributed processing of the map and reduction operations. Map procedure(Transform): Performs a filtering and sorting operation. Reduce procedure(Aggregates): Performs a summary operation MapReduce Workflow: 2
MapReduce Functions MapReduce is a programming framework that allows us to perform distributed and parallel processing on large data sets. A MapReduce consists of the following procedures. Map: Block of data is read and processed to produce keyvalue pairs as intermediate outputs. The output of a Mapper or map job (key-value pairs) is input to the Reducer. 3
Reduce: The reducer receives the key-value pair from multiple map jobs. Then, the reducer aggregates those intermediate data tuples (intermediate key-value pair) into a smaller set of tuples or key-value pairs which is the final output. 4
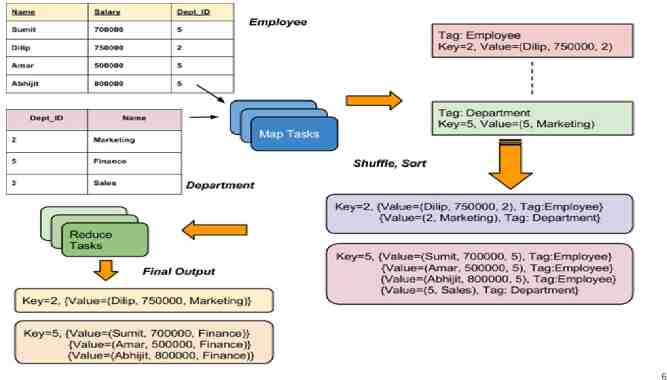
MAPREDUCE FEATURES: Joins This feature of MapReduce would allow to join large datasets which involves a lot of programmatic implementation. Types of Joins: 1. Map-side join 2. Reduced-side join. In Joins we basically look at the size of the datasets and decide to perform lookup for matching records. 5
6
Counters This feature of MapReduce is used to keep track of the events happening. These counters keep a track of job statistics like the number of rows read or the number of rows written etc. MapReduce has default counters and we can also customize counters when needed. Built-in Counters are Mapreduce Task Counters File system counters Job Counters 7
Side Data Distribution: It can be defined as extra read only data needed by job to process the main dataset. Challenge is to make side data available to all the map or reduce tasks in convenient and efficient fashion. Different types: Using the Job Configuration Distributed Cache MapReduce Library Classes 8
INPUT FORMATS InputFormat describes the input-specification for execution of the Map-Reduce job. In MapReduce job execution, InputFormat is the first step. InputFormat describes how to split and read input files. InputFormat is responsible for splitting the input data file into records which is used for map-reduce operation. InputFormat selects the files or other objects for input. It defines the Data splits. It defines both the size of individual Map tasks and its potential execution server. InputFormat defines the RecordReader. It is also responsible for reading actual records from the input files. 9
TYPES OF INPUT FORMAT 1. FileInputFormat: It is the base class for all file-based InputFormats. When we start a MapReduce job execution, FileInputFormat provides a path containing files to read. This InputFormat will read all files and divides these files into one or more InputSplits. 2. TextInputFormat: It is the default InputFormat. This InputFormat treats each line of each input file as a separate record. It performs no parsing. TextInputFormat is useful for unformatted data or line-based records like log files. 3. KeyValueTextInputFormat: It is similar to TextInputFormat. This InputFormat also treats each line of input as a separate record. While the difference is that TextInputFormat treats entire line as the value, but the KeyValueTextInputFormat breaks the line itself into key and value 10
TYPES OF INPUT FORMAT 4. SequenceFileInputFormat: It is an InputFormat which reads sequence files. Sequence files are binary files. These files also store sequences of binary key-value pairs. These are block-compressed and provide direct serialization and deserialization of several arbitrary data. 5. N-lineInputFormat: It is another form of TextInputFormat where the keys are byte offset of the line. And values are contents of the line. So, each mapper receives a variable number of lines of input with TextInputFormat and KeyValueTextInputFormat. So, if want our mapper to receive a fixed number of lines of input, then we use NLineInputFormat. 6. DBInputFormat: This InputFormat reads data from a relational database, using JDBC. It also loads small datasets, perhaps for joining with large datasets from HDFS using MultipleInputs. 11
OUTPUT FORMATS The outputFormat decides the way the output key-value pairs are written in the output files by RecordWriter. The OutputFormat and InputFormat functions are similar. OutputFormat instances are used to write to files on the local disk or in HDFS. In MapReduce job execution on the basis of output specification; Hadoop MapReduce job checks that the output directory does not already present. OutputFormat in MapReduce job provides the RecordWriter implementation to be used to write the output files of the job. Then the output files are stored in a FileSystem. 12
TYPES OF OUTPUT FORMAT 1. TextOutputFormat: The default OutputFormat is TextOutputFormat. It writes (key, value) pairs on individual lines of text files. Its keys and values can be of any type. The reason behind is that TextOutputFormat turns them to string by calling toString() on them. It separates key-value pair by a tab character. By using MapReduce.output.textoutputformat.separator property we can also change it. 2. SequenceFileOutputFormat: This OutputFormat writes sequences files for its output. SequenceFileInputFormat is also intermediate format use between MapReduce jobs. It serializes arbitrary data types to the file. And the corresponding SequenceFileInputFormat will deserialize the file into the same types. It presents the data to the next mapper in the same manner as it was emitted by the previous reducer. Static methods also control the compression. 3. SequenceFileAsBinaryOutputFormat: It is another variant of SequenceFileInputFormat. It also writes keys and values to sequence file in binary format. 13
TYPES OF OUTPUT FORMAT 4. MapFileOutputFormat: It is another form of FileOutputFormat. It also writes output as map files. The framework adds a key in a MapFile in order. So we need to ensure that reducer emits keys in sorted order. 5. MultipleOutputs: This format allows writing data to files whose names are derived from the output keys and values. 6. LazyOutputFormat: In MapReduce job execution, FileOutputFormat sometimes create output files, even if they are empty. LazyOutputFormat is also a wrapper OutputFormat. 7. DBOutputFormat: It is the OutputFormat for writing to relational databases and HBase. This format also sends the reduce output to a SQL table. It also accepts key-value pairs. In this, the key has a type extending DBwritable. 14
COUNTERS Counters in Hadoop are a useful channel for gathering statistics about the MapReduce job. Counters are also useful for problem diagnosis. Hadoop Counters validate that: It reads and written correct number of bytes. It has launched and successfully run correct number of tasks or not. Counters also validate that the amount of CPU and memory consumed is appropriate for our job and cluster nodes or not. Counter also measures the progress or the number of operations that occur within MapReduce job. Hadoop also maintains built-in counters and userdefined counters to measure the progress that occurs within MapReduce job. 15
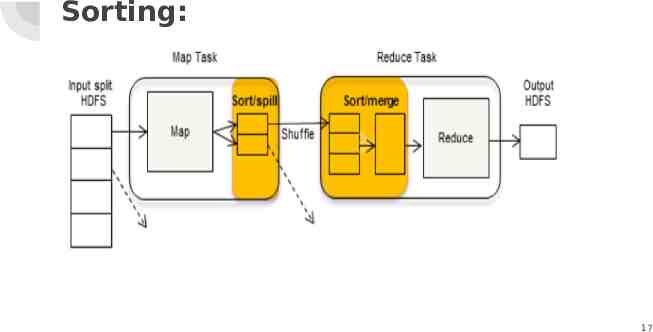
Sorting MapReduce Framework automatically sort the keys generated by the mapper. Reducer in MapReduce starts a new reduce task when the next key in the sorted input data is different than the previous. Each reduce task takes key value pairs as input and generates key-value pair as output. Secondary Sorting in MapReduce: If we want to sort reducer values, then we use a secondary sorting technique. This technique enables us to sort the values (in ascending or descending 16
Sorting: 17
Question The process of taking key-value as input, sorting it and transferring to reducer is known as? 18
Joins It is possible to combine two large sets of data in MapReduce, that is, by using Joins. While using Joins, a common key is used to merge the large data sets. There are two types of joins Map side join Reduce side join 19
Map-side Join vs Reduce-side Join Data should be partitioned Reduce-Side joins since the and sorted in particular way. input datasets need not to Each input data should be be structured. But it is less efficient as divided in same number of partition. both datasets have to go Must be sorted with same key. through the MapReduce All the records for a particular shuffle phase. The records with the same key must reside in the same partition. key are brought together in the reducer. 20
Advantages of MapReduce: Supports Unstructured data- It has one special advantage that it supports unstructured which is not supported by other technologies. Memory Requirements - MapReduce does not require much memory compared to other Hadoop ecosystems. It runs at a minimal amount of memory and produces fast results. Cost Reduction - Because MapReduce is highly scalable, it reduces storage and processing costs to meet growing data requirements. Parallel nature: One of MapReduce main strengths is that it has a parallel nature. It is better to work with structured and unstructured data at the same time. Scalability: The biggest advantage of MapReduce is the level of scalability, which is very high and can reach thousands of nodes. Fault Tolerance: Due to its distributed nature, MapReduce is highly fail-safe. Typically, MapReduce-supported distributed file systems, along with the basic process, provide MapReduce jobs to overcome hardware problems. 21
The End - Thank You 22